大数据平台中元数据库—MySQL的异常故障解决
本文的主要目标是解决大数据平台中元数据库MySQL的异常故障。通过分析应用响应缓慢的问题,找到了集群组件HIVE和元数据库MySQL的原因。通过日志分析、工具检测和专家指导等一系列方法, 最终确定问题的根源是大数据集群中租户的不规范使用所导致,并逐步解决了这个问题。本文将详细描述故障的定位和解决思路,希望通过案例分析能为遇到类似问题的同行提供参考。
本文来自twt社区专业委员会的课题研究
一、故障背景
营销人员在应用端进行目标客户群建设的时候,发现有很大延迟。经过反馈、初步的查实定位,发现是后端调用大数据集群服务的时候,出现了没有返回的情况。这个情况导致后续的住户画像、上传集团、报数以及多个需要提醒目标客户的应用延迟。甚至引起了部分专业分公司的投诉。
二、故障解决思路
1、故障定位:
HIVE 组件的问题分两类:
1.hivemetastore
通过集群的监控页面或者hivemetastore的日志分析查看hivemetastore的并发数量等参数的限制问题
2.hiveserver2
1)咨询查看是不是最近有新增加的任务,通过分析看看不是有异常的SQL语句等程序;
2)通过集群的监控页面或者hiveserver2的日志分析,查看是不是存在参数的问题;
3)审计分析hive的 元数据库 表,是不是存在大量的分区表或者大的全表扫描的表等需要重点关注的审计表等信息
2、故障解决:
既然已经知道是hive组件导致的MySQL元数据库的问题,建议从以下方面着手:
1.从hive组件着手
a.检查是不是最近有新上的任务,没有经过代码审计或者SQL写的不规范的任务,占用资源过多,从而导致集群响应缓慢;
b.检查hiveserver2和hivemetastore的参数,分析其日志,看看是不是由于参数问题导致的集群组件缓慢;
2.从MySQL数据库着手
a.检查MySQL服务器的硬件资源情况,查看CPU、内存、IO、网卡等信息,看看是不是存在使用率过高的情况;
b.对hive的元数据库进行盘点分析,看看是不是有长连接或者占用资源很大的SQL语句运行,从而导致数据库缓慢;
3.从YARN组件着手
a)查看租户队列资源的分配是否合理;
b)检查是否存在有大量的状态不正常的任务。
3、案例说明:
1.如何发现MySQL的元数据库异常故障问题
1)5月6日18点30分,运维人员发现创建目标客户群任务延迟;经过查实,集群响应效率缓慢导致任务延迟;
2)5月6日19点到23点40分,经过分析spark日志、hiveserver日志,NameNode日志,hivemetastore日志,均未发现异常。在CM监控页面,集群巡检各项指标均未发现异常;
3)5月6日23点55分,运维人员发现mysql的元数据库长连接会话较多,且Innod锁数量持续增加未释放;
4)5月7日0点3分,运维人员请求基保部同事协助定位原因,发现是元数据库(MySQL)中存在大数据租户的多个长连接,影响数据库的性能,进而影响集群任务的提交响应效率;经过查实,长连接会话及未释放的Innod锁是由租户user_yddsj(大数据租户)的任务发起;
5)5月7日0点12分,运维人员电话通知大数据租户厂家进行清理;并邮件通知局方协助,要求大数据租户厂家对长连接会话进行清理;
6)5月7日 0点30分,同步邀请H公司大数据产品线专家协助处理,经过大数据产品线专家远程分析,初步定位原因为metastore的并发数量不够,把metastore的并发数量进行源码级别的调整(增大并发数量),在测试环境经过多次部署、调测、验证后,于5月7日20点30分发布到正式环境,21点30分完成了hivemetastore的服务重启。重启后,集群能力恢复正常。但是经过跟踪监测,集群服务性能在23点45分左右持续下降,排除了hivemetastore的并发数量的影响,并于当晚邀请专家次日到现场进行支撑。
7)5月8日8点10分,H公司多位专家到达湖南电信现场,携手定位故障原因,集成专家发现MySQL数据库主机IO占用持续达到99%;
8)5月8日8点30分,通过MySQL专家定位,确认是5月7日发现的长连接会话及未释放的Innod锁仍未释放,这些会话指向的目标表为user_yddsj.volte_mw,经过查询元数据信息,此表有2万多个分区,且租户的执行程序存在全表扫描的情况。导致MySQL数据库主机IO占用持续高水位;
9)5月8日11点19分,运维人员协同局方负责人,通知大数据租户对表user_yddsj.volte_mw进行分区清理。经过局方负责人与大数据租户确认,为尽快恢复集群的服务正常,决定先停止大数据租户的集群服务,且停止其应用程序;
10)5月8日11点40分,大数据租户开始清理user_yddsj.volte_mw表分区。于12点30分收到大数据租户表分区清理完成的通知;
11)5月8日13点30分,运维人员经过一个多小时的观察,集群的服务响应和性能都已经恢复正常。访问元数据库效率恢复正常。

