万字长文,写给Android工程师的协程指南
这是一份写给Android工程师的协程指南,希望在平静的2023,给大家带来一些本质或者别样的理解。
1
引言
在 Android 的开发世界中,关于 异步任务 的处理一直不是件简单事。
面对复杂的业务逻辑,比如多次的异步操作,我们常常会经历回调嵌套的情况,对于开发者而言,无疑苦不堪言。
当 Kotlin协程 出现之后,上述问题可以说真正意义上得到了好的解法。其良好的可读性及api设计,使得无论是新手还是老手,都能快速享受到协程带来的舒适体验。
但越是使用顺手的组件,背后也往往隐藏着更复杂的设计。
故此,在本篇,我们将由浅入深,系统且全面的聊聊 Kotlin协程 的思想及相关问题,从而帮助大家更好的理解。
本篇没有难度定位、更多的是作为一个
Kotlin使用者的基本技术铺垫。
2
写在开始
大概在三年前,那时的我实习期间刚学会 Kotlin ,意气风发,协程Api 调用的也是炉火纯青,对外自称api调用渣渣工程师。
那时候的客户端还没这么饱和,也不像现在这样稳定。
那个时期,曾探寻过几次 Kotlin协程 的设计思想,比如看霍老师、扔物线视频、相关博客等。
但看完后处于一种,懂了,又似乎不是很懂的状态,就一直迷迷糊糊着。
记得后来去面试,有人问我,协程到底是什么?
我回答: 一个在
Kotlin上以 同步方式写异步代码 的线程框架,底层是使用了 线程池+状态机 的概念,诸如此类,巴拉巴拉。面试官: 那它到底和线程池有啥区别,我为啥不直接用线程池呢?
我心想:上面不是已经回答了吗,同步方式,爽啊!… 但奈何遭到了一顿白眼。
事后回想,他可能想问的是更深层,多角度的解释,但显然我只停留在使用层次,以及借着别人的几句碎片经验,冠冕堂皇、看似Easy。
直到现在为止,我仍然没有认真去看过协程的底层实现,真是何其的尴尬,再次想起,仍觉不安。
随着近几年对协程的使用以及一些cv经验,相关的api理解也逐渐像那么回事,也有些对Kt代码背后实现进行同步转换的经验。
故此,这篇文章也是对自己三年来的一份答卷。
当然网上对于协程的解析也有很多,无论是从原理或是顶层抽象概括,其中更是不乏优秀的文章与作者。
本文会尽量在这两者中间找到一个合适的折中点,并增加一些特别思考,即不缺深度,又能使初学者对于协程能够有较清晰明了的认知。
好了,让我们开始吧!
3
基础铺垫
在开始之前,我们先对基础做一些铺垫,从而便于更好的理解 Kotlin协程 。
线程
我们知道,线程是 cpu调度 的最小单元,每个cpu所能启动的线程数量往往也是有限的。
在常见的业务开发中,尽管大多数时候我们都是基于单线程,或者最多开启子线程去请求网络,与多线程的 [多] 似乎关系不大。但其实这也属于多线程的一种,不过是少任务的情况。但就算这样,线程在执行时的切换,也是存在这一些小成本,比如从主线程切到子线程去执行异步计算,完成后再从子线程切到主线程去执行UI操作,而这个切换的过程在学术上又被称之为 [上下文切换]。
协程
在维基百科中,是这样解释的:
协程是计算机程序的一类组件,推广了协作式多任务的子例程,允许执行被挂起与被恢复。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。协程更适合于用来实现彼此熟悉的程序组件,如协作式多任务、异常处理、事件循环、迭代器、无限列表和管道。
上面这些词似乎拆开都懂,但连在一起就不懂了。
说的通俗一点就是,协程指的是一种特殊的函数,它可以在执行到某个位置时 暂停 ,并 保存 当前的执行状态,然后 让出 CPU控制权,使得其他代码可以继续执行。当CPU再次调用这个函数时,它会从上次暂停的位置继续执行,而不是从头开始执行。从而使得程序在执行 长时间任务 时更加高效和灵活。
协作式与抢占式
这两个概念通常用于描述操作系统中多任务的处理方式。
