8×8流水线乘法器(Verilog)
简介:
硬件描述语言的一个突出优点就是指令执行的并行性。多条语句能够在相同时钟周期内并行处理多个信号数据。在 Verilog 中,直接用乘号完成相乘过程,编译器在编译的时候也会把这个乘法表达式映射成默认的乘法器,但其构造不得而知。而且很多时候有些计算并不能在一个或两个时钟周期内执行完毕,如果每次输入的串行数据都需要等待上一次计算执行完毕后才能开启下一次的计算,那效率是相当低的。流水线就是解决多周期下串行数据计算效率低的问题。例如,在硬件设计中,可以直接调用 IP 核来生成一个高性能的乘法器。在位宽较小的时候,一个周期内就可以输出结果,位宽较大时也可以流水输出。在能满足要求的前提下,可以谨慎的用 * 或直接调用 IP 来完成乘法运算。但乘法器 IP 也有很多的缺陷,例如位宽的限制,未知的时序等。尤其使用乘号,会为数字设计的不确定性埋下很大的隐瞒。
原理:
流水线的基本思想是:把一个重复的过程分解为若干个子过程,每个子过程由专门的功能部件来实现。将多个处理过程在时间上错开,依次通过各功能段,这样每个子过程就可以与其他子过程并行进行。很多时候,常数的乘法都会用移位相加的形式实现,例如:
G = G << 1 ; // 即 G * 2
B = ( B << 2) + B ; // 即 B * 5
R = ( R << 6) + ( R << 3 ) + ( R << 2 ) + R // 即 R * 77
有时候数字电路在一个周期内并不能够完成多个变量同时相加的操作。所以数字设计中,最保险的加法操作是同一时刻只对 2 个数据进行加法运算,最差设计是同一时刻对 4 个及以上的数据进行加法运算。
和十进制乘法类似,计算 8 与 9 的相乘过程如下所示:
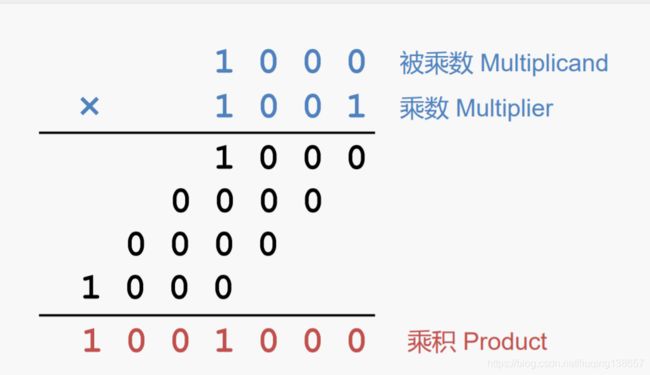
由此可知,被乘数按照乘数对应 bit 位进行移位累加,便可完成相乘的过程。
电路图:
设计文件代码:
module multi_pipe#(
parameter size = 8
)(
clk,
rst_n,
mul_a,
mul_b,
mul_en_in,
mul_en_out,
mul_out
);
input clk;
input rst_n;
input mul_en_in;
input [size-1:0] mul_a;
input [size-1:0] mul_b;
output reg mul_en_out;
output reg [size*2-1:0] mul_out;
reg [2:0] mul_en_out_reg;
always@(posedge clk or negedge rst_n)
if(!rst_n)begin
mul_en_out_reg <= 'd0;
mul_en_out <= 'd0;
end
else begin
mul_en_out_reg <= {mul_en_out_reg[1:0],mul_en_in};
mul_en_out <= mul_en_out_reg[2];
end
reg [7:0] mul_a_reg;
reg [7:0] mul_b_reg;
always @(posedge clk or negedge rst_n)
if(!rst_n) begin
mul_a_reg <= 'd0;
mul_a_reg <= 'd0;
end
else begin
mul_a_reg <= mul_en_in ? mul_a :'d0;
mul_b_reg <= mul_en_in ? mul_b :'d0;
end
wire [15:0] temp [size-1:0];
assign temp[0] = mul_b_reg[0]? {8'b0,mul_a_reg} : 'd0;
assign temp[1] = mul_b_reg[1]? {7'b0,mul_a_reg,1'b0} : 'd0;
assign temp[2] = mul_b_reg[2]? {6'b0,mul_a_reg,2'b0} : 'd0;
assign temp[3] = mul_b_reg[3]? {5'b0,mul_a_reg,3'b0} : 'd0;
assign temp[4] = mul_b_reg[4]? {4'b0,mul_a_reg,4'b0} : 'd0;
assign temp[5] = mul_b_reg[5]? {3'b0,mul_a_reg,5'b0} : 'd0;
assign temp[6] = mul_b_reg[6]? {2'b0,mul_a_reg,6'b0} : 'd0;
assign temp[7] = mul_b_reg[7]? {1'b0,mul_a_reg,7'b0} : 'd0;
reg [15:0] sum [3:0];//[size/2-1:1]
always @(posedge clk or negedge rst_n)
if(!rst_n) begin
sum[0] <= 'd0;
sum[1] <= 'd0;
sum[2] <= 'd0;
sum[3] <= 'd0;
end
else begin
sum[0] <= temp[0] + temp[1];
sum[1] <= temp[2] + temp[3];
sum[2] <= temp[4] + temp[5];
sum[3] <= temp[6] + temp[7];
end
reg [15:0] mul_out_reg;
always @(posedge clk or negedge rst_n)
if(!rst_n)
mul_out_reg <= 'd0;
else
mul_out_reg <= sum[0] + sum[1] + sum[2] + sum[3];
always @(posedge clk or negedge rst_n)
if(!rst_n)
mul_out <= 'd0;
else if(mul_en_out_reg[2])
mul_out <= mul_out_reg;
else
mul_out <= 'd0;
endmodule验证文件代码:
`timescale 1ns/1ps
`define clk_period 20
module multi_pipe_tb();
reg [7:0] mul_a;
reg [7:0] mul_b;
reg mul_en_in;
reg clk;
reg rst_n;
wire mul_en_out;
wire [15:0] mul_out;
multi_pipe u1(
.clk(clk),
.rst_n(rst_n),
.mul_a(mul_a),
.mul_b(mul_b),
.mul_en_in(mul_en_in),
.mul_en_out(mul_en_out),
.mul_out(mul_out)
);
initial clk = 1;
always # 10 clk = ~clk;
initial begin
rst_n = 0;
mul_a = 0;
mul_b = 0;
mul_en_in = 0;
#(`clk_period*200+1);
rst_n = 1;
#(`clk_period*10);
mul_a = 'd35;
mul_b = 'd20;
mul_en_in = 'd1;
repeat (100) begin
#(`clk_period);
mul_a = mul_a + 'd1;
mul_b = mul_b + 'd2;
mul_en_in = mul_en_in + 'd1;
end
$finish;
end
initial begin
$fsdbDumpfile("./multi_pipe_tb.fsdb");
$fsdbDumpvars(0,"multi_pipe_tb");
$fsdbDumpSVA();
end
endmodule 仿真波形:
![]()
数据在时钟驱动下不断串行输入,乘法输出结果延迟了 4 个时钟周期后,也源源不断的在每个时钟下无延时输出,完成了流水线式的工作。相对于一般不采用流水线的乘法器,乘法计算效率有了很大的改善。但是,流水线结构也消耗了大量的硬件存储资源(包括二维存储器),这是一个典型的用资源换效率的设计思路。所以,一个数字设计,是否采用流水线设计,需要从资源和效率两方面进行权衡。