Spark(39):Streaming DataFrame 和 Streaming DataSet 输出
目录
0. 相关文章链接
1. 输出的选项
2. 输出模式(output mode)
2.1. Append 模式(默认)
2.2. Complete 模式
2.3. Update 模式
2.4. 输出模式总结
3. 输出接收器(output sink)
3.1. file sink
3.2. kafka sink
3.2.1. 以 Streaming 方式输出数据
3.2.2. 以 batch 方式输出数据
3.3. console sink
3.4. memory sink
3.5. foreach sink
3.6. ForeachBatch Sink
0. 相关文章链接
Spark文章汇总
1. 输出的选项
一旦定义了最终结果DataFrame / Dataset,剩下的就是开始流式计算。为此,必须使用返回的 DataStreamWriter Dataset.writeStream()。
需要指定一下选项:
- 输出接收器的详细信息:数据格式,位置等。
- 输出模式:指定写入输出接收器的内容。
- 查询名称:可选,指定查询的唯一名称以进行标识。
- 触发间隔:可选择指定触发间隔。如果未指定,则系统将在前一处理完成后立即检查新数据的可用性。如果由于先前的处理尚未完成而错过了触发时间,则系统将立即触发处理。
- 检查点位置:对于可以保证端到端容错的某些输出接收器,请指定系统写入所有检查点信息的位置。这应该是与HDFS兼容的容错文件系统中的目录。
2. 输出模式(output mode)
2.1. Append 模式(默认)
默认输出模式, 仅仅添加到结果表的新行才会输出。采用这种输出模式, 可以保证每行数据仅输出一次。在查询过程中, 如果没有使用 watermask 机制, 则不能使用聚合操作。 如果使用了 watermask 机制, 则只能使用基于 event-time 的聚合操作。watermask 用于高速 append 模式如何输出不会再发生变动的数据。 即只有过期的聚合结果才会在 Append 模式中被“有且仅有一次”的输出。
2.2. Complete 模式
每次触发, 整个结果表的数据都会被输出。 仅仅聚合操作才支持。同时该模式使用 watermask 无效。
2.3. Update 模式
该模式在 从 spark 2.1.1 可用. 在处理完数据之后, 该模式只输出相比上个批次变动的内容(新增或修改)。如果没有聚合操作, 则该模式与 append 模式一样。如果有聚合操作, 则可以基于 watermast 清理过期的状态。
2.4. 输出模式总结
不同的查询支持不同的输出模式
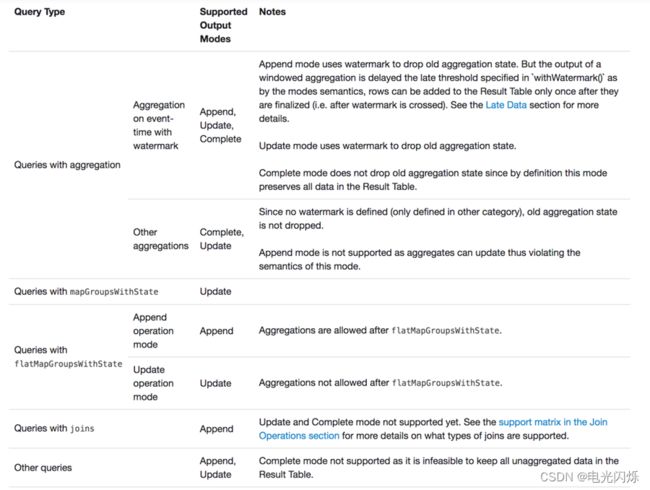
3. 输出接收器(output sink)
spark 提供了几个内置的 output-sink,不同 output sink 所适用的 output mode 不尽相同:
| Sink | Supported Output Modes | Options | Fault-tolerant | Notes |
| File Sink | Append | path: path to the output directory, must be specified. For file-format-specific options, see the related methods in DataFrameWriter (Scala/Java/Python/R). E.g. for “parquet” format options see DataFrameWriter.parquet() | Yes (exactly-once) | Supports writes to partitioned tables. Partitioning by time may be useful. |
| Kafka Sink | Append, Update, Complete | See the Kafka Integration Guide | Yes (at-least-once) | More details in the Kafka Integration Guide |
| Foreach Sink | Append, Update, Complete | None | Depends on ForeachWriter implementation | More details in the next section |
| ForeachBatch Sink | Append, Update, Complete | None | Depends on the implementation | More details in the next section |
| Console Sink | Append, Update, Complete | numRows: Number of rows to print every trigger (default: 20) truncate: Whether to truncate the output if too long (default: true) | No | |
| Memory Sink | Append, Complete | None | No. But in Complete Mode, restarted query will recreate the full table. | Table name is the query name. |
3.1. file sink
存储输出到目录中 仅仅支持 append 模式
需求: 把单词和单词的反转组成 json 格式写入到目录中。
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import java.sql.Timestamp
object StreamTest {
def main(args: Array[String]): Unit = {
// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSession
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("StreamTest")
.getOrCreate()
import spark.implicits._
// 设置数据源,并接收数据
val lines: DataFrame = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load
// 数据计算
val words: DataFrame = lines
.as[String]
.flatMap((line: String) => {
line
.split("\\W+")
.map((word: String) => {
(word, word.reverse)
})
})
.toDF("原单词", "反转单词")
// 结果输出
words
.writeStream
.outputMode("append")
.format("json") // 支持 "orc", "json", "csv"
.option("path", "./filesink") // 输出目录
.option("checkpointLocation", "./ck1") // 必须指定 checkpoint 目录