• 协作式指的是 多个任务共享CPU时间 ,并且在没有主动释放CPU的情况下,任务不会被强制中断。相应的,在协作式多任务处理中,任务需要自己决定何时放弃CPU,否则将影响其他任务的执行。
• 抢占式指的是操作系统可以在没有任务主动放弃CPU的情况下,强制中断 当前任务,以便其他任务可以获得执行。这也就意味着,抢占式多任务通常是需要硬件支持,以便操作系统可以在必要时强制中断任务。
如果将上述概念带入到协程与线程中,当一个线程执行时,它会一直运行,直到被操作系统强制中断或者自己放弃CPU;而协程的协作式则需要协程之间互相配合协作,以便让其他协程也可以获得执行机会,通常情况下,这种协作关系是由应用层(开发者)自行控制。也就意味着相比线程,协程的切换与创建开销比较小,因为其并不需要多次的上下文切换,或者说,线程是真实的操作系统内核线程的隐射,而协程只是在应用层调度,故协程的切换与创建开销比较小。
协程与线程的区别
• 线程是操作系统调度的基本单位,一个进程可以拥有多个线程,每个线程独立运行,但它们共享进程的资源。线程切换的开销较大,且线程间的通信需要通过共享内存或消息传递等方式实现,容易出现资源竞争、死锁等问题。
• 协程是用户空间下的轻量级线程,也称为“微线程”。它不依赖操作系统的调度,而是由用户自己控制协程的执行。协程之间的切换只需要保存和恢复少量的状态,开销较小。协程通信和数据共享的方式比线程更加灵活,通常使用消息传递或共享状态的方式实现。
• 简单来说,协程是一种更加高效、灵活的并发处理方式,但需要用户 自己控制执行流程和协程间的通信 ,而线程则由操作系统负责调度,具有更高的并发度和更强的隔离性,但开销较大。在不同的场景下,可以根据需要选择使用不同的并发处理方式。
那Kotlin协程呢?
在上面,我们说了 线程 与 协程 ,但这个协程指的是 广义协程 这个概念,而不是 Kotlin协程 ,那如果回到 Kotlin协程 呢?
相信不少同学在学习 Kotlin协程 的时候,常常会看到很多人(包括官网)会将线程与协程拉在一起比较,或者经常也能看见一些实验,比如同时启动10w个线程与10w个协程,然后从结果上看两者差距巨大,线程看起来性能巨差,协程又无比的优秀。
此时就会有同学喊,你上个线程池与协程试试啊!用线程试谈什么公平(很有道理)。
ps: 如果你真的使用了线程池并且使用了schedule代替Thread.sleep(),会发现,线程比协程显然要更快。当然,这也并不难理解。
那协程到底是什么呢?它和线程池的区别呢?或者说协程的职责呢?
这里我们用 Android官方 的一句话来概括:
协程是一种并发设计模式,您可以在 Android 平台上使用它来 简化 异步执行的代码。协程是我们在 Android 上进行异步编程的推荐解决方案。
简单明了,协程就是用于 Android 上进行 异步编程 的推荐解决方案,或者说其就是一个 异步框架 ,仅此而已,别无其他。
那有些同学可能要问了,异步框架多了,为什么要使用协程呢?
因为协程的设计更加先进,比如我们可以同步代码写出类似异步回调的逻辑。这一点,也是Kotlin协程在Android平台最大的特点,即 简化异步代码。
相应的,Kotlin协程 具有以下特点:
• 轻量:您可以在单个线程上运行多个协程,因为协程支持挂起,不会使正在运行协程的线程阻塞。挂起比阻塞节省内存,且支持多个并行操作。
• 内存泄漏更少:使用结构化并发机制在一个作用域内执行多项操作。
• 内置取消支持:取消操作会自动在运行中的整个协程层次结构内传播。
• Jetpack 集成:许多 Jetpack 库都包含提供全面协程支持的扩展。某些库还提供自己的协程作用域,可供您用于结构化并发。
上述特点来自Android官网-Android上的Kotlin协程。
4
协程进展
注:如非特别标注,本文接下来的协程皆指Kotlin协程。
本小节,我们将看一下Kotlin协程的发展史,从而为大家解释kotlin协程的背景。

