python爬虫4:requests库-案例2
python爬虫4:requests库-案例2
前言
python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。
申明
本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好影响。
目录结构
文章目录
-
- python爬虫4:requests库-案例2
-
- 1. 目标
- 2. 详细流程
-
- 2.1 确定目标
- 2.2 代码
- 3. 总结
1. 目标
本次案例的主要目标是帮助大家熟悉requests库中的post请求和其参数使用技巧。
再次说明,案例本身并不重要,重要的是如何去使用和分析,另外为了避免侵权之类的问题,我不会放涉及到网站的图片,希望能理解。
2. 详细流程
2.1 确定目标
我们知道post请求一般用于表单填写,常见的场景比如登录每个网站。那么,这里我们就用网上最常见的豆瓣登录网页来作为测试。
确定传入参数
那么,首先肯定是打开豆瓣网站并找到登录页面,这个相信大家都能找到。其次,你会发现豆瓣默认是手机号登录的,但是这不是我们需要的,我们还是切换到密码登录。
那么,**难点来了,你如何去确定登录表单的参数名字,是username + password,还是xxxx + xxx?**这一点,我来告诉大家如何确定:(Google浏览器为例)
首先,鼠标停留在账号的输入框上,点击鼠标右键选择检查,你会进入网页源码中,接着看下图:
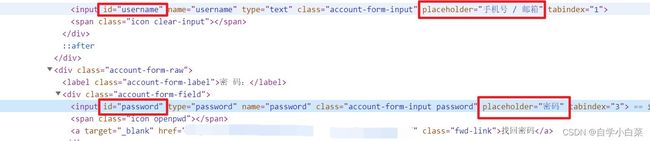
你可以发现,这种输入框都是一个名为input的标签中,并且一般会有一个名为id的属性来标记它,而这个id属性的值一般都为参数名字(不完全准确,但是大部分情况通用,下面这种方法更准确)。
当然,其实还有另外一个判断方法,首先,你随便输入账号和密码,并把浏览器的检查功能切换到Network上,然后再点击登录,去细细寻找左边出现的网页,你会发现有一个为post请求的网页,如下图所示:

那么,你会发现两种方法判断的不同,但是肯定是以后面这种为准,前面这个方法为参数,因为有时候下面这种方法并不好找。
综上,可以确定传入参数格式为:
# 不要忘记post请求中data就类似于get中的params
data = {
'remember' : 'true'
'name' : '账号',
'password' : '密码'
}
2.2 代码
这个代码也简单,主要的难点就在于确定参数。
代码如下:
import requests
# 网址
url = 'https://accounts.douban.com/passport/login?source=movie'
# 参数确定
username = input('请输入账号:')
password = input('请输入密码:')
data = {
'remember' : 'true',
'name' : username,
'password' : password
}
# header参数
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
# 请求
response = requests.post(url,headers=headers,data=data)
# 查看结果
print(response.status_code)
print(response.content.decode('utf-8'))
3. 总结
我记得在三年前,豆瓣登录并不需要处理验证码,但是我今天重新测试的时候发现需要验证码了,并且由于我的账号太多次用爬虫了,必须扫码才能登录,所以就不演示结果了。大家把思路学习会就行了(就是如何去寻找参数、如何写data参数)。
另外,上面的登录是一瞬间的登录,因为没有用到会话维持的功能,这也是下一个案例需要实现的目标,另外下一个案例我会换一个不需要验证码的网站,利用本篇的知识重新实现post请求。