【layumi / Person_reID_baseline_pytorch】行人重识别 ReID 学习记录
学习材料:
- 行人重识别(ReID)概述:https://blog.csdn.net/weixin_41427758/article/details/81188164
- Market 1501 数据集解析:https://blog.csdn.net/ctwy291314/article/details/83544088
- Person_reID_baseline_pytorch:https://github.com/layumi/Person_reID_baseline_pytorch
- tutorial:https://github.com/layumi/Person_reID_baseline_pytorch/tree/master/tutorial
- tutorial中的常见问题:https://github.com/layumi/Person_reID_baseline_pytorch/blob/master/tutorial/Answers_to_Quick_Questions.md
Details:
1、图片命名规则

(图片来自:链接 https://blog.csdn.net/ctwy291314/article/details/83544088 里的截图)
2、可以留意一下代码中 gt_bbox 哪里有用到?
作用:手工标注的 bounding box,用于判断 DPM 检测的 bounding box 是不是一个好的 box
3、常用评价指标
- Cumulative Match Characteristic (CMC) curve
- mAP(mean average precision)
详情:https://blog.csdn.net/weixin_41427758/article/details/81188164
4、ResNet-50(待阅读,注意结构、输入、输出尺寸等)
论文:https://arxiv.org/pdf/1512.03385.pdf
学习视频:6.1 ResNet网络结构,BN以及迁移学习详解
学习笔记:https://blog.csdn.net/qq_36627158/article/details/108481279
网络结构解析:
- https://www.jianshu.com/p/1f81608fa11d
- https://www.jianshu.com/p/993c03c22d52

(图来自 https://www.jianshu.com/p/993c03c22d52)
5、PyTorch 加载预训练模型
https://blog.csdn.net/weixin_41278720/article/details/80759933?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
6、AdaptiveAvgPool2d()
https://www.zhihu.com/question/282046628
在实际的项目当中,我们往往预先只知道的是输入数据和输出数据的大小,而不知道核与步长的大小。如果使用上面的方法创建汇聚层,我们每次都需要手动计算核的大小和步长的值。而自适应(Adaptive)能让我们从这样的计算当中解脱出来,只要我们给定输入数据和输出数据的大小,自适应算法能够自动帮助我们计算核的大小和每次移动的步长。相当于我们对核说,我已经给你输入和输出的数据了,你自己适应去吧。你要长多大,你每次要走多远,都由你自己决定,总之最后你的输出符合我的要求就行了。
这就解释了为什么将预训练模型中的 AvgPool2d 变成了 AdaptiveAvgPool2d 以及 二者之间的区别(https://github.com/layumi/Person_reID_baseline_pytorch/blob/master/tutorial/Answers_to_Quick_Questions.md)
AdaptiveAvgPool2drequires output dimension as the parameter, whileAvgPool2drequires stride, padding as the parameter like conv layer.For pedestrian images, of which the height is larger than the width, we need to specify the pooling kernel for
AvgPool2d. Therefore,AdaptiveAvgPool2dis more easy to implement. Of course, you still could useAvgPool2d.
7、PyTorch 的四维张量
四维适合表示图片类型。
eg:a=torch.rand(b,c,h,w) 表示 b 张 c 通道、h*w 的图片
8、ClassBlock 类
原来是 AvgPool2d 出来后接一个 input 为 2048,output 为 1000(ImageNet 的分类数)的全连接层。
现在是把 AvgPool2d 换成 AdaptiveAvgPool2d 后,再接了两层全连接层:
- input:2048 output:512
- input:512 output:751 (训练集的 751 个人)