图1:基础保障部同事协助定位长连接问题

图2-1:长连接相关语句,对应用户为大数据开放的租户

图2-2:长连接相关语句,对应用户为大数据开放的租户

图2-3:长连接相关语句,对应用户为大数据开放的租户
图3:5月8日MySQL数据库主机IO高水位

图4-1:5月8日MySQL数据库长连接语句,定位大数据租户表user_yddsj.volte_mw存在2万多个表分区
图4-2:5月8日MySQL数据库长连接语句,定位大数据租户表user_yddsj.volte_mw存在2万多个表分区
图4-3:5月8日MySQL数据库长连接语句,定位大数据租户表user_yddsj.volte_mw存在2万多个表分区
图4-4:5月8日MySQL数据库长连接语句,定位大数据租户表user_yddsj.volte_mw存在2万多个表分区

图4-5:5月8日MySQL数据库长连接语句,定位大数据租户表user_yddsj.volte_mw存在2万多个表分区

图4-6:5月8日MySQL数据库长连接语句,定位大数据租户表user_yddsj.volte_mw存在2万多个表分区

图4-7:5月8日MySQL数据库长连接语句,定位大数据租户表user_yddsj.volte_mw存在2万多个表分区

图4-8:5月8日MySQL数据库长连接语句,定位大数据租户表user_yddsj.volte_mw存在2万多个表分区

图5:5月8日定位大数据租户执行程序全表扫描问题
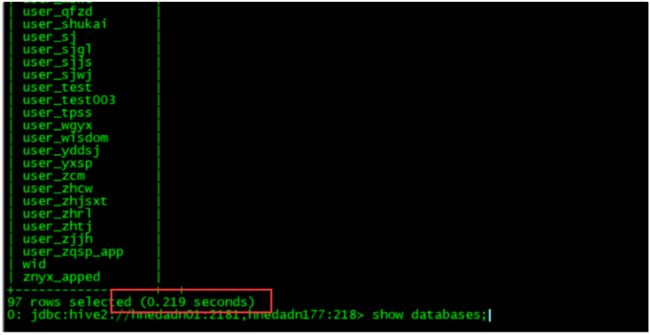
图6:5月8日13点30分 经过一个多小时的观察,集群的服务恢复正常。
三、故障总结
1、问题解决
临时措施:
1)清理表分区,将元数据库MySQL的压力释放;
永久措施:
1)重新评估构建表,将表设计重新建设,特别是分区的设定;
2)将表的清理规则进行设置,防止出现类似情况。
2、总结归纳
1)大数据租户仅清理了HDFS文件,未清理HIVE表分区信息;
2)大数据租户执行程序存在MySQL全表扫描情况;
3)大数据平台租户应用程序上线未纳入租户管理规范
4)大数据平台集群表分区元数据缺少监控。
四、避免问题出现的优化
如何设计执行MySQL的元数据库异常故障问题整改计划 ( 限定完成时间:略 )
1)大数据租户及时清理HIVE表分区信息,配置自动清理脚本;
2)大数据租户对执行程序进行调整,完成volte_mw表分区改造,设计为大分区+小分区;完成执行程序的改造;
3)大数据平台将租户应用程序上线纳入租户管理规范;
4)大数据平台将新增集群表分区元数据监控。