论文阅读——Adversarial Eigen Attack on Black-Box Models
Adversarial Eigen Attack on Black-Box Models
作者:Linjun Zhou, Linjun Zhou
攻击类别:黑盒(基于梯度信息),白盒模型的预训练模型可获得,但训练数据和微调预训练模型的数据不可得(这意味着模型的网络结构和参数信息可以获得)、目标攻击+非目标攻击
白盒+黑盒组合使用,白盒利用了中间表示,黑盒利用了输出得分。
- 疑问
Q1: 基于梯度信息生成对抗样本,如何保证迁移能力
A1: 似乎没有像常规方法一样考虑迁移性
Q2: 预训练模型选的啥?
A2: 用不到预训练模型
解决的问题:
替代模型的训练需要已知训练数据+降低查询量+保证扰动小
- 替代模型的训练需要已知训练数据:白盒模型的特征表示和黑盒模型的输出概率得分;
- 降低查询量:根据方向当属估计梯度减少梯度估计采样的样本,使用截断奇异值确定进一步降低查询量;
- 保证扰动小:每次扰动的寻优都约束到 L 2 L_2 L2范数球上。
黑盒攻击现状
黑盒攻击分为两类:
基于梯度估计的对抗攻击: 描述了一个纯黑盒攻击设置,其中可用的信息只是黑盒模型的输入和输出。在此设置中使用的常用技术是零阶优化[8]。与白盒攻击不同的是,黑盒攻击中不存在与网络参数相关的梯度信息。梯度需要通过采样不同方向的扰动和汇总与输出相关的某个损失函数的相对变化来估计。
基于替代模型(substitute model)的对抗攻击:使用来自训练数据集的侧信息。通常,在给定的训练数据集上训练一个替代的白盒模型。
方案概述:
将白盒攻击和黑盒攻击相结合。通过将白盒模型的中间表示到黑盒模型输出的映射看作一个黑盒函数,在表示空间上形成一个替代的黑盒攻击设置,可以应用黑盒攻击的常见做法。另一方面,从原始输入到中间表示层的映射是预训练模型的一部分,可以看作是一个白盒设置。值得注意的是,该框架可以处理两个模型相同或不同的分类类别,增强了其实际应用场景。使用预训练白盒网络的表示空间有助于提高黑盒模型的攻击效率的主要原因是,深度神经网络的较低层,即表示学习层,在不同的数据集或数据分布之间是可转移的。
白盒模型:
G ( x ) = g ∘ h ( x ) G(x) = g \circ h(x) G(x)=g∘h(x), h ( x ) h(x) h(x)表示原始输入到低维表示空间的映射, g g g表示输出概率的表示空间映射, g : R m → [ 0 , 1 ] c w g:{\mathbb{R}^m} \to {[0,1]^{{c_w}}} g:Rm→[0,1]cw, c w {c_w} cw表示G输出类别的数量;
黑盒模型:
F : R n → [ 0 , 1 ] c b F:{\mathbb{R}^n} \to {[0,1]^{{c_b}}} F:Rn→[0,1]cb, c b {c_b} cb表示F输出类别的数量, c b {c_b} cb和 c w {c_w} cw可能不相等。
- 疑问
Q1: 如何对齐白盒模型和黑盒模型的输出概率分布的?存在两种情况:黑盒模型和白盒模型的输出概率分布不一致或者输出概率类别的长度可能不同?
A1: 为解决上述问题,作者并没有使用白盒模型的参数,而是使用白盒模型的中间表示 z = h ( x ) z = h(x) z=h(x)和新的映射函数 g ~ : R m → [ 0 , 1 ] c b \tilde g:{\mathbb{R}^m} \to {[0,1]^{{c_b}}} g~:Rm→[0,1]cb(被攻击黑盒模型的输出的表示空间)。类比白盒模型的定义,若 g ~ \tilde g g~存在,则可获得黑盒模型 F = g ~ ∘ h ( x ) F = \tilde g \circ h(x) F=g~∘h(x)。
基于上述定义,黑盒攻击的优化目标函数为:
min δ p F ( y ∣ x + δ ) ⇒ min δ p g ∘ h ( y ∣ x + δ ) s . t . , ∣ ∣ δ ∣ ∣ 2 < ρ \mathop {\min }\limits_\delta {p_F}(y|x + \delta ) \Rightarrow \mathop {\min }\limits_\delta {p_{g \circ h}}(y|x + \delta ){\text{ }}s.t.,{\text{ }}||\delta |{|_2} < \rho δminpF(y∣x+δ)⇒δminpg∘h(y∣x+δ) s.t., ∣∣δ∣∣2<ρ
x t + 1 = x t − ε ∇ x [ F ( x ; θ ) ] {x_{t + 1}} = {x_t} - \varepsilon {\nabla _x}[F(x;\theta )] xt+1=xt−ε∇x[F(x;θ)] (1)
∇ x [ F ( x ; θ ) ] {\nabla _x}[F(x;\theta )] ∇x[F(x;θ)]通过采样一些扰动和汇总输出的相对变化来估计,但是在每次迭代时估计梯度,会消耗的大量的样本,这不利于提升攻击效率。为解决这一问题作者将梯度 ∇ x [ F ( x ; θ ) ] {\nabla _x}[F(x;\theta )] ∇x[F(x;θ)]拆分如下:
∇ x [ F ( x ; θ ) ] = J h ( x ) T ∇ z [ g ~ ( z ; θ ~ ) y ] {\nabla _x}[F(x;\theta )] = {J_h}{(x)^T}{\nabla _z}[\tilde g{(z;\tilde \theta )_y}] ∇x[F(x;θ)]=Jh(x)T∇z[g~(z;θ~)y] (2)
J h ( x ) {J_h}{(x)} Jh(x)是关于 h h h的 m ∗ n m*n m∗n雅克比矩阵 ∂ ( z 1 , z 2 , ⋯ , z m ) ∂ ( x 1 , x 2 , ⋯ , x n ) \frac{{\partial ({z_1},{z_2}, \cdots ,{z_m})}}{{\partial ({x_1},{x_2}, \cdots ,{x_n})}} ∂(x1,x2,⋯,xn)∂(z1,z2,⋯,zm), z z z是特征空间表示,也就是 h h h的输出。但 ∇ z [ g ~ ( z ; θ ~ ) y ] {\nabla _z}[\tilde g{(z;\tilde \theta )_y}] ∇z[g~(z;θ~)y]中 g ~ \tilde g g~是黑盒模型,因此需要采样估计 ∇ z [ g ~ ( z ; θ ~ ) y ] {\nabla _z}[\tilde g{(z;\tilde \theta )_y}] ∇z[g~(z;θ~)y]。 y y y表示 g ~ \tilde g g~输出的第 y y y个成分。
根据方向倒数的定义可知,
∇ z [ g ~ ( z ; θ ~ ) y ] = ∑ i = 1 m ( ∂ g ~ ( z ; θ ~ ) y ∂ l ⃗ i ∣ z ⋅ l ⃗ ) , l ⃗ 1 , l ⃗ 2 , ⋯ , l ⃗ m are orthogonal {\nabla _z}[\tilde g{(z;\tilde \theta )_y}] = \sum\limits_{i = 1}^m {(\frac{{\partial \tilde g{{(z;\tilde \theta )}_y}}} {{\partial {{\vec l}_i}}}{|_z} \cdot \vec l)} ,{{\vec l}_1},{{\vec l}_2}, \cdots ,{{\vec l}_m}{\text{ are orthogonal}} ∇z[g~(z;θ~)y]=i=1∑m(∂li∂g~(z;θ~)y∣z⋅l),l1,l2,⋯,lm are orthogonal (3)
我们可以通过每次迭代使用m个样本,从一组正交基中迭代地设置 z z z的扰动方向,来估计 ∇ z [ g ~ ( z ; θ ~ ) y ] {\nabla _z}[\tilde g{(z;\tilde \theta )_y}] ∇z[g~(z;θ~)y]。但是使用上述方法估计 ∇ z [ g ~ ( z ; θ ~ ) y ] {\nabla _z}[\tilde g{(z;\tilde \theta )_y}] ∇z[g~(z;θ~)y]会消耗巨大的查询预算。为解决这一问题,作者通过牺牲估计精度来降低查询量。具体而言,首先设计EigenBA算法来寻找表示空间的标准基,
l ⃗ i = J h ( x ) δ i {{\vec l}_i} = {J_h}(x){\delta _i} li=Jh(x)δi (4)
δ i {\delta _i} δi是原始输入空间上的扰动,会导致表示空间变成 l ⃗ i {{\vec l}_i} li。最优的扰动可求解为:
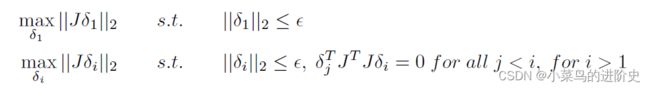
作者对上述等式求解获得最优的 δ 1 , δ 2 , ⋯ , δ m {\delta _1},{\delta _2}, \cdots ,{\delta _m} δ1,δ2,⋯,δm
因此,如果我们将扰动依次迭代采样到 δ 1 , δ 2 , ⋯ , δ m {\delta _1},{\delta _2}, \cdots ,{\delta _m} δ1,δ2,⋯,δm,则一步实际扰动 ∇ x [ F ( x ; θ ) ] {\nabla _x}[F(x;\theta )] ∇x[F(x;θ)]可以用公式2和式3来近似,并且,由于特征值的迹可能很小,即表征空间的扰动范数可能对具有相应特征向量方向的原始输入空间上的扰动不敏感。为了在不牺牲太多攻击效率的情况下减少查询数,作者只保留探测的top-K扰动, δ 1 , δ 2 , ⋯ , δ K {\delta _1},{\delta _2}, \cdots ,{\delta _K} δ1,δ2,⋯,δK。通过对雅可比矩阵J进行截断奇异值分解(SVD),只保留前K个分量,可以快速计算出 J T J {J^T}J JTJ的特征向量。
上述过程的伪代码如下:

迭代扰动寻优过程中的参数定义似乎不全!
实验
1、数据集:ImageNet、Cifar-10
2、对比方法:SimBA-DCT、Trans-FGM
3、评估指标:攻击一张样本的平均查询量、攻击成功率、对抗扰动的 L 2 {L_2} L2和 L ∞ {L_\infty } L∞范数
4、实验模块:不同查询量下非目标攻击和目标攻击的攻击性能测试+消融研究