.start
.awaitTermination()
// 关闭执行环境
spark.stop()
}
}输出的数据:
{"原单词":"abc","反转单词":"cba"}
3.2. kafka sink
将 wordcount 结果写入到 kafka
写入到 kafka 的时候应该包含如下列:
| Column | Type |
| key (optional) | string or binary |
| value (required) | string or binary |
| topic (optional) | string |
注意:
- 如果没有添加 topic option 则 topic 列必须有.
- kafka sink 三种输出模式都支持
3.2.1. 以 Streaming 方式输出数据
这种方式使用流的方式源源不断的向 kafka 写入数据:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import java.sql.Timestamp
object StreamTest {
def main(args: Array[String]): Unit = {
// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSession
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("StreamTest")
.getOrCreate()
import spark.implicits._
// 设置数据源,并接收数据
val lines: DataFrame = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load
// 数据计算
val words = lines
.as[String]
.flatMap((_: String).split("\\W+"))
.groupBy("value")
.count()
.map((row: Row) => row.getString(0) + "," + row.getLong(1))
.toDF("value") // 写入数据时候, 必须有一列 "value"
words.writeStream
.outputMode("update")
.format("kafka")
.trigger(Trigger.ProcessingTime(0))
.option("kafka.bootstrap.servers", "bigdata1:9092,bigdata2:9092,bigdata3:9092") // kafka 配置
.option("topic", "update") // kafka 主题
.option("checkpointLocation", "./ck1") // 必须指定 checkpoint 目录
.start
.awaitTermination()
// 关闭执行环境
spark.stop()
}
}3.2.2. 以 batch 方式输出数据
这种方式输出离线处理的结果, 将已存在的数据分为若干批次进行处理. 处理完毕后程序退出:
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import java.sql.Timestamp
object StreamTest {
def main(args: Array[String]): Unit = {
// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSession
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("StreamTest")
.getOrCreate()
import spark.implicits._
val wordCount: DataFrame = spark
.sparkContext
.parallelize(Array("hello hello abc", "abc, hello"))
.toDF("word")
.groupBy("word")
.count()
.map(row => row.getString(0) + "," + row.getLong(1))
.toDF("value") // 写入数据时候, 必须有一列 "value"
wordCount.write // batch 方式
.format("kafka")
.option("kafka.bootstrap.servers", "bigdata1:9092,bigdata2:9092,bigdata3:9092") // kafka 配置
.option("topic", "update") // kafka 主题
.save()
// 关闭执行环境
spark.stop()
}
}
3.3. console sink
主要用于测试数据输出
3.4. memory sink
该 sink 也是用于测试, 将其统计结果全部输入内中指定的表中, 然后可以通过 sql 与从表中查询数据。
如果数据量非常大, 可能会发送内存溢出:
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import java.sql.Timestamp
import java.util.{Timer, TimerTask}
object StreamTest {
def main(args: Array[String]): Unit = {
// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSession
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("StreamTest")
.getOrCreate()
import spark.implicits._
// 设置数据源,并接收数据
val lines: DataFrame = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load
val words: DataFrame = lines
.as[String]
.flatMap((_: String).split("\\W+"))
.groupBy("value")
.count()
val query: StreamingQuery = words
.writeStream
.outputMode("complete")
.format("memory") // memory sink
.queryName("word_count") // 内存临时表名
.start
// 测试使用定时器执行查询表
val timer: Timer = new Timer(true)
val task: TimerTask = new TimerTask {
override def run(): Unit = spark.sql("select * from word_count").show
}
timer.scheduleAtFixedRate(task, 0, 2000)
query.awaitTermination()
// 关闭执行环境
spark.stop()
}
}3.5. foreach sink
