【人工智能前沿弄潮】——生成式AI系列:扩散模型及稳定扩散模型
VAE、GAN的出现,使得生成式AI越发火热,如今扩散模型的出现与兴起,更是将AIGC推到了人工智能风口,被视作如今人工智能生成艺术领域取得突破的主要因素。相较于VAE和GAN,扩散模型生成的图片质量更好。随着transformer架构的出现和prompt工程的兴起,根据文本提示生成图像的技术已经越发成熟,稳定扩散模型的出现和发展使得我们可以轻松地通过文本提示创建美妙的艺术插图。所以在本文中,我将解释它们是如何工作的,本次不会堆砌复杂的公式,而是用通俗的语言解释扩散模型以及稳定扩散模型的工作原理。
1、Diffusion Model
1.1 Diffusion Model原理概述
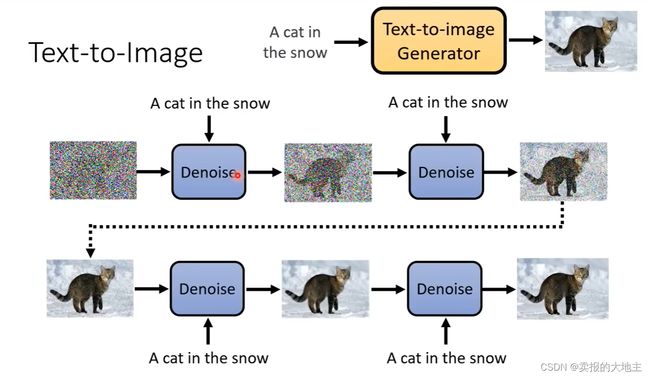
如下图所示,与GAN 利用生成器和判别器进行对抗训练来生成图像不同,扩散模型则是通过对生成的随机噪声进行循环去噪来生成图像,就有点像雕刻一样,一块原石,随着大师一点一点地去除掉多余的部分,剩下的就是完美的艺术品。所使用的随机噪声需要和生成的目标图像具有相同的高宽。
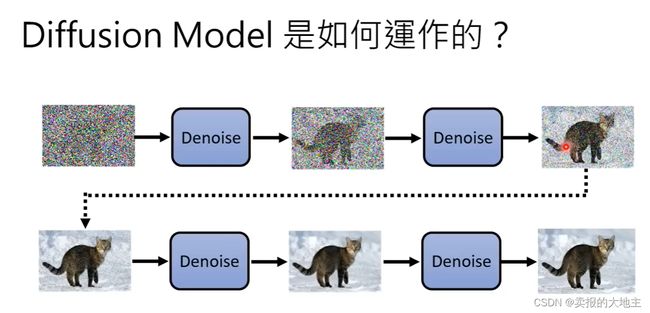
在扩散模型的去噪过程中,去噪的步骤数(step)是人工提前定好的,如1000等。这个step不仅是步骤数,也代表着噪声的严重程度信息。
每次去噪所的Denoise 模块是同一个,进行反复使用。Denoise模块的输入不仅仅有随机噪声图像,还有其对应的step。

1.2 Denoise模块实现原理
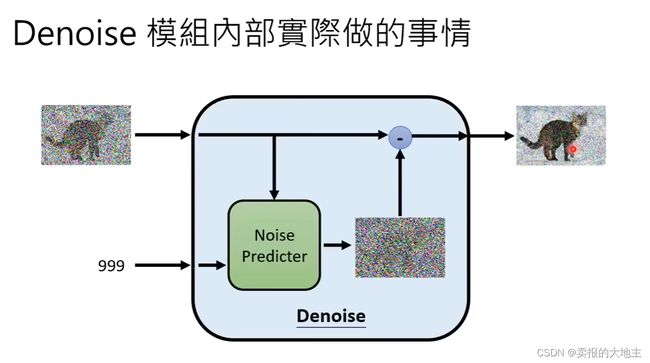
Denoise模块内部有一个Noise Preidicter,如下图所示,其输入是原始噪声图像和step,输出一个噪声图像,这个输出的噪声是一个纯噪声图像,而不是去噪的结果图像,然后再利用输入的原始噪声图像减去生成的纯噪声图像得到去噪结果图像。 这样做是因为训练生成纯噪声要比直接生成去噪后的结果图像要简单,更易训练。当然,大家可以尝试以下直接生成去噪图像。
1.3 如何训练Noise Preidicter?
首先是训练资料的获取。扩散模型的训练资料是人工自己创造的,如下图所示,就是在原始图像上逐step加噪声, 这个过程叫做Forward Process,也叫Diffusion Process。

