【论文阅读笔记】(2023 CVPR)Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for
Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks
(2023 CVPR)
Weihua Chen, Xianzhe Xu, Jian Jia, Hao luo, Yaohua Wang, Fan Wang, Rong Jin, Xiuyu Sun*
Notes
Paper Link:https://arxiv.org/pdf/2303.17602.pdf
Code Link:GitHub - tinyvision/SOLIDER
0. 写在前面
已有公众号文章讲解了这篇文章:CVPR 2023 | 自监督学习框架SOLIDER:用于以人为中心的视觉
我就不重复造轮子啦~这里讲讲我对这篇文章的其他见解。
1. Contribution
1. Semantic Supervision from Human Prior: 利用人体图片先验打伪标签,进行自监督训练,使得预训练模型包含更多的语义信息。
2. Semantic Controller: 引入一个语义控制器,控制预训练模型中语义信息的含量多少,来适应不同的下游任务。
——《CVPR 2023 | 自监督学习框架SOLIDER:用于以人为中心的视觉》
这里的人体图片先验知识是:
- 人体占据了图片的极大部分,几乎是全部区域;
- 头部在图片上方,脚步在图片下方;
- 整张图片大致可分为四个部分:上半身、下半身、鞋子(前三项组成前景)和背景。
2. Method
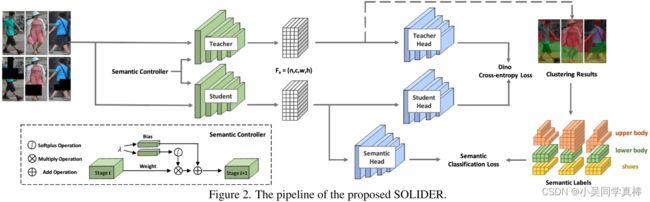
整个框架分为两个部分:一个是对比学习部分,一个是语义分类(语义重建)部分。
![]()
其中 α=0.5
2.1 对比学习(DINO)

- teacher 分支不更新参数(sg),其参数的更新靠 student 的参数进行 ema:
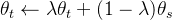
- 设置 K 个 center,两个分支的输出均为:输入图片属于 K 个 center 的概率分布
- DINO CE Loss 和普通 CE Loss 的区别就是用 teacher 分支的输出作为 GT
其他详细细节可见 DINO 原论文:Emerging Properties in Self-Supervised Vision Transformers
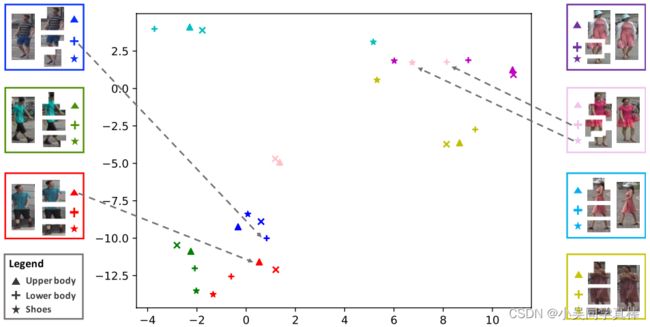
可视化 DINO 学习到的 token representation,结果/现象:同一张图片不同 part 的 representation 会聚在一起,说明纯用 DINO 的方法进行自监督学习所提取到的特征更关注 appearance
2.2 语义分类、语义重建(SM)
先对 teacher 分支的 feature map 进行语义聚类:
- 先用 K-means 按 token vector 的 magnitude (i.e., l2 normalization) 进行聚类,将输入图片的所有 token 聚成 2 类,前景和背景;
- 再单独对被聚类为前景的 token 进行“上半身、下半身 和 鞋子” 3 个类别的聚类。
最后,每个 token 会被赋值为 4 个伪标签(即语义标签)中的一个。
接着,对 student 分支的 feature map 里每个 token 做 4 个类别的分类任务(每个 token 的伪标签就来自 teacher 分支 feature map 的 聚类结果)。
![]()
2.3 语义控制器(Semantic Controller)
这是我觉得全文最巧妙的地方!!!