打印网络结构更新的部分结果如下:
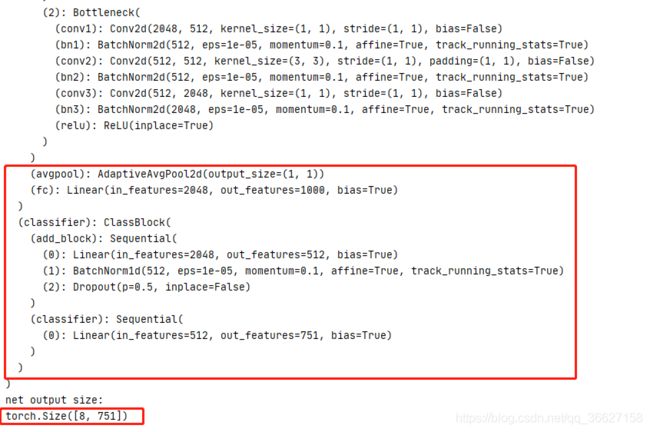
9、两个初始化权值的方法(待阅读完论文后,了解论文里第一种方法 以及 两种初始化方法的差异)

10、ft_net 打印出结构
ft_net(
(model): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
(classifier): ClassBlock(
(add_block): Sequential(
(0): Linear(in_features=2048, out_features=512, bias=True)
(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Dropout(p=0.5, inplace=False)
)
(classifier): Sequential(
(0): Linear(in_features=512, out_features=751, bias=True)
)
)
)
11、PyTorch 查看 GPU 信息
-
torch.cuda.is_available()
cuda是否可用; -
torch.cuda.device_count()
返回gpu数量; -
torch.cuda.get_device_name(0)
返回gpu名字,设备索引默认从0开始; -
torch.cuda.current_device()
返回当前设备索引;
参考:https://blog.csdn.net/nima1994/article/details/83001910
12、遇到错误:RuntimeError:An attempt has been made to start a new if __name__ == '__main__': freeze_support()
情况:我是在 Windows 上运行的

解决方案:把加载数据的 dataloader 中的 num_workers 的值由原来的 8 改为 0.
13、遇到 Warning:UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule.
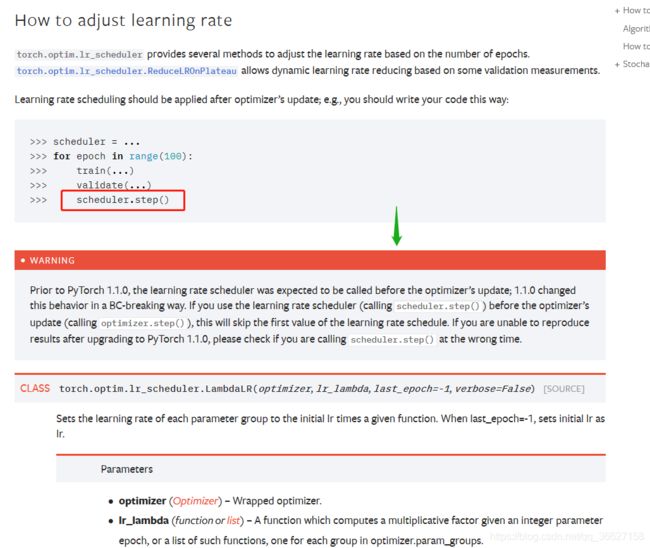
参考:
- https://blog.csdn.net/weixin_38314865/article/details/103937717
- https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-ra (官方)
14、RandomErasing
Random Erasing(随机擦除)。训练时,随机擦除方法会在原图随机选择一个矩形区域,将该区域的像素替换为随机值。这个过程中,参与训练的图片会做不同程度的遮挡,这样可以降低过拟合的风险并提高模型的鲁棒性。随机擦除是独立于参数学习过程的,因此可以整合到任何基于CNN的识别模型中。
参考:https://blog.csdn.net/oYeZhou/article/details/88826039
15、torch.nn.CrossEntropyLoss()
注意,用这个函数算出来的 Loss 是一个 batch 数据的平均 Loss!
参考:https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-nn/#torchnn