接着就是Noise Preidicter的输入是哪些,Noise Preidicter的输出是哪些。如图,Noise Preidicter的输入是加了噪声后的图像和对应的step。输出则是生成的纯噪声,与之对应的是我们制作数据时所加的纯噪声,也就是我们的ground truth。

对于文生图,就需要训练数据存在对应的文本信息,在输入原始噪声图像和step的基础上,还需要将图像对应的文字描述信息也加入Denoise模块中(加入到Noise Preidicter中)进行训练。


1.4 算法流程伪代码
以下为扩散模型的算法流程的伪代码

2、Stable Diffusion
稳定扩散模型依据文本提示生成图像,其主要由三部分组成:① text encoder ② Generation Model ③ Decoder,三者分开单独训练,然后再组合起来。模型总体结构如下图所示。

2.1 Text Encoder
Text Encoder,其将我们的prompt(提示词)进行编码转换,变为生成模型所需要的embedding,GPT、Bert都可以当做Text Encoder。关于Text Encoder在此我们不再赘述。
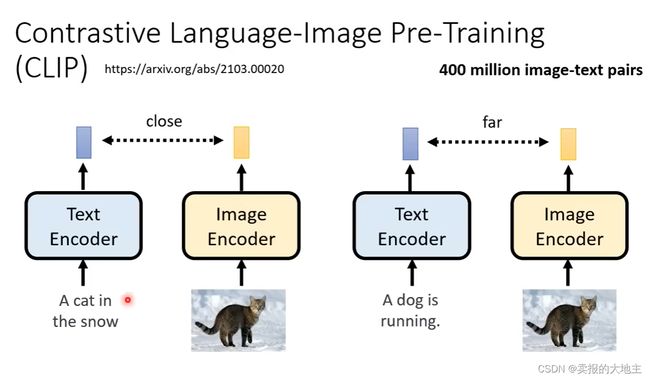
如下图所示,Text Encoder的效果对生成图像结果的影响很大。

注:FID越小、CLIP Score越大,生成图像越好。
FID:利用预训练好的CNN网络对生成图像的隐变量进行提取,并通过softmax激活函数对隐变量归一化,将归一化的隐变量结果同利用真实数据所提取的归一化隐变量进行分布距离度量,根据度量结果判定生成图像效果的好坏。分布度量采用的是Frechet距离。建议在sample大量图像再测FID精度比较可靠。

CLIP:将生成图像和当时训练对应的文字喂到CLIP中,两者的生成向量近则生成图像效果好,向量远则效果差。
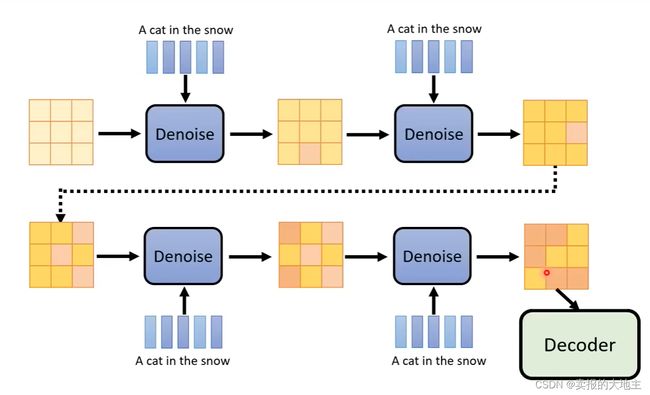
2.2 Generation Model
Generation Model,也就是生成模型,在这里,用的就是我们的稳定扩散模型。模型输入为:①text encoder所生成的embedding ②随机噪声图像(注意这里的随机噪声图像不与我们的目标图像一致,而是其缩小版) ③step。输出为:一个压缩版的中间产物——可以是人类看的懂或者看不懂的。

