推荐系统6——基于标签的推荐方法
在之前我也看了很多人写的推荐系统的博客,理论的、算法的都有,多是个人的理解和感悟,虽然很深刻,但是对于自己而言还是不成系统,于是我参考大牛项亮编著的《推荐系统实践》将该领域知识系统整理一遍,与大家一起学习。
本系列对应的代码请查看https://github.com/wangyuyunmu/Recommended-system-practice
前面总结了基于用户行为数据的推荐方法——协同过滤、隐语义、图模型,冷启动——基于物品内容、用户注册信息等,本篇总结基于标签的推荐方法。
目录
- 1,推荐系统的方法分类
- 2,标签系统中的推荐问题
-
- 2.1 如何基于标签推荐
-
- 2.1.1 实验设计
- 2.1.2 基本算法
- 2.1.3 图模型算法
- 2.2 如何给用户推荐标签
-
- 2.2.1 为什么给用户推荐标签
- 2.2.2 推荐标签
1,推荐系统的方法分类
推荐系统的目的是联系用户的兴趣和物品,这种联系需要依赖不同的媒介。
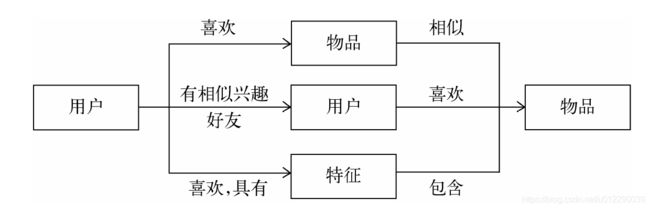
第一种方式是利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品,这就是基于物品的算法。
第二种方式是利用和用户兴趣相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品,这是基于用户的算法。
第三种重要的方式是通过一些特征(feature)联系用户和物品,给用户推荐那些具有用户喜欢的特征的物品。这里的特征有不同的表现方式,比如可以表现为物品的属性集合(比如对于图书,属性集合包括作者、出版社、主题和关键词等),也可以表现为隐语义向量(latent factor vector),这可以通过前面提出的隐语义模型习得到。
本文总结的是一种特征表示方式——标签。
2,标签系统中的推荐问题
用户用标签来描述对物品的看法,因此标签是联系用户和物品的纽带,也是反应用户兴趣的重要数据源。根据给物品打标签的人的不同,标签应用一般分为两种:一种是让作者或者专家给物品打标签;另一种是让普通用户给物品打标签,也就是UGC(User Generated Content,用户生成的内容)的标签应用,本文主要讨论UGC的标签应用。
标签系统的最大优势在于可以发挥群体的智能,获得对物品内容信息比较准确的关键词描述,而准确的内容信息是提升个性化推荐系统性能的重要资源。
标签系统中的推荐问题:
1)如何利用用户打标的行为为其推荐物品。(基于标签的推荐)
2)如何在用户打标签时,为其推荐合适该物品的标签。(推荐标签)
2.1 如何基于标签推荐
一个用户标签行为的数据集一般由一个三元组的集合表示,其中记录(u, i, b) 表示用户u给物品i打上了标签b。当然,用户的真实标签行为数据远远比三元组表示的要复杂,比如用户打标签的时间、用户的属性数据、物品的属性数据等。但是本章为了集中讨论标签数据,只考虑上面定义的三元组形式的数据,即用户的每一次打标签行为都用一个三元组(用户、物品、标签)表示。
2.1.1 实验设计
本节将数据集随机分成10份。这里分割的键值是用户和物品,不包括标签。也就是说,用户对物品的多个标签记录要么都被分进训练集,要么都被分进测试集,不会一部分在训练集,另一部分在测试集中。评价指标包括准确率、召回率、覆盖率、多样性、新颖性。
其中多样性:
D i v e r s i t y = 1 − ∑ i ∈ R ( u ) ∑ j ∈ R ( u ) , j ≠ i S i m ( i t e m _ t a g s [ i ] , i t e m _ t a g s [ j ] ) ⟮ 2 ∣ R ( u ) ∣ ⟯ Diversity=1-\frac{\sum_{i\in{R(u)}}\sum_{j\in{R(u)},j\neq i}Sim(item\_tags[i],item\_tags[j])}{\lgroup_{2}^{|R(u)|}\rgroup} Diversity=1−⟮2∣R(u)∣⟯∑i∈R(u)∑j∈R(u),j=iSim(item_tags[i],item_tags[j])
上式是一个用户推荐列表的多样性,计算每个推荐item之间的相似性之和。Sim表示两个物品item之间的余弦相似度,item用tag表示,其中tag用item打标tag的次数表示权重,分母是组合公式。系统的多样性是所有用户推荐多样性的平均值。
新颖度:
A v e r a g e P o p u l a r i t y = ∑ u ∑ i ∈ R ( u ) l o g ( 1 + i t e m _ p o p ( i ) ∑ u ∑ i ∈ R ( u ) 1 AveragePopularity = \frac{\sum_u\sum_{i\in{R(u)}}log(1+item\_pop(i)}{\sum_u \sum_{i\in R(u)}1} AveragePopularity=∑u∑i∈R(u)1∑u∑i∈R(u)log(1+item_pop(i)推荐结果的平均热度,其中流行度item_pop(i)表示为这个用户打标签的用户数量。
2.1.2 基本算法
1)统计每个用户常用的标签
2)对于每个标签,统计被其打标最多的物品
3)对于一个用户,找到用户的常用标签,找到这些标签最热门的物品推荐给用户。
(是不是跟用户的注册信息推荐思路有点像)
根据上面的思路,很自然的得到以下公式:
p ( u , i ) = ∑ b n u , b n b , i p(u,i)=\sum_bn_{u,b}n_{b,i} p(u,i)=b∑nu,bnb,in_{u,b}表示用户u打标b的数量,n_{b,i}表示物品i被打标b的数量。
统计user_tags和tag_items
user_tags, tag_items = {}, {}
