主题模型分析-【LDA】
主题模型能够自动将文本语料库编码为一组具有实质性意义的类别。这些类别称为主题。
主题模型分析的典型代表就是本篇文章将要介绍的隐含迪利克雷分布,也就是LDA。
假设我们有一个文档或者新闻的集合,我们想将他们分类为主题。

我们设置好主题数量后,运行LDA模型就会得到每个主题下边词语的分布概率,以及文档对应的主题概率。

LDA可以实现这个需求,LDA采用几何学的方法,
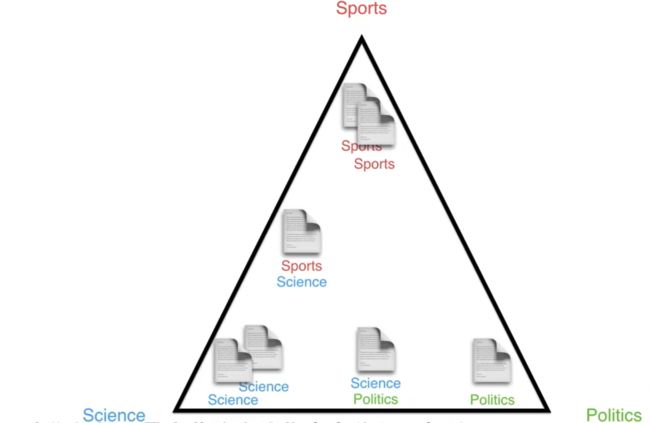
如何以最完美的方法将文章放入三角形呢?这就是LDA发挥作用的地方,我们可以把LDA看作一个生成文档的机器:
将生成的文档与原文档进行对比,以此判断模型的好坏,

LDA是怎么工作的呢?
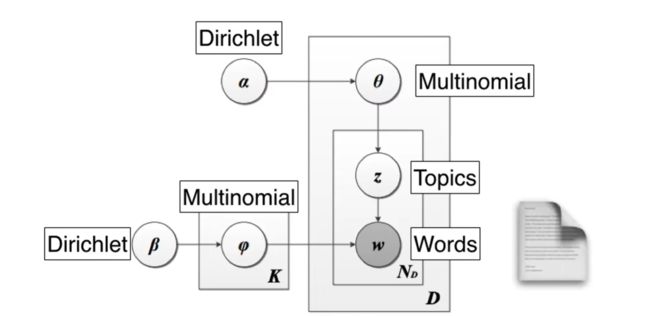
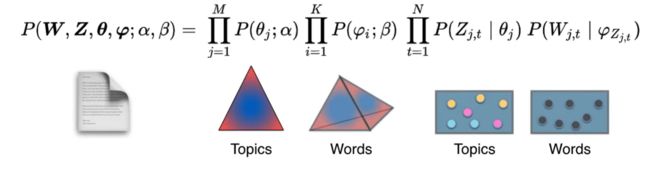
前两个是狄利克雷分布,后两个是多项式分布。
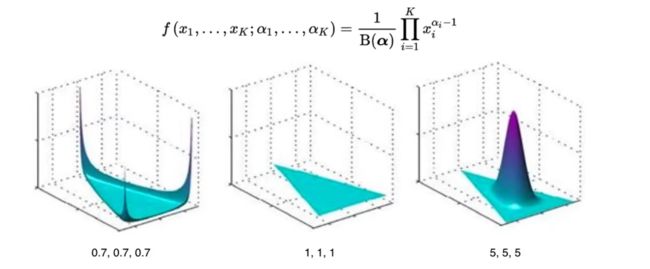
接下来看什么是狄利克雷分布,
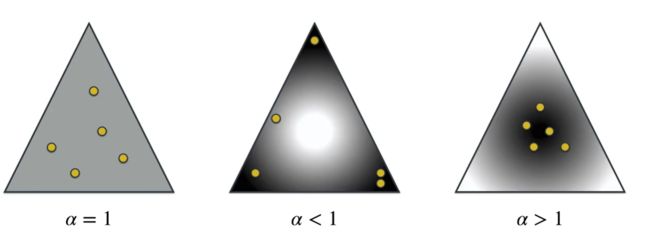
下面是狄利克雷分布的概率密度函数:
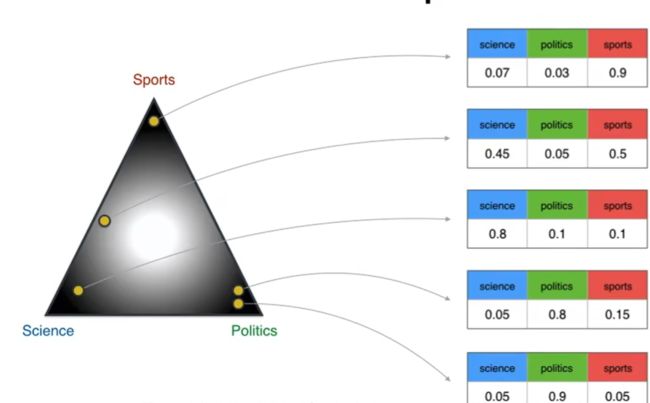
假设上图三个顶点是主题,黄色的点是文章,那么中间那个就是主题-文档的狄利克雷分布
来看另一种狄利克雷分布,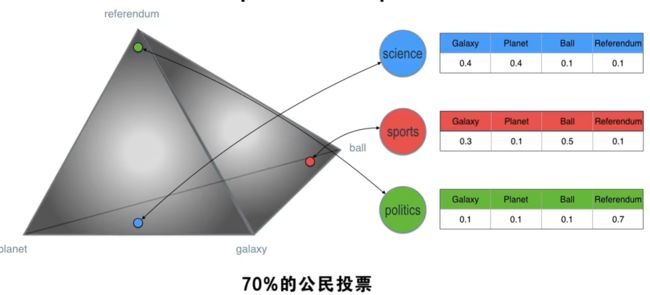
我们有两个狄利克雷分布,
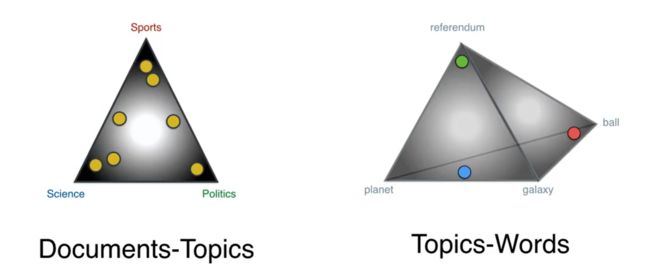
左边这个通过对应的主题把文档联系起来,右边这个通过与他们对应的单词把主题联系起来,那么这两个怎么联系起来呢?
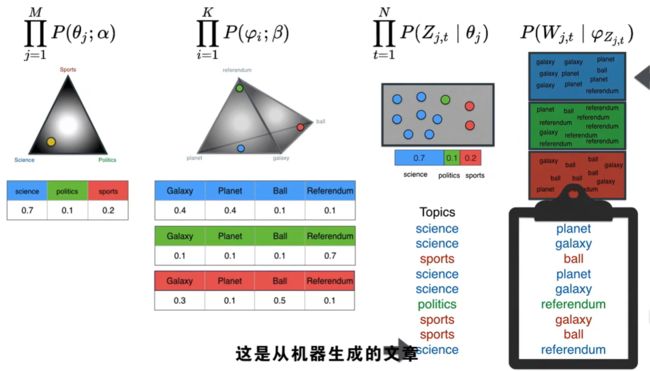

有最佳设置大的那个最有可能给出原始语料库
重复多次生成语料库中的大量文档,之后与原始文档进行比较,找出狄利克雷中点的最佳排布方式。从而最大化概率。
接下来介绍训练LDA模型的方法,称为gibbs采样。