16、train.py 文件总算 run 完啦!结果如下:
电脑环境:
- Win 10
- PyCharm
- Anaconda
- GPU 4G
Epoch 59/59
----------
train Loss: 0.0208 Acc: 0.9994
val Loss: 0.0067 Acc: 0.9800
Training complete in 212m 49s
Training complete in 212m 49s
17、为什么在 test.py 文件中对测试图片进行水平翻转(fliplr)
这只是一个 trick,不是必要的。像 ResNet 的论文中也提及了使用随机剪裁和水平翻转来提高分类正确率。这么做的主要原因是更多的测试图片可以得到更稳定的结果,我们希望通过水平翻转得到一个更健壮的特征。
参考:https://github.com/layumi/Person_reID_baseline_pytorch/issues/99
18、运行 test.py 文件时,报出了错误如下:
'tee' 不是内部或外部命令,也不是可运行的程序或批处理文件。
原因:tee 是 Linux 系统下的命令
解决方案:

参考:https://www.cnblogs.com/wukong1688/p/11141363.html
下载地址:https://sourceforge.net/projects/unxutils/?source=dlp
注意:tee.exe 在下载解压下来的文件夹里的 UnxUtils\usr\local\wbin 这个位置。
19、zero_() 和 zero() 的区别
参考:https://segmentfault.com/p/1210000018112444/read
修改 tensor 的方法可以用一个下划线后缀来标示。比如,
torch.FloatTensor.abs_()会在原地计算绝对值并返回修改的张量,而torch.FloatTensor.abs()将会在新张量中计算结果.
20、torch.norm() 求范数
背景知识:什么是范数?

参考:https://www.cnblogs.com/wanghui-garcia/p/11266298.html
21、为什么用 output 的 L2 范数作为特征?

为什么用 L2 范数?:是为了方便后面用计算 query_image_i_feature 和 gallery_image_feature 的相似度(衡量两个向量相似度的方法:余弦相似度),下图就是 evaluate_gpu.py 文件中计算 score 部分的代码。

21、水平翻转加和会不会影响后面的分类?

我原来纠结的点在于:只翻转 query 里的 image,怎么和 gallery 里的图片比。后面发现 gallery 和 query 都翻转了,那就没问题了。
22、test.py 中为什么不用分类结果,要删掉最后一层 FC?

解答:不是。直接用学到的 feature 而不是最终分类的结果,是为了方便后面可以和 gallery 中图片提取出来的 feature 进行 cosine 距离的计算,从而考量两个 features 之间的相似度。
23、test.py 文件只用来提取 query 和 gallery 图片的 feature。运行完这个文件后,生成了pytorch_result.mat 文件。

24、torch.mm()
maxtric multiplication
参考:https://blog.csdn.net/Real_Brilliant/article/details/85756477
25、[::-1]
a=[1,2,3.4,5]
print(a[::-1]) ### 取从后向前(相反)的元素
###结果:[ 5 4 3 2 1 ]参考:https://blog.csdn.net/ITOMG/article/details/88683256
26、evaluate_gpu.py 中比较难理解的一段代码:
query_index = np.argwhere(gl==ql)
camera_index = np.argwhere(gc==qc)
# The images of the same identity in different cameras
good_index = np.setdiff1d(query_index, camera_index, assume_unique=True)
# Only part of body is detected.
junk_index1 = np.argwhere(gl==-1)
# The images of the same identity in same cameras
junk_index2 = np.intersect1d(query_index, camera_index)假设现在我的 query_image 是 5 号 camera 拍的 201 号对象。
那么 ,query_index 指的是 gallery 图片中所有对象为 201 号的图片所在下标。
camera_index 指的是 gallery 图片中所有 5 号摄像头拍的图片所在下标。
那么,正确的候选图片下标(good_index)应该是 gallery 中对象为 201 号的图片,除去 5 号 camera 拍,即要找 1、2、3、4、6 号 camera 拍的 201 号对象的图片。
def setdiff1d(ar1: Union[ndarray, Iterable, int, float], ar2: Union[ndarray, Iterable, int, float], assume_unique: bool = False) -> AnyFind the set difference of two arrays. Return the unique values in ar1 that are not in ar2.
junk_index2 指的是 gallery 中 5 号 camera 拍的对象为 201 号的图片。
def intersect1d(ar1: Union[ndarray, Iterable, int, float],
ar2: Union[ndarray, Iterable, int, float],
assume_unique: bool = False,
return_indices: bool = False) -> AnyFind the intersection of two arrays. Return the sorted, unique values that are in both of the input arrays.
27、np.in1d()
def in1d(ar1: Any,
ar2: Union[ndarray, Iterable, int, float],
assume_unique: Optional[bool] = False,
invert: Optional[bool] = False) -> Any
Examples
>>> test = np.array([0, 1, 2, 5, 0])
>>> states = [0, 2]
>>> mask = np.in1d(test, states)
>>> mask
array([ True, False, True, False, True])
>>> test[mask]
array([0, 2, 0])
>>> mask = np.in1d(test, states, invert=True)
>>> mask
array([False, True, False, True, False])
>>> test[mask]
array([1, 5])参考:官方文档
28、(待确定)计算 AP 用这么麻烦吗?