for user in train:
user_tags[user] = {}
for item in train[user]:
for tag in train[user][item]:
if tag not in user_tags[user]:
user_tags[user][tag] = 0
user_tags[user][tag] += 1
if tag not in tag_items:
tag_items[tag] = {}
if item not in tag_items[tag]:
tag_items[tag][item] = 0
tag_items[tag][item] += 1
def GetRecommendation(user):
# 按照打分推荐N个未见过的
if user not in user_tags:
return []
seen_items = set(train[user])
item_score = {}
for tag in user_tags[user]:
for item in tag_items[tag]:
if item in seen_items:
continue
if item not in item_score:
item_score[item] = 0
item_score[item] += user_tags[user][tag] * tag_items[tag][item]
item_score = list(sorted(item_score.items(), key=lambda x: x[1], reverse=True))
return item_score[:N]
结果
Metric: {'Precision': 0.33, 'Recall': 0.54, 'Coverage': 3.32, 'Diversity': 0.7891701006679263, 'Popularity': 2.3416}
改进1,热度加权
以上算法很明显会倾向于热门的标签对应的热门物品,借用IF-IDF的思想对热门标签进行惩罚,如下式所示,方便理解,这里可以把用户与标签看做文章与词的关系。
p ( u , i ) = ∑ b n u , b l o g ( 1 + n b ( u ) ) n b , i p(u,i)=\sum_b\frac{n_{u,b}}{log(1+n_b^{(u)})}n_{b,i} p(u,i)=b∑log(1+nb(u))nu,bnb,i分子是打过标签b的用户数量对数。
def GetRecommendation(user):
# 按照打分推荐N个未见过的
if user not in user_tags:
return []
seen_items = set(train[user])
item_score = {}
for tag in user_tags[user]:
for item in tag_items[tag]:
if item in seen_items:
continue
if item not in item_score:
item_score[item] = 0
item_score[item] += user_tags[user][tag] * tag_items[tag][item] / tag_pop[tag]
item_score = list(sorted(item_score.items(), key=lambda x: x[1], reverse=True))
return item_score[:N]
实验结果:
Metric: {'Precision': 0.38, 'Recall': 0.62, 'Coverage': 16.84, 'Diversity': 0.8817850754900254, 'Popularity': 1.324168}
同理对物品item进行惩罚。
p ( u , i ) = ∑ b n u , b l o g ( 1 + n b ( u ) ) n b , i l o g ( 1 + n i u ) p(u,i)=\sum_b\frac{n_{u,b}}{log(1+n_b^{(u)})}\frac{n_{b,i}}{log(1+n_i^{u})} p(u,i)=b∑log(1+nb(u))nu,blog(1+niu)nb,i
def GetRecommendation(user):
# 按照打分推荐N个未见过的
if user not in user_tags:
return []
seen_items = set(train[user])
item_score = {}
for tag in user_tags[user]:
for item in tag_items[tag]:
if item in seen_items:
continue
if item not in item_score:
item_score[item] = 0
# item_score[item] += user_tags[user][tag] * tag_items[tag][item] / tag_pop[tag] / math.log(item_pop[item]+1)
item_score[item] += user_tags[user][tag] * tag_items[tag][item] / tag_pop[tag] / item_pop[item]
item_score = list(sorted(item_score.items(), key=lambda x: x[1], reverse=True))
return item_score[:N]
结果:
Metric: {'Precision': 0.14, 'Recall': 0.23, 'Coverage': 19.4, 'Diversity': 0.8598994786758158, 'Popularity': 0.786166}
改进2,标签扩散
在根据用户u常用的标签b找到高频的item。但是对于新用户,标签比较少,需要对标签进行扩展。
标签扩展的本质是找到相似标签。常用的是主题模型,找到相似的标签b进行推荐。当然也有相对简单的方法,比如基于邻域统计的方法,计算相似度。
# 1. 计算标签之间的相似度
item_tag = {}
for user in train:
for item in train[user]:
if item not in item_tag:
item_tag[item] = set()
for tag in train[user][item]:
item_tag[item].add(tag)
tag_sim, tag_cnt = {}, {}
for item in item_tag:
for u in item_tag[item]:
if u not in tag_cnt:
tag_cnt[u] = 0
tag_cnt[u] += 1
if u not in tag_sim:
tag_sim[u] = {}
for v in item_tag[item]:
if u == v:
continue
if v not in tag_sim[u]:
tag_sim[u][v] = 0
tag_sim[u][v] += 1
for u in tag_sim:
for v in tag_sim[u]:
tag_sim[u][v] /= math.sqrt(tag_cnt[u] * tag_cnt[v])
# 2. 为每个用户扩展标签
user_tags = {}
for user in train:
if user not in user_tags:
user_tags[user] = {}
for item in train[user]:
for tag in train[user][item]:
if tag not in user_tags[user]:
user_tags[user][tag] = 0
user_tags[user][tag] += 1
expand_tags = {}
for user in user_tags:
if len(user_tags[user]) >= M:
expand_tags[user] = user_tags[user]
continue
# 不满M个的进行标签扩展
expand_tags[user] = {}
seen_tags = set(user_tags[user])
for tag in user_tags[user]:
for t in tag_sim[tag]:
if t in seen_tags:
continue
if t not in expand_tags[user]:
expand_tags[user][t] = 0
expand_tags[user][t] += user_tags[user][tag] * tag_sim[tag][t]#相关性加权,生成新的tag权值
expand_tags[user].update(user_tags[user])
expand_tags[user] = dict(list(sorted(expand_tags[user].items(), key=lambda x: x[1], reverse=True))[:M])
结果
Metric: {'Precision': 0.33, 'Recall': 0.54, 'Coverage': 3.36, 'Diversity': 0.7883151626640105, 'Popularity': 2.338411}
测试结果与书中不同,这可能是数据集差异造成的,因为我使用的Delicious数据集的描述与书中描述的有显著差异。用户数量:书中的描述11200,本实验1867;标签数:书中42233,本实验53388等等。
2.1.3 图模型算法
首先,我们需要将用户打标签的行为表示到一张图上。我们知道,图是由顶点、边和边上的权重组成的。而在用户标签数据集上,有3种不同的元素,即用户、物品和标签。因此,我们需要定义3种不同的顶点,即用户顶点、物品顶点和标签顶点。然后,如果我们得到一个表示用户u给物品i打了标签b的用户标签行为(u,i,b)。
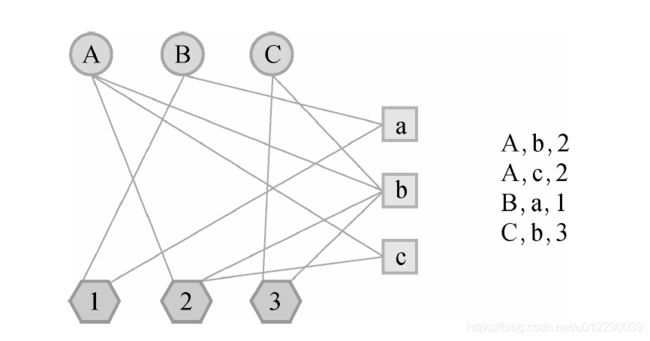
用户对物品的兴趣公式如下: p ( i ∣ u ) = p ( i ∣ b ) p ( b ∣ u ) p(i|u)=p(i|b)p(b|u) p(i∣u)=p(i∣b)p(b∣u)这个公式假定用户对物品的兴趣通过标签传递,因此这个公式可以通过一个比本节前面介绍的图更简单的图建模(记为 SimpleTagGraph)。给定用户标签行为记录(u,i,b),SimpleTagGraph会增加两条有向边,一条由用户节点v(u)指向标签节点v(b),另一条由标签节点v(b)指向物品节点v(i)。从这个定义可以看到,SimpleTagGraph相对于前面提到用户—物品—标签图少了用户节点和
物品节点之间的边。
利用前面讲过的图模型算法PersonalRank就可以进行优化。
2.2 如何给用户推荐标签
2.2.1 为什么给用户推荐标签
1)方便用户输入标签。提高用户打标签的参与度。
2)提高标签质量。同一个语义不同的用户可能用不同的词语来表示。
2.2.2 推荐标签
总共大概有4中方法
第一种:推荐最热门的标签。
# 统计tags
tags = {}
for user in train:
for item in train[user]:
for tag in train[user][item]:
if tag not in tags:
tags[tag] = 0
tags[tag] += 1
tags = list(sorted(tags.items(), key=lambda x: x[1], reverse=True))[:N]
N=10,M=10,结果:
Average Result (M=10, N=10): {'Precision': 0.844, 'Recall': 6.607000000000001}
第二种:给用户推荐物品i上最热门的标签
# 统计user_tags
user_tags = {}
for user in train:
user_tags[user] = {}
for item in train[user]:
for tag in train[user][item]:
if tag not in user_tags[user]:
user_tags[user][tag] = 0
user_tags[user][tag] += 1
user_tags = {k: list(sorted(v.items(), key=lambda x: x[1], reverse=True))
for k, v in user_tags.items()}
def GetRecommendation(user, item):
return user_tags[user][:N] if user in user_tags else []
Average Result (M=10, N=10): {'Precision': 1.6150000000000002, 'Recall': 7.874999999999998}
第三种:给用户推荐他经常使用的标签
# 统计user_tags
user_tags = {}
for user in train:
user_tags[user] = {}
for item in train[user]:
for tag in train[user][item]:
if tag not in user_tags[user]:
user_tags[user][tag] = 0
user_tags[user][tag] += 1
user_tags = {k: list(sorted(v.items(), key=lambda x: x[1], reverse=True))
for k, v in user_tags.items()}
N=10,M=10,结果:
Average Result (M=10, N=10): {'Precision': 3.168, 'Recall': 24.7}
第四种:前面两种的融合,分别基于user和item的算法计算,然后进行两者加权。
# 统计user_tags
user_tags = {}
for user in train:
user_tags[user] = {}
for item in train[user]:
for tag in train[user][item]:
if tag not in user_tags[user]:
user_tags[user][tag] = 0
user_tags[user][tag] += 1
# 统计item_tags
item_tags = {}
for user in train:
for item in train[user]:
if item not in item_tags:
item_tags[item] = {}
for tag in train[user][item]:
if tag not in item_tags[item]:
item_tags[item][tag] = 0
item_tags[item][tag] += 1
def GetRecommendation(user, item):
tag_score = {}
if user in user_tags:
max_user_tag = max(user_tags[user].values())
for tag in user_tags[user]:
if tag not in tag_score:
tag_score[tag] = 0
tag_score[tag] += (1 - alpha) * user_tags[user][tag] / max_user_tag
if item in item_tags:
max_item_tag = max(item_tags[item].values())
for tag in item_tags[item]:
if tag not in tag_score:
tag_score[tag] = 0
tag_score[tag] += alpha * item_tags[item][tag] / max_item_tag
return list(sorted(tag_score.items(), key=lambda x: x[1], reverse=True))[:N]
alpha=0.1
Average Result (M=10, N=10): {'Precision': 3.136, 'Recall': 24.479999999999997}
加权的方法效果要好,所以很多应用在给用户推荐标签时会直接给出用户最常用的标签,以及物品最经常被打的标签。
不过,前面提到的基于统计用户常用标签和物品常用标签的算法有一个缺点,就是对新用户或者不热门的物品很难有推荐结果。解决这一问题有两个思路。
第一个思路是从物品的内容数据中抽取关键词作为标签。这方面的研究很多,特别是在上下文广告领域。
第二个思路是针对有结果,但结果不太多的情况。比如《MongoDB权威指南》一书只有一个用户曾经给它打过一个标签nosql,这个时刻可以做一些关键词扩展,加入一些和nosql相关的标签,比如数据库、编程等。实现标签扩展的关键就是计算标签之间的相似度。