在制作训练数据时,噪声不再是加在原始图像上,而是加在利用编码器对原始图形进行提取编码的压缩版隐变量特征图上(对应着推理时模型输出的中间产物)。训练时的Denoise模块的输入输出也相应改变,输入为加了噪声的中间产物、text encoder所生成的embedding和step,输出为纯噪声。

2.3 Decoder
Decoder是把Generation Model生成的中间产物转换为我们目标图像的部分,给我们的感觉有点像语义分割模型的解码器,或者超分网络模型。我们可以直接将训练好的VAE的解码器当作Decoder。
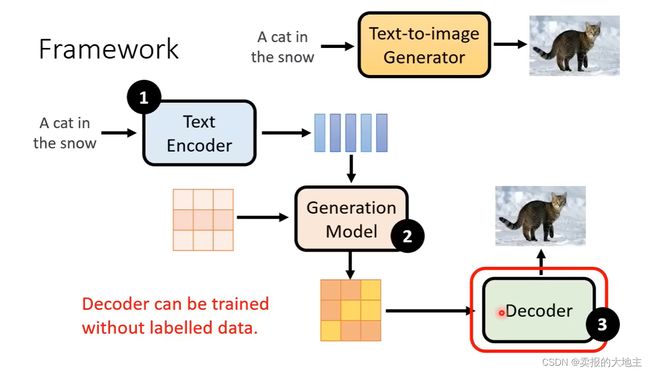
Decoder的训练只需要图像,不需要对应文字。
若Generation Model所生成的中间产物是人可看懂的小图的情况时——Decoder输入为影像的下采样结果,输出为原始影像。我们可以将自己可获取图像数据进行下采样,将下采样结果作为Decoder的输入,将原始影像作为输出进行Decoder的训练。

若Generation Model所生成的中间产物是人类看不懂的压缩图(latent representation),我们则需要AUTO-ENCODER来帮我们还原生成的目标图像。

2.4 示例模型
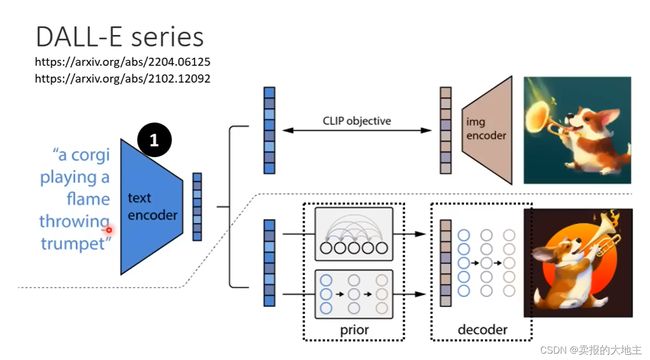
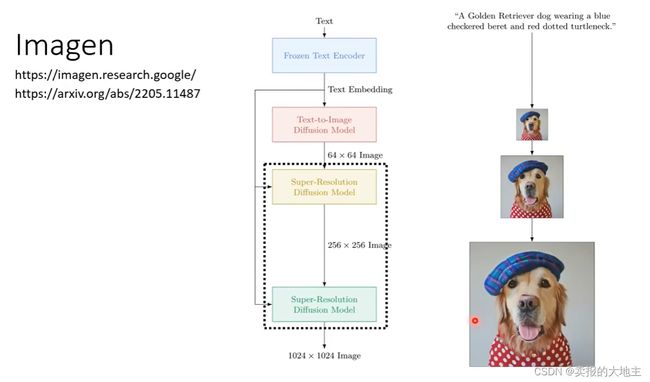
如下图我们可以看到,Stable Diffusion、DALL-E系列、Imagen等都是上述的结构模式。