在 Kotlin1.6 之前,协程的版本通常与 kotlin 版本作为对应,但是 1.6 之后,协程的大版本就没有怎么更新了(目前最新是1.7.0-beta),反而是 Kotlin 版本目前最新已经 1.8.10 。
5
基本示例
在开始之前,我们还是用一个最基本的示例看一下协程与往常回调写法的区别,在哪里。
比如,我们现在有这样一个场景,需要请求网络,获取数据,然后显示到UI中。
回调写法

如上所示,创建了一个线程t1,并在其中调用了 getMessage() 方法,该方法我们使用 Thread.sleep() 模拟网络请求,然后返回一个String数据, 最后使用 handler 将当前要执行的任务发送到主线程去执行从而实现线程切换。
协程写法

如上所示,创建了一个协程作用域,并启动了一个新的子协程c1,该协程内部调用了 getMessages() 方法,用于获得一个 String类型 的消息。然后调用 showMessage() 方法,显示刚才获取的消息。在相应的 getMessages() 方法上,我们增加了 suspend 标记,并在内部使用withContext(Dispatcher.IO) 将当前上下文环境切换到IO协程中,用于延迟等待(假设网络请求),最终返回该结果。
在不谈性能的背景下,上述这两种方式,无疑是协程的代码更加直观简洁,毕竟同步的写法去写异步,这没什么可比性,当然我们也允许部分的性能损失。
6
挂起与恢复
站在初学者的视角,当聊到挂起与恢复,开发者到底想了解什么?
什么是挂起恢复?挂起是挂起什么?挂起线程吗?还是挂起一个函数?恢复又是具体指什么?又是如何做到恢复的呢?
基础概念
在标准的解释中,如下所示:
在协程中,当我们的代码执行到某个位置时,可以使用特定的关键字来暂停函数的执行,同时保存函数的执行状态,这个过程叫做 [挂起],挂起操作会将控制器交还给调用方,调用方可以继续执行其他任务。
当再次调用被挂起的函数时,它会从上一次暂停的位置开始继续执行,这个过程称为 [恢复]。在恢复操作之后,被挂起的函数会继续执行之前保存的状态,从而可以在不重新计算的情况下继续执行之前的逻辑。
如果切换到 Kotlin 的世界中中,这个特定的关键字就是 suspend 。但并不是说加了这个关键字就一定会挂起,suspend 只是作为一个标记,用于告诉编译器,该函数可能会挂起并暂停执行(即该函数可能会执行耗时操作,并且好事期间会暂停执行并等待耗时操作完成,同时需要将控制权返回给调用方),但至于要不要挂起及保存函数当前的执行状态,最终还是要取决于函数内部是否满足条件。
那用程序员的语言该怎么理解呢?我们用一段代码举例:

• 当我们的程序运行到 coroutineScope.launch(Dispatchers.Main) 时,此时会创建一个新协程,并将这个协程放入默认的协程调度器(即Main调度器),同时当前新创建的协程也会成为 coroutineScope 的子协程。
• 当执行到 getNetMssage() 方法时,此时遇到了 withContext(Dispatchers.IO) ,此时会切换当前协程的上下文到IO调度器(可以理解将当前协程放入IO线程池中执行),此时协程将被挂起,然后我们当前 withContext() 被挂起的状态会通知给外部的调用者,并将当前的状态保存到协程的上下文中,直到IO操作完成。
• 当遇到 delay(1000) 时,此时再次挂起(这里不是切换线程,而是使用了协程的调度算法),并保存当前的函数状态;
• 当 delay(1000) 结束后,再次恢复到先前所在的IO调度器,并开始返回 “123”;
• 当上述逻辑执行完成后,此时 withContext() 会将协程的调度器再次切换到之前开始时的调度器(这里是Main),并恢复之前的函数状态;
• 此时我们获得了 getNetMssage() 的返回值,继续执行 showMessage() 。
挂起函数
在上面我们聊到了 Kotlin 的挂起函数,与相关的 挂起 与 恢复 。那 suspend 标志到底做了什么呢?
本小节,我们将就这个问题,从字节码层,展开分析。
我们先看一下 suspend 方法是如何被编译器识别的?如下代码所示:

不难发现,我们带有suspend的函数最终会被转变为一个带 Continutaion 参数,并且返回值为Object(可null)的函数。
上述示例中,原函数没带返回值,你也可以使用带返回值的原函数,结果也是与上述一致。
1. Continucation 是什么?为什么要携带它呢?
在前文中,我们已经提及,suspend 只是一个标志,它的目的是告诉编译器可能会挂起,类似与我们开发中常使用的注解一样,但又比注解更加强大,suspend 标志是编译器级别,而注解是应用级别。从原理上来看,那最终的代码运行时应该怎么记住这些状态呢,或者怎么知道这个方法和其他方法不一样?故此,kotlin编译器 会对带有 suspend 的方法在最终的字节码生成上进行额外更改,这个过程又被称作 CPS转换 (下面会再解释),如下所示:

在字节码中,我们原有的函数方法参数中会再增加一个 Continucation ,而 Continuation 就相当于一个参数传递的纽带(或者你也可以理解其就是一个 CallBack ),负责保存函数的执行状态、执行 挂起与恢复 操作,具体如下:

context 参数类似于 Android 开发中的 context 一样,其代表了当前的配置,对使用协程的同学而言,context就相当于当前协程所运行的环境与参数 ,而 resumeWith() 则是负责对我们函数方法进行挂起与恢复(这块我们先这样理解即可)。
1 什么是CPS转换?
CPS(Continuation Passing Style)转换是一种将函数转换为回调函数的编程技术。在 CPS 转换中,一个函数不会像通常那样直接返回结果,而是接受一个额外的回调函数作为参数,用于接收函数的结果。这个回调函数本身也可能接受一个回调函数,形成一个连续的回调链。这种方式可以避免阻塞线程,提高代码的并发性能。
比如,协程通过 CPS 转换来实现异步编程。具体来说,协程在被挂起时,会将当前的执行状态保存到一个回调函数(即挂起函数的 Continuation)中,然后将控制权交回给调用方。当协程准备好恢复时,它会从回调函数中取回执行状态,继续执行。这种方式可以使得异步代码的逻辑更加清晰和易于维护。
2. 为什么还要增一个 Object 类型返回值呢?
这块的直接解释比较麻烦,但是我们可以先思考一下,代码运行时,该怎么知道该方法真的被挂起呢?难道是增加了suspend就要被挂起吗?
故此,还是需要一个返回值,用于确定,该挂起函数是否真的被挂起。
在IDE中,对于使用了suspend的方法而言,如果内部没有其他挂起函数,那么编译器就会提示我们移除suspend标记,如下所示:

3. 为什么返回值类型是Object?
对于挂起函数而言,在协程,是否真的被挂起,通过函数返回值来确定,但相应的,如果我们有挂起函数需要具备返回类型呢?那如果该函数没有挂起呢?如下示例所示:

对于挂起函数而言,返回值有可能是 COROUTINE_SUSPENDED、Unit.INSTANCE 或者最终返回我们方法需要的返回类型结果,所以采用 Object 作为返回值以适应所有结果。
深入探索
在上面,我们看到了 suspend 在底层的转换细节,那回到挂起函数本质上,它到底是怎么做到 **挂起 ** 与 恢复 的呢?
故此,本小节,我们将就着这个问题,从字节码层次,展开分析,力求流程完整明了,不过相对而言可能有点繁琐。
如下代码所示:

这是一段用于将文件复制到指定文件的示例代码,具体伪字节码如下:

上述的步骤实在是难读,思路整理起来比较绕圈,不过还是建议开发者多理解几遍。
上述的步骤如下:
当左侧 main() 方法开始执行时,因为示例中使用的 runBlocking(),其需要传递一个函数式接口对象,通常我们会以 lambda表达式 的形式去实例化这个函数对象,然后在其中写入我们的业务代码。
所以根据最终的字节码对比,我们的lambda会被转化为如下的形式:

接着当我们的函数被调用时,会触发 invoke() 方法,即我们的函数体开始执行,开始进入我们的业务代码中。因为 invoke() 需要返回一个Object(因为我们的函数体本身也是suspend),这时候,会先创建一个 Continuation 对象,用于执行协程体逻辑,然后去调用 invokeSuspend() 方法从而获得本次的执行结果。
这里为什么要再去创建一个 Continuation?不是在runBlocking()里已经利用lambda表达式实例化了函数对象了吗?
不知道是否会有同学有这个疑问,所以这里依然需要解释一遍。
我们知道,在 kotlin 中,
lambda是匿名内部类的一种实例化方式(简化),所以这里只是给runBlocking()函数传递了所需要的方法参数。但是这个 lambda 内部的invoke()依然是挂起函数(因为增加过suspend),所以这里的匿名内部类实际上也是实现了Continuation(默认的只有Funcation1,2,3等等),为了便于底层调用invoke()时传递Continuation,否则后续挂起恢复流程就断了。相应的,为了延续invoke()里的挂起函数流程,编译器在当前匿名类内部又创建了一个 **anonymous constructor(无类型) ** 的内部类(实际上是继承自SuspendLambda),从而在其ivokeSuspend()里执行当前挂起函数的状态机。所以来说,大家可以理解我们传递的 lambda 相当于一个入口,但是其内部(即invoke)的触发方法,又是一个 挂起函数 ,这也就是为什么
invoke()里需要创建Continuation,以及为什么invoke()方法参数里需要有continuation的原因,以及为什么字节码中会出现 new Function2((Continuation) null) ,Continuation为null 的情况,因为它压根没有continuation啊(不在挂起函数内部)。这里的解释稍许有些啰嗦,但这对于理解全流程将非常有用,如果不是很理解,建议多读几遍。
在 invokeSuspend() 方法里,即正式进入了函数的状态机,这里的状态标记使用了一个 int 类型的 label 表示。
默认执行 case 0,因为我们接下来要进入 copyFileTo() 方法,而该方法也是一个挂起函数,所以执行该方法后会获得一个返回状态,用于判断该函数是否真的已经挂起。如果返回值是 COROUTINE_SUSPENDED,则证明该函数已经挂起,然后直接 return 当前函数的挂起状态(相当于告诉父callback,当前我内部已经在忙了,你可以先执行自己的事了,等我执行完再通知你),否则继续执行当前剩余逻辑。
当 copyFileTo() 执行结束后,会再次触发当前 invokeSuspend(),因为我们在 case0 里已经更新了label为1,然后正常执行接下来的流程。
我们再去看一下 copyFileTo() 方法,我们在字节码中可以看到,其默认先创建了当前的 ContinuationImpl() ,并在初始化时将父 Continuation 也保存在其中,接着进入状态机开始执行逻辑,因为我们在该方法里有使用 withContext() 切换到IO调度器,所以这里也需要获取 withContext() 的挂起状态,如果成功挂起,则直接 return 当前状态,类似上述 invokeSuspend() 里的流程。
需要注意的,我们 withContext() 范围内,虽然经历了CPS转换,但因为不存在其他挂起函数,所以并不会再返回是否挂起,而是直到我们的逻辑执行结束 ,从而触发 withContext() 内部去调用 resumeWith(),从而恢复外部 copyFileTo() 的执行,重复此流程,从而恢复 runBlocking() 内部的继续执行,然后拿到我们的最终结果。
总结
关于Kotlin协程的挂起与恢复,从字节码去看,核心的 continuation 似乎有点像 callback 的嵌套,但相比 callback ,协程做的更加完善。比如当触发挂起函数调用时,会进入其内部对应的状态机,从而触发状态流转。并且为了避免了 callback 的 重复创建,而每一个挂起函数内部都会复用当前已创建好的 continuation。
比如说,对于挂起函数,编译器会对其进行 CPS转换 ,从而使其从:

当我们在挂起函数中调用该函数时,编译器就会将当前的 continuation 也一并传入并获得当前函数的结果。在具体调用时,如果挂起函数内部真的挂起(函数返回值为 COROUTINE_SUSPENDED ),则将调用权交还给调用方,然后当前的状态+1。而当该挂起函数内部执行结束时,因为其持有着外部的 continuation ,所以会调用 continuation.resume() 恢复挂起的协程,即调用了 invokeSuspend() ,从而恢复执行先前的逻辑。
而我们常说的状态机,从根本上,其实就是构造了一个 switch 结构的label流转,每个 case 内部都可能又会再对应着一个类似的结构(如果存在挂起函数)。如果我们称其为分层,那每一层也都持有上层的对象,而当我们最底层的函数执行结束时,即开始触发恢复上层逻辑,此时状态回传,从而将子函数的结果返回出去。
7
协程的矛与盾
当我们在讨论协程时,首先要明确,我们是在说 Kotlin协程 ,下述论点也都是基于这个背景下开始。
相应的,我们也需要一个参照物,如果直接对比线程,未免有些太过于不公平,所以我们选用 线程池 与 协程 进行对比分析。
协程是线程框架吗?
在 Jvm 平台,因为 协程 底层离不开 Java线程模型 ,故最终的任务也是需要 线程池 最终去承载。所以从底层而言,我们可以通俗且大胆的认为协程就是一个线程框架,这没问题。
[但],这显然不是很合适,或者说,这有点过于糙了!
在文章开始,我们已经提过了,Android官方对其的描述:
协程是一种并发设计模式,您可以在 Android 平台上使用它来简化异步执行的代码。
所以,如果我们从协程本质与设计思想去看待,显然其相比线程池具有更高层次的编程模型,故此时称其为 异步编程框架 也许更为合适。具体原因与分析有如下几点:
-
从编程模型而言
协程与线程池两者都是用于处理异步任务或者耗时任务的工具,但两者的编程模型完全不同。线程池或者其他线程框架,往往使用回调函数来处理任务,这种方式常常比较繁琐,业务复杂时,代码可读性较差;而协程则是异步任务同步写法,基于挂起恢复的理念,由程序员自己控制执行顺序,可读性高;
-
从异常的处理角度而言
在线程池中,处理异常时,我们可以通过
tryCach业务代码,或者可以在创建线程池时,自定义ThreadFactory, 然后使用Thread.setDefaultUncaughtExceptionHandler()设置一个默认异常处理方式。相应的,协程通过 异常处理机制 来捕获和处理异常,相对于线程池而言,更加先进。 -
从调度方式而言
线程池通过创建一个固定数量的线程池来执行并发任务。每个任务将在一个可用的线程上运行,任务执行结束后,线程将返回线程池以供以后使用,并且通过在队列中等待任务来保持活动状态。如果使用协程,它并不创建新的线程,在jvm平台,其是利用少量的线程来实现并发执行,支持在单线程中执行,并使用 挂起与恢复 机制来允许并发执行。
协程性能很高?
先给结论,通常情况,协程的性能与线程池相差不大,甚至大多数常见场景,协程性能其实是不如直接使用线程池。
同时启动10w线程和协程
在协程官网,我们大概都能看到这样一句话,同时启动10w和线程和协程等等。
我们举个例子来看看,如下所示:
| 启动10w线程 | 启动10w协程 |
|---|---|
|
|
|