foreach sink 会遍历表中的每一行, 允许将流查询结果按开发者指定的逻辑输出;把 wordcount 数据写入到 mysql。
注意(需要在依赖中添加MySQL的驱动依赖):
mysql
mysql-connector-java
5.1.27
建表语句如下所示:
create database ss;
use ss;
create table word_count
(
word varchar(255) primary key not null,
count bigint not null
);
代码示例如下:
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, ForeachWriter, Row, SparkSession}
import java.sql.{Connection, DriverManager, PreparedStatement, Timestamp}
import java.util.{Timer, TimerTask}
object StreamTest {
def main(args: Array[String]): Unit = {
// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSession
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("StreamTest")
.getOrCreate()
import spark.implicits._
// 设置数据源,并接收数据
val lines: DataFrame = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load
val wordCount: DataFrame = lines
.as[String]
.flatMap((_: String).split("\\W+"))
.groupBy("value")
.count()
val query: StreamingQuery = wordCount
.writeStream
.outputMode("update")
// 使用 foreach 的时候, 需要传递ForeachWriter实例, 三个抽象方法需要实现. 每个批次的所有分区都会创建 ForeeachWriter 实例
.foreach(new ForeachWriter[Row] {
var conn: Connection = _
var ps: PreparedStatement = _
var batchCount = 0
// 一般用于 打开链接. 返回 false 表示跳过该分区的数据,
override def open(partitionId: Long, epochId: Long): Boolean = {
println("open ..." + partitionId + " " + epochId)
Class.forName("com.mysql.jdbc.Driver")
conn = DriverManager.getConnection("jdbc:mysql://hadoop201:3306/ss", "root", "aaa")
// 插入数据, 当有重复的 key 的时候更新
val sql = "insert into word_count values(?, ?) on duplicate key update word=?, count=?"
ps = conn.prepareStatement(sql)
conn != null && !conn.isClosed && ps != null
}
// 把数据写入到连接
override def process(value: Row): Unit = {
println("process ...." + value)
val word: String = value.getString(0)
val count: Long = value.getLong(1)
ps.setString(1, word)
ps.setLong(2, count)
ps.setString(3, word)
ps.setLong(4, count)
ps.execute()
}
// 用户关闭连接
override def close(errorOrNull: Throwable): Unit = {
println("close...")
ps.close()
conn.close()
}
})
.start
query.awaitTermination()
// 关闭执行环境
spark.stop()
}
}3.6. ForeachBatch Sink
ForeachBatch Sink 是 spark 2.4 才新增的功能, 该功能只能用于输出批处理的数据。将统计结果同时输出到本地文件和 mysql 中。
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, ForeachWriter, Row, SparkSession}
import java.sql.{Connection, DriverManager, PreparedStatement, Timestamp}
import java.util.{Properties, Timer, TimerTask}
object StreamTest {
def main(args: Array[String]): Unit = {
// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSession
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("StreamTest")
.getOrCreate()
import spark.implicits._
// 设置数据源,并接收数据
val lines: DataFrame = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load
val wordCount: DataFrame = lines
.as[String]
.flatMap(_.split("\\W+"))
.groupBy("value")
.count()
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "aaa")
val query: StreamingQuery = wordCount
.writeStream
.outputMode("complete")
.foreachBatch((df: Dataset[Row], batchId: Long) => { // 当前分区id, 当前批次id
if (df.count() != 0) {
df.cache()
df.write.json(s"./$batchId")
df.write.mode("overwrite").jdbc("jdbc:mysql://hadoop201:3306/ss", "word_count", props)
}
})
.start()
query.awaitTermination()
// 关闭执行环境
spark.stop()
}
}注:其他Spark相关系列文章链接由此进 -> Spark文章汇总