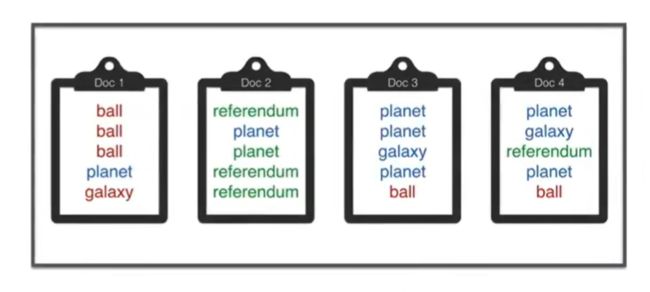
通过某种方式为每个单词着色来使这个概率最高,试图使文章更加单色,以便将我们的文档分类为主题。
总结
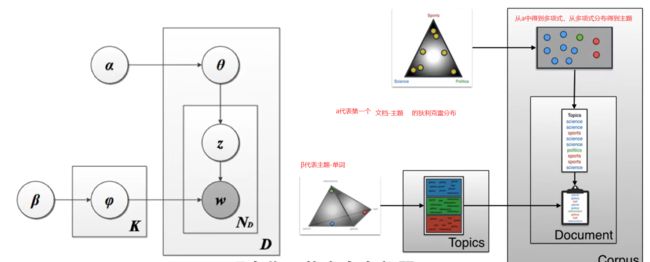
LDA(Latent Dirichlet Allocation)是一种概率模型,用于解决文本主题建模问题。它是一种无监督学习方法,可以自动地从大量文档中发现隐藏的主题结构,并将每个文档分配到一个或多个主题中。
LDA模型的核心思想是假设每个文档都由多个主题组成,并且每个主题又由多个单词组成。通过这种假设,LDA模型尝试从文档集合中推断出每个文档的主题分布以及每个主题的词分布。
具体而言,LDA模型的生成过程如下:
- 为每个文档随机分配一个主题分布。
- 对于每个词,根据文档的主题分布和主题的词分布,随机生成一个主题。
- 根据生成的主题,随机选择一个词。
- 重复2和3直到所有词都被生成。
通过这个生成过程,LDA模型可以得到文档的主题分布和主题的词分布。通过对文档进行训练,LDA模型可以找到最优的主题分布和词分布,从而实现对文本的主题建模。
使用LDA模型的步骤如下:
- 准备文本数据:将要分析的文本数据进行预处理,如分词、去除停用词等。
- 构建词袋模型:将预处理后的文本转换为数值化的向量表示,一种常用的方法是使用词袋模型,即统计每个词在文档中出现的次数或者频率。
- 建立LDA模型:使用构建好的词袋模型作为输入,通过对文档集合进行训练,得到最优的主题分布和词分布。
- 解析结果:根据训练好的模型,可以分析每个文档的主题分布以及每个主题的词分布,从而得到文档的主题信息。
通常我们需要将分词结果转化成词袋形式,得到语料(corpus)的向量化表示。
让我们具体解释一下这个操作。
在使用 LDA 模型时,corpus 通常是一个表示文档集合的向量化表示。文档集合的向量化表示是将文本数据转换为数值向量的过程。在自然语言处理中,我们需要将文本转换成机器可以理解和处理的形式,以便用于训练和应用机器学习模型。常见的向量化表示方法之一是词袋模型(Bag-of-Words)。在词袋模型中,我们首先构建一个词典(或词汇表),将所有文本数据中出现的单词进行编号。然后,对于每个文档,我们统计每个单词在该文档中的出现次数,并将其组织成一个向量。