协程果然比线程快多了,那此时肯定就有同学说了,你拿协程欺负线程,咋不用线程池呢?
使用线程池替代线程
我们继续测试,这次改为线程池:

线程池就是快啊!
如果你这样想,证明你可能理解错了,我们这里只是往线程池里添加了10w个任务,因为我们用例里核心线程数是10,所以,同一时刻,只有10个任务在被处理,所以剩下的任务都在队列中等待。即这里打印的耗时仅仅只是上述代码的耗时,而不是线程池执行任务的总耗时,相比之下协程可是真真实实把10w个都跑完了,所以这两者根本没法比较。
所以我们对上面的逻辑进行更改,如下所示:

总耗时…,没工夫等待了,不过我们可以大概算一下,总耗时16分钟多(10w/10*0.1/60)。
为什么呢?明明底层都是线程池?
如果注意观察的话,线程的等待我们使用的是 sleep() ,而协程是 delay() ,两者的区别在于,前者是真真实实让我们的线程阻塞了指定时间,而后者则是语言级别,故差距很大。所以如果要做到相对公平,我们应该选用支持定时任务的线程池。
使用线程池模拟delay
为了保证相对公平,我们使用 ScheduledExecutorService ,并且将这个线程池转为协程的调度器。
结果如下:
| 添加10w个任务 | 启动10w个协程 |
|---|---|
|
|
|


???为什么线程池更快呢?
因为协程底层,最终任务还是需要我们的线程池来承载,但协程还需要维护自己的微型线程,而这个模型又是语言级别的控制,所以当协程代码转为字节码之后,即需要更多的代码才能实现。相比之下,线程池就简单直接很多,故这也是为什么线程池会快一点的原因。
场景推荐
通常情况下,我们真正耗时的任务都是IO、网络 或者其他操作,所以此时协程的应用层的额外操作几乎并不影响大局。或者说面对复杂的异步场景是,此时性能也许并不是我们首先考虑,而如何更清晰的编码与封装实现,才是我们所更关心的。相应的,相比线程池,协程就很擅长这个处理异步任务。比如协程可以通过简化异步操作,也能在很大程度上,能避免我们不当的操作行为导致阻塞UI线程行为,从而提高应用性能。故在某个角度而言,协程的性能相比不恰当的使用线程池,是会更高。
所以如果我们的场景对性能有这极致要求,比如应用启动框架等,那么此时使用协程往往并不是最佳选择。但如果我们的场景是日常的业务开发,那么协程绝对是你的最佳选择。
8
协程的使用技巧
将协程设置为可取消
在协程中,取消属于协作操作,也就是说,当我们cancel掉某个job之后,相应的协程在挂起与恢复之前并不会立即取消(原因是协程的check时机是在我们状态机的每个步骤里),即也就是说,如果你有某个阻塞操作,协程此时并不会被取消。
如下所示:
| 示例 | 运行结果 |
|---|---|
|
|
|


如上所示,我们会发现,当我们 cancel() 子协程后,我们的 readFile() 依然会正常执行。
要解释原理也非常简单:
因为 readFile() 并不是挂起函数,并且该方法内部也没有做协程 状态判断 。
在协程中,我们常用的函数 delay()、withContext()、ensureActive()、yield() 等都提供了检查功能。
我们改动一下上述示例,如下所示:
如上所示,我们在 readFile() 中增加了 yield() 方法,而当我们 cancel() 掉子协程时,当 Thread.sleep() 执行结束后,遇到 yield()时,该方法就会判断当前协程作用域是否已经不在活跃,如果满足条件,则直接抛出 CancellationException 异常。
协程的同步问题?
因为 Kotlin协程 是运行在 Java线程模型 基础之上,所以相应的,也存在 同步 问题。
在多线程的情况下,操作执行的顺序是不可预测的。与编译器优化操作的顺序不同,线程无法保证以特定的顺序运行,而上下文切换的操作随时有可能发生。所以如果在访问一个未经处理的状态时,线程很有可能就会访问到过时的数据,丢失必要的更新,或者遇到 资源竞争 等情况。
所以,使用了协程并且涉及可变状态的类必须采取措施使其可控,比如保证协程中的代码所访问的数据是最新的。这样一来,不同的线程之间就不会互相干扰。
如下示例:

上述代码很简单,需要注意的是,为了防止 println() 先于我们的 repeat() 执行结束,我们使用measureTimeMillis()+coroutineScope() 进行嵌套,从而等待 coroutineScope() 内部所有子协程全部执行结束,才退出 measureTimeMillis() 。
不过从结果来看,不出意外的也存在同步问题,那该怎么解决?
按照Java开发中的习惯,我们可以使用 synchronized ,或者使用 AtomicInteger 管理sum。
常规方式解决
如下所示,我们选用 synchronized 来解决:

如上所示,我们使用了 synchronized 对象锁来解决同步问题。
注意:这里我们锁的是
this@coroutineScope,而不是this,前者代表着我们循环外的作用域对象,而直接使用this则代表了当前协程的作用域对象,并不存在竞争关系。
使用Mutex解决
除去传统的解决方式之外,Kotlin 中还增加了额外的辅助类去解决协程同步问题,其使用起来也更加简单,即 Mutex(互斥锁) ,这也是协程中解决同步问题的推荐方式。
如下示例:

我们创建了一个 Mutex 对象,并使用其 加锁方法 withLock() ,从而避免多协程下的同步问题。相应的,Mutex 也提供了 lock() 与 unLock() 从而控制对共享资源的访问(withLock()是这两者的封装)。
从原理上而言,Mutex 是通过 一个 AtomicInteger 类型的状态记录锁的状态(是否被占用),并使用一个 ConcurrentLinkedQueue 类型的队列来持有 等待持有锁 的协程,从而解决多个协程并发下的同步问题。
相比传统的 synchronized 阻塞线程,Mutex 内部使用了 CAS机制,并且支持协程的挂起恢复,其可扩展性,其都更具有优势;并且在协程的挂起函数中使用 synchronized,也可能会影响协程的正常调度和执行。故无论是上手难度及可读性,Mutex 无疑是更适合协程开发者的。
Mutex是性能的最佳选择吗?
在过往,我们提到 synchronized 都会觉得,它会直接阻塞线程,大家都会不约而同的推荐CAS作为更好的替代。但其实 synchronized 在jdk1.6 之后,已经增加了各种优化,比如增加了各种锁去减缓直接加锁所导致的上下文切换耗时。
所以,我们对比一下上述的耗时:
为什么 Mutex 的性能其实不如 synchronized 呢?
原因如下:
-
Mutex在处理并发访问时会产生额外的开销,由于Mutex是一个互斥锁,它需要操作系统层面的支持来实现,包括支持挂起和恢复、上下文切换和内核态和用户态之间的切换等操作,这些操作都需要较大的系统开销和时间,导致Mutex的性能较差。 -
而
synchronized采用了一种更加灵活的方式来实现锁的机制,它会检查锁状态,如果没有被持有,则可以立即获取锁。如果锁被持有,则选择等待,或者继续执行其他的任务。从具体的实现上来说,synchronized底层由jvm保证,在运行过程中,可能会出现偏向锁、轻量级锁、重量级锁等。关于synchronized相关的问题,大家也可以去看看我这篇文章 浅析 synchronized 底层实现与锁相关。
最后,我们再看一下 Kotlin 在 Flow 中关于同步问题的解决方法:

嗯,所以Mutex还要不要用了?
如果我们把视线向上提一级,就会理解,当我们在选用 Kotlin 协程的时候,就已经选择了为了使用方便去容忍牺牲一部分性能。再者说,如果你的业务真的对性能要求极致,那么协程本身其实并不是首选推荐的,此时你应该选用线程池去处理,从而得到性能的最大化,因为协程本身的微型机制就需要做更多的额外操作。
再将视角切回到同步问题的处理上,Mutex 是协程中的推荐解决同步问题的方式,而且支持挂起与恢复,这点是其他同步解决方式无法具备的;再者说,Mutex 的上手难度相比 synchronized 低了不少。而至于性能上的差距,对于我们的业务开发而言,几乎是不会感知到,所以在协程中,Kotlin团队建议我们使用Mutex。
协程的异常处理方式
关于协程的异常处理,其实一直都不是一个简单事,或者说,优雅的处理异常并没那么简单。
在传统的原生的异常处理中,我们处理异常无在乎是这两种:
-
tryCatch();
-
Thread.setDefaultUncaughtExceptionHandler();
后者常用于非主线程的保底,前者用于几乎任何位置。
因为协程底层也是使用的java线程模型,所以上述的方式,在协程的异常处理中,同样有效,如下所示:

上述的
runCatching()是kotlin中对tryCatch()的一种封装。
使用CoroutineExceptionHandler
在协程中,官方建议我们使用 CoroutineExceptionHandler 去处理协程中异常,或者作为协程异常的保底手段,如下所示:

我们定义了一个 CoroutineExceptionHandler,并在初始化 CoroutineScope 时将其传入,从而我们这个协程作用域下的所有子协程发生异常时都将被这个 handler 所拦截。
这里使用了
SupervisorJob()的原因是,协程的异常是会传递的,比如当一个子协程发生异常时,它会影响它的兄弟协程与它的父协程。而使用了SupervisorJob()则意味着,其子协程的异常都将由其自己处理,而不会向外扩散,影响其他协程。
还有一点需要注意的是, CoroutineExceptionHandler 只能用于初始化 CoroutineScope 本身的初始化或者其直接子协程(即scope.launch),否则就算创建子协程时携带了 CoroutineExceptionHandler,也不会生效。
关于协程的异常处理,具体可以看我的这篇文章,里面有详细讲解:Kotlin | 关于协程异常处理,你想知道的都在这里。
常见高阶函数
在开发中,有一些高阶函数,对我们特别有用,这里就将其列出来,以便大家开发中进行使用:
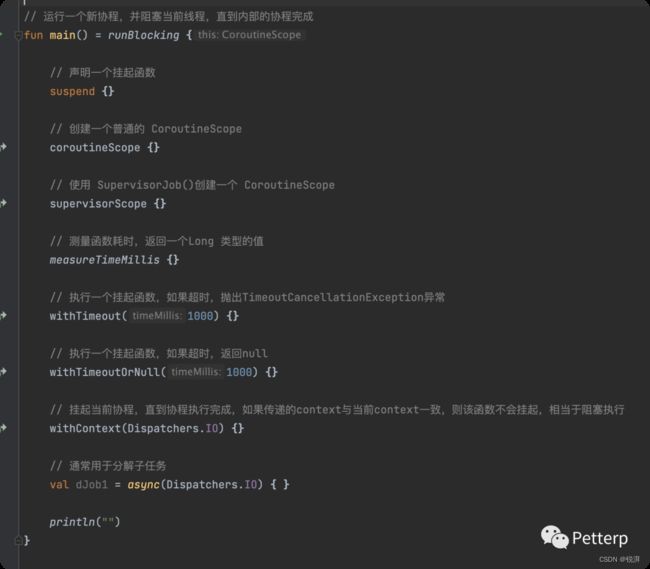
如果你对上述的方法都非常了解,那不妨为自己鼓鼓掌。
9
总结
在本篇,我们着力于从全盘看起,理清 Kotlin协程 的方方面面。从 协程背景 到 挂起函数字节码实现,一瞥挂起与恢复的底层实现,从而体会其相应的设计魅力,并针对一些常见问题进行分析与解析,从而建立起协程彻底理解。文章中挂起函数部分的源码部分可能稍显繁琐,但依然建议大家多看几遍流程,从而更好理解。相应的细节问题,也都有详细注释。
最后,让我们再回到这个问题,协程到底是什么呢?
在JVM平台,Kotlin协程就是一个异步编程框架,它可以帮助我们简化异步代码,提升可读性,从而极大减少异步回调所带来的复杂逻辑。
从底层实现来看:
-
kotlin协程基于 java线程模型 ,故底层依然是使用了 线程池 作为任务承载,但相比传统的线程模型,协程在其基础上搭建了一套基于语言级别的 ”微型“ 线程模型。并定义了挂起函数作为相应的子任务,其内部采用了状态机的思想,用于实现协程中的挂起与恢复。
-
在挂起与恢复的实现上,使用了
suspend关键字标记的函数被称为挂起函数。其在字节码中,会经过 CPS转换 为一个带有Continuation参数,返回值为Object的方法。而Continuation正是用于保存我们的函数状态、步骤,从而实现挂起恢复,其内部也都包含着上一个Continuation,正如callback的嵌套一样。 -
当我们的函数被挂起时,我们当前的函数内部会实例化一个 ContinuationImpl() ,其内部
invokeSuspend()又维护着当前的函数逻辑,并使用一个label作为状态进行流转,如果我们的函数内部依然有其他挂起函数,此时也会将当前的Continuation对象传入子挂起函数内部,从而实现Continuation的传递,并更改当前的函数状态。而当我们最底层的方法执行结束后,此时就会再次触发父ContinuationImpl内部的invokeSuspend()方法,从而回到调用方的逻辑内部,从而完成挂起函数的恢复。以此类推,直到我们最开始的调用方法内;
从性能上去看:
协程的性能并不优于线程池或者其他异步框架,主要是其做了更多语言级别步骤,但通常情况下,与其他框架的性能几乎一致,因为相比IO的耗时,语言级别的损耗可以几乎忽略不计。
从设计模式去看:
协程使得开发者可以自行管理异步任务,而不同于线程的抢占式任务,并且写成还支持子协程的嵌套关闭、更简便的异常处理机制等,故相比其他异步框架,协程的理念更加先进。
参照
Android官网/ Android上的Kotlin协程
https://developer.android.com/kotlin/coroutines?hl=zh-cn
朱涛/ Kotlin Jetpack实战|图解协程原理
https://juejin.cn/post/6883652600462327821
zsqw123/ kotlin coroutine真的性能高吗?
https://bytedance.host/210404kotlin-ex4/
转自:万字长文,写给Android工程师的协程指南