为了满足不同下游任务对不同信息(语义、外观等)的需求,自监督预训练模型需要对不同下游任务进行变化(参数不同),这就意味着需要训练多个自监督模型。
但这篇文章是较大程度上做到了 multiple-in-one,只训练一个自监督模型,再设置不同的 λ,就可以得到不同的自监督模型:
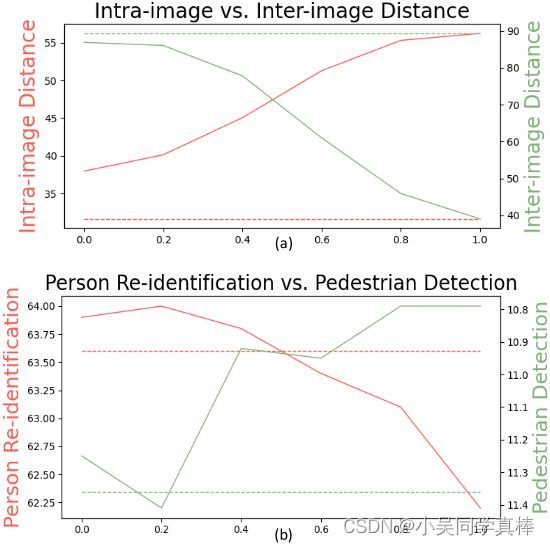
- 当 λ 取较小的值(比如 0.2)时,自监督模型会更倾向于提取图片中的 appearance 信息,其模型提取的特征会更有利于像 person re-id 这样更依赖于 appearance 信息进行识别的下游任务;
- 当 λ 取较大的值(比如 1.0)时,自监督模型会更倾向于提取图片中的 semantic 信息,其模型提取的特征会更有利于 person detection 这样更依赖于 semantic 信息进行的下游任务;
不过文章只是展示了怎么做以及结果,没有过多的分析为什么可以做到。所以这里会着重讲一下为什么可以做到:引入一个 λ 就可以适应不同的下游任务,达到 “lambda 值越大,保留的 appearance 信息越少” 的效果?
先看看 Semantic Controller 的网络结构:
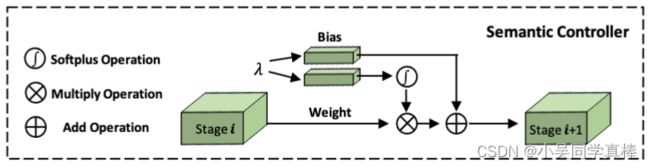
其将 λ 嵌入进一个可学习的 weight vector 和一个可学习的 bias vector里,将其和 student 分支里上一个 stage 的 output feature map 进行相乘相加,作为 student 分支里下一个 stage 的输入。
(softplus 激活函数可见:Softplus函数)
代码实现可见:
-
https://github.com/tinyvision/SOLIDER/blob/main/swin_transformer.py#L1219
-
https://github.com/tinyvision/SOLIDER/blob/main/swin_transformer.py#L1349
再来看看最后的目标函数:
![]()
注意看!!!加号后面的 λ 就是实现 multiple-in-one 的关键!!!以下是个人拙见:
如果 λ 值比较大,加号后面那一项(也就是语义分类/重构)权重就会比较大,该项产生的损失值占比就会比较大,所以整个网络往语义分类/重构方向进行优化的步伐会大一些。这就意味着,嵌入较大 λ 值的 weight vector 和 bias vector 要调整上一个 stage 的 output feature map,让网络中下一个 stage 的输入包含更多图片中 semantic 信息,便于网络表达图片中的语义信息。
如果 λ 值比较小,加号后面那一项(也就是语义分类/重构)权重就会比较小,该项产生的损失值占比就会比较小,所以网络往对比学习方向进行优化的步伐会大一些。这就意味着,嵌入较大 λ 值的 weight vector 和 bias vector 要调整上一个 stage 的 output feature map,让网络中下一个 stage 的输入包含更多图片中 appearance 信息,便于网络表达图片中的外观信息。
训练整个自监督框架时,作者在每个迭代里随机采样 λ 的值,采样服从概率为 0.5 的二项分布。
最后训练完自监督框架后,针对不同的下游任务,只需要手动设置不同的 λ 值就好。
3. Experiments
这里的训练方法需要提一下:论文指出聚类的过程比较耗时,所以他们先训 DINO,再在训好的模型上 finetune 本文的方法(即 SOLIDER)
在 6 种下游任务上进行 finetune
- 消融实验

- 和其他 sota 方法对比