29、evaluate_gpu.py 文件中 cmc[rows_good[0]:] 为什么这么写?

30、evaluate_gpu.py 文件运行完后,结果如下:

注意:程序虽然只打印了 Rank1、5、10 的结果,但实际上运行完后,Rank 从 1 到 len(query_label) 的结构都保存在结果 CMC 中。
31、运行 demo.py 文件时,遇到无法 plot 出结果。报错:UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
解决方案:
import matplotlib
>>> matplotlib.get_backend()
'agg'
>>> matplotlib.use('TkAgg')注意:设置完后,别忘了把代码中的 'agg' 修改为 'TkAgg'

参考:https://www.cnblogs.com/xiexiaokui/p/12237910.html
32、query_path, _ = image_datasets['query'].imgs[i]
疑问:imgs 是什么?为什么能返回 query_path?另外一个返回的参数 _ 又代表什么?
解答:image_datasets 是 torchvision.datasets.ImageFolder 对象。关于 torchvision.datasets.ImageFolder 的讲解,请参考这篇 blog:https://blog.csdn.net/qq_33254870/article/details/103362621 的第 2 、3点。
该 API 有以下成员变量:
- self.classes:用一个 list 保存类别名称
- self.class_to_idx:类别对应的索引,与不做任何转换返回的 target 对应
- self.imgs:保存 (img-path, class) tuple的 list,与我们自定义 Dataset类的 def __getitem__(self, index): 返回值类似。
所以,参数 _ 代表的是该 image 在 self.classes 中对应类别的 index。但后面用不上这个 index,所以这里对 class 的返回值就随便取了一个变量名 _。
33、demo.py 文件运行结果:
G:\PycharmProjects\ReID_tutorial>python demo.py --query_index 777 --test_dir G:/PycharmProjects/ReID_tutorial/Market/pytorch
query image: G:/PycharmProjects/ReID_tutorial/Market/pytorch\query\0342\0342_c5s1_079123_00.jpgTop 10 images are as follow:
G:/PycharmProjects/ReID_tutorial/Market/pytorch\gallery\0342\0342_c3s1_078792_03.jpg
G:/PycharmProjects/ReID_tutorial/Market/pytorch\gallery\0342\0342_c3s1_078767_01.jpg
G:/PycharmProjects/ReID_tutorial/Market/pytorch\gallery\0342\0342_c1s2_022816_02.jpg
G:/PycharmProjects/ReID_tutorial/Market/pytorch\gallery\0252\0252_c5s1_058423_03.jpg
G:/PycharmProjects/ReID_tutorial/Market/pytorch\gallery\0342\0342_c2s1_078546_01.jpg
G:/PycharmProjects/ReID_tutorial/Market/pytorch\gallery\0672\0672_c3s2_062778_03.jpg
G:/PycharmProjects/ReID_tutorial/Market/pytorch\gallery\0342\0342_c1s2_006316_02.jpg
G:/PycharmProjects/ReID_tutorial/Market/pytorch\gallery\0342\0342_c3s1_094817_02.jpg
G:/PycharmProjects/ReID_tutorial/Market/pytorch\gallery\0252\0252_c5s1_058448_06.jpg
G:/PycharmProjects/ReID_tutorial/Market/pytorch\gallery\0672\0672_c2s2_041362_01.jpg
