String类

欢迎来到Cefler的博客
博客主页:那个传说中的man的主页
个人专栏:题目解析
推荐文章:题目大解析2
目录
- 了解string类
- string的迭代器
- string constructor
- string operator=
- string类对象的容量操作
- string Element access
- string modifiers
- String operations
- getline
- 字符编码标准
-
- unicode编码
- Gb2312
- Gbk
了解string类
- string是表示字符串的字符串类
- 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
- string在底层实际是:basic_string模板类的别名,typedef basic_string
string; - 不能操作多字节或者变长字符的序列。
string类官方文档
string的迭代器
我们一般访问string的字符,一般都是使用运算符重载operator[]
#include 但是这里我们引入迭代器这个概念
C++中的迭代器是一种用于遍历容器元素的对象。它提供了一种统一的方式来访问容器中的元素,而不需要了解容器的内部实现细节。
迭代器可以分为输入迭代器、输出迭代器、前向迭代器、双向迭代器和随机访问迭代器等几种类型,每种类型具有不同的功能和限制。
使用迭代器可以通过以下方式访问容器的元素:
- 通过解引用操作符*来获取当前迭代器指向的元素的值。
- 通过递增操作符++将迭代器移动到容器中的下一个元素。
- 通过递减操作符–将迭代器移动到容器中的上一个元素(仅适用于双向迭代器和随机访问迭代器)。
迭代器的使用可以帮助我们在不依赖具体容器类型的情况下,对容器中的元素进行遍历、访问和修改。这使得我们可以编写更加通用和灵活的代码。
迭代器使用语法
-
声明迭代器:使用容器的类型作为模板参数来声明迭代器。例如,vector< int>::iterator 是一个指向 vector< int> 容器中元素的迭代器。
-
初始化迭代器:可以使用容器的成员函数来初始化迭代器,或者使用迭代器的构造函数来初始化。例如,vector::iterator it = myVector.begin(); 将迭代器 it 初始化为指向 myVector 容器的第一个元素。
-
使用迭代器:可以使用迭代器来访问容器中的元素。例如,*it 可以获取迭代器 it 指向的元素的值,it++ 可以将迭代器 it 向后移动一个位置。
-
迭代器的操作:迭代器支持多种操作,例如 ++ 运算符用于将迭代器向后移动一个位置,-- 运算符用于将迭代器向前移动一个位置,== 运算符用于比较两个迭代器是否相等等。
迭代器的用法类似指针。
需要注意的是,不同类型的容器可能有不同类型的迭代器,因此在使用迭代器时需要根据具体的容器类型来选择相应的迭代器类型和语法
在这里我还要再介绍一下迭代器中的两个函数:
begin():
Returns an iterator pointing to the first character of the string.
None parameters
它的返回值是字符串的首个字符的位置。
没有参数
end():
Returns an iterator pointing to the past-the-end character of the string.
返回一个指向字符串结束位置的迭代器
It often used in combination with begin()
我们看个例子:
#include 除了begin()和end(),还有反向迭代器,以及const 迭代器,可以参考string官方文档了解。

string constructor
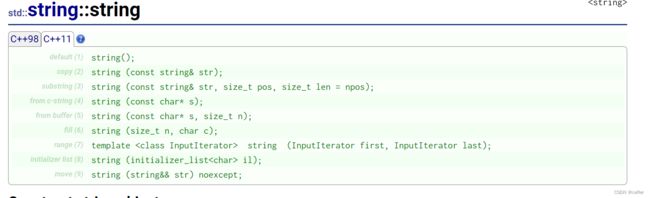
上述中,我们常用到的接口也就是有:
- string() (重点): 构造空的string类对象,即空字符串
- string(const char* s) (重点): 用C-string来构造string类对象
- string(size_t n, char c) :string类对象中包含n个字符c
- string(const string&s) : 拷贝构造函数
npos
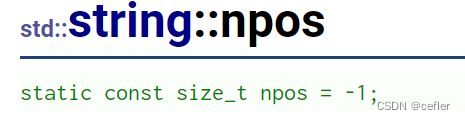
由于是无符号整型,所以大小大概有40多亿。
string operator=
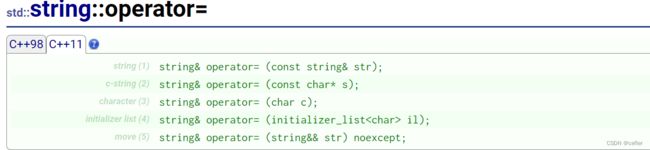
The function of the operator= is to assign a new value to the string, replacing its current contents.
string类对象的容量操作
c++提供这些函数:

resize:调整字符串大小
grammer:
void resize (size_t n);
void resize (size_t n, char c);
Resizes the string to a length of n characters.
If n is smaller than the current string length, the current value is shortened to its first n character, removing the characters beyond the nth.
If n is greater than the current string length, the current content is extended by inserting at the end as many characters as needed to reach a size of n. If c is specified, the new elements are initialized as copies of c, otherwise, they are value-initialized characters (null characters).
如果c没有具体说明,就用\0来补
reserve:为字符串预留空间
Requests that the string capacity be adapted to a planned change in size to a length of up to n characters.
If n is greater than the current string capacity, the function causes the container to increase its capacity to n characters (or greater).
也就是说至少会开n characters,可能会多开一些。
In all other cases, it is taken as a non-binding request to shrink the string capacity: the container implementation is free to optimize otherwise and leave the string with a capacity greater than n.
缩小容量的请求是没有约束力的,所以这个缩小容量可能可以缩小,但也可能不会缩小,但编译器一般会优化不缩小。
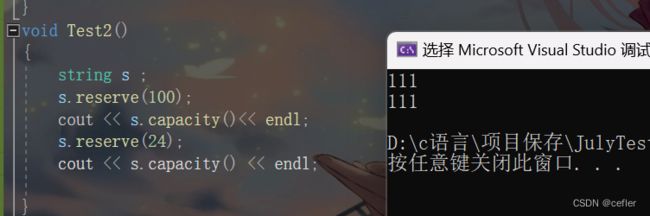
VS2019编译器下,就没有缩小。
This function has no effect on the string length and cannot alter its content.
只需记住,reserve改变的只有capacity
- clear:清空有效字符
Erases the contents of the string, which becomes an empty string (with a length of 0 characters).
- empty:
Returns whether the string is empty (i.e. whether its length is 0).
Return value
if it is empty return 1,false otherwise
string Element access

operator[]:
char& operator[] (size_t pos);
const char& operator[] (size_t pos) const;
Returns a reference to the character at position pos in the string.
at:
char& at (size_t pos);
const char& at (size_t pos) const;
Returns a reference to the character at position pos in the string.
The function automatically checks whether pos is the valid position of a character in the string (i.e., whether pos is less than the string length), throwing an out_of_range exception if it is not.
这个和operator[]差不多,只是会报错
back:
access the last character of the string.
This function shall not be called on empty strings.
front:
同理back,只是返回首位元素
string modifiers

这里具体实现可查阅官方文档。
给一些重要的说明:
- 追加接口首选operator+=
- 一般赋值,用= 就行,若需求是赋值一小段,则用assign
- 不介意经常使用insert/erase/replace,因为都涉及数据的挪动,耗时
- string::swap好在是交换地址,减少调用拷贝构造次数,而库提供的Swap则会多次调用拷贝构造次数,但是如果是string类的swap,会优先使用string::swap,因为库提供的Swap是一个模板,编译器会优先调用现成的。
String operations
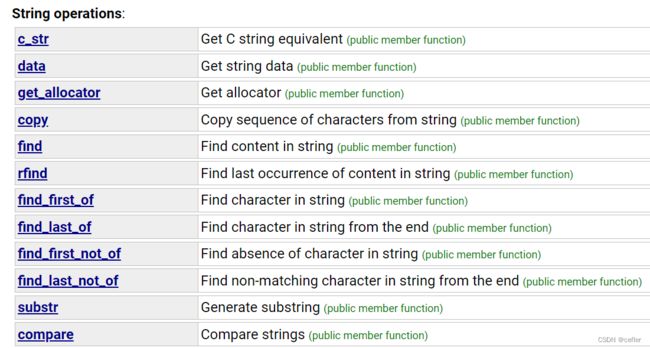
-
c_str和data功能相似,都是获取char* string
-
find:

Return Value
The position of the first character of the first match.
If no matches were found, the function returns string::npos. -
substr:

Return Value
A string object with a substring of this object
find和substr合作分割网址协议、域名、资源。
void Test3()
{
string s = "https://www.baidu.com/default.html";
size_t pos1 = s.find(':');
string s1 = s.substr(0, pos1);
size_t pos2 = s.find('/', pos1 + 3);
string s2 = s.substr(pos1 + 3, pos2);
string s3 = s.substr(pos2 + 1, string::npos);
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
}
find_first_of:
size_t find_first_of (const string& str, size_t pos = 0) const noexcept;
size_t find_first_of (const char* s, size_t pos = 0) const;
size_t find_first_of (const char* s, size_t pos, size_t n) const;
size_t find_first_of (char c, size_t pos = 0) const noexcept;
从字符串中找到任意符合序列中的单个字符就行了
find_last_of是从后往前找。
#include getline
getline 是 C++ 中的一个函数,用于从输入流中读取一行文本。它的语法如下:
std::getline(istream& input, string& line);
其中,input 是输入流对象,可以是 cin(标准输入流)或文件流等;line 是用于存储读取到的文本的字符串对象。
getline 函数会读取输入流中的一行文本,直到遇到换行符(‘\n’)为止,并将读取到的文本存储到 line 字符串中。读取过程中,换行符不会被存储在 line 中。
getline还可以更改定界符。
istream& getline (istream& is, string& str, char delim);
If the delimiter is found, it is extracted and discarded (i.e. it is not stored and the next input operation will begin after it).
字符编码标准
unicode编码
概述
Unicode 是一种字符编码标准,用于表示世界上几乎所有的字符和符号。它为每个字符分配了一个唯一的数字,称为码点(code point)。Unicode 码点的范围从 U+0000 到 U+10FFFF。
Unicode 使用不同的编码方案来表示这些码点,最常见的编码方案是 UTF-8、UTF-16 和 UTF-32。
- UTF-8 是一种
变长编码方案,使用 8 位(1 字节)到 32 位(4 字节)来表示不同的字符。它是 ASCII 字符集的扩展,兼容 ASCII 编码,可以表示世界上几乎所有的字符。 - UTF-16 是一种定长或变长编码方案,使用 16 位(2 字节)来表示大部分常用字符,使用 32 位(4 字节)来表示辅助平面字符(如表情符号、特殊符号等)。
- UTF-32 是一种定长编码方案,使用 32 位(4 字节)来表示所有的字符,无论是常用字符还是辅助平面字符。
在编程中,我们经常会遇到需要处理 Unicode 字符的情况。在大多数编程语言中,字符串类型通常支持 Unicode 编码,可以存储和操作 Unicode 字符。
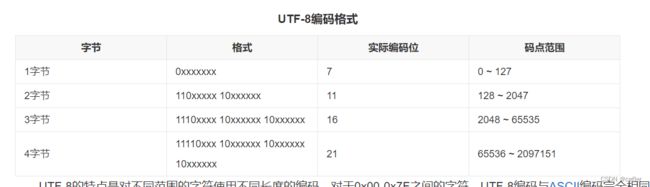
我们编译器一般遵循的都是UTF-8编码格式
所以这是为什么如果二进制存储格式0开头的都是字母。
汉字都是1开头的,但一个汉字是2字节。
Gb2312
概述
GB2312是中国国家标准局于1980年发布的字符集标准,它是对汉字和拉丁字母的编码方式进行统一的规范。GB2312字符集包含了大约7000多个常用汉字和拉丁字母,其中包括了基本的汉字、标点符号、数字和拉丁字母。
GB2312使用双字节编码,每个字符占用两个字节。其中,第一个字节的范围是0xA1至0xF7,第二个字节的范围是0xA1至0xFE。通过这种编码方式,GB2312可以表示大部分常用的汉字和一些特殊字符。
GB2312字符集的编码方式在计算机中广泛应用于中文信息处理、文本编辑、网页编码等领域。然而,由于GB2312字符集的容量有限,无法涵盖所有的汉字和特殊字符,因此后来又出现了更为完善的字符集标准,如GBK和GB18030。
Gbk
概述
GBK(Guo Biao Kuai Jie)是中文字符集编码标准之一,也是中国国家标准。它是在GB2312的基础上进行扩展的,支持更多的汉字字符。
GBK编码使用16位(2个字节)来表示一个字符,可以表示包括简体中文、繁体中文和一些其他的汉字字符。GBK编码兼容ASCII编码,即前128个字符的编码与ASCII编码相同。
GBK编码的字符范围包括了GB2312编码的全部字符,以及一些其他的汉字字符。它的编码范围是0x8140到0xFEFE,其中高字节的范围是0x81到0xFE,低字节的范围是0x40到0xFE。
GBK编码在计算机中的应用非常广泛,特别是在中文操作系统、中文编程环境和中文网页等领域。在使用GBK编码时,需要注意编码的转换和处理,以确保正确地处理中文字符。
如上便是本期的所有内容了,如果喜欢并觉得有帮助的话,希望可以博个点赞+收藏+关注❤️ ,学海无涯苦作舟,愿与君一起共勉成长