例如:
假设我们有以下三个文本作为数据集:
Text 1: “I love cats and dogs”
Text 2: “Dogs are loyal animals”
Text3: “Cats are independent”首先,我们需要对这些文本进行分词,将其转换为单词列表的形式:
Text 1: [“I”, “love”, “cats”, “and”, “dogs”]
Text 2: [“Dogs”, “are”,“loyal”, “animals”]
Text 3: [“Cats”, “are”, “independent”]接下来,我们构建一个词典(或词汇表),将所有的单词进行编号:
词典:{“I”: 0, “love”: 1, “cats”: 2, “and”: 3, “dogs”: 4, “Dogs”: 5,“are”: 6, “loyal”: 7, “animals”: 8, “Cats”: 9, “independent”: 10}
然后,对于每个文本,我们使用doc2bow方法将其转换为词袋表示形式,得到语料库的向量化表示。
对于 Text 1,它的词袋表示形式为: [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1)]
解释:在词典中索引为0的单词"I"出现了1次,索引为1的单词"love"出现了1次,索引为2的单词"cats"出现了1次,索引为3的单词"and"出现了1次,索引为4的单词"dogs"出现了1次。对于 Text 2,它的词袋表示形式为: [(4, 1), (5, 1), (6, 1), (7, 1), (8, 1)]
对于 Text 3,它的词袋表示形式为: [(2, 1), (6, 1), (9, 1), (10, 1)]
通过这样的转换,我们将文本数据从文本形式转换为数值型的词袋表示形式。这个向量化表示可以用于训练和应用机器学习模型,如文本分类、聚类分析、相似性计算等任务。
视频链接