deeplabv3+源码之慢慢解析7 第二章datasets文件夹(2)voc.py--VOCSegmentation类
系列文章目录
第一章deeplabv3+源码之慢慢解析 根目录(1)main.py–get_argparser函数
第一章deeplabv3+源码之慢慢解析 根目录(2)main.py–get_dataset函数
第一章deeplabv3+源码之慢慢解析 根目录(3)main.py–validate函数
第一章deeplabv3+源码之慢慢解析 根目录(4)main.py–main函数
第一章deeplabv3+源码之慢慢解析 根目录(5)predict.py–get_argparser函数和main函数
第二章deeplabv3+源码之慢慢解析 datasets文件夹(1)voc.py–voc_cmap函数和download_extract函数
第二章deeplabv3+源码之慢慢解析 datasets文件夹(2)voc.py–VOCSegmentation类
第二章deeplabv3+源码之慢慢解析 datasets文件夹(3)cityscapes.py–Cityscapes类
第二章deeplabv3+源码之慢慢解析 datasets文件夹(4)utils.py–6个小函数
第三章deeplabv3+源码之慢慢解析 metrics文件夹stream_metrics.py–StreamSegMetrics类和AverageMeter类
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(a1)hrnetv2.py–4个函数和可执行代码
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(a2)hrnetv2.py–Bottleneck类和BasicBlock类
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(a3)hrnetv2.py–StageModule类
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(a4)hrnetv2.py–HRNet类
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(b1)mobilenetv2.py–2个类和2个函数
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(b2)mobilenetv2.py–MobileNetV2类和mobilenet_v2函数
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(c1)resnet.py–2个基础函数,BasicBlock类和Bottleneck类
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(c2)resnet.py–ResNet类和10个不同结构的调用函数
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(d1)xception.py–SeparableConv2d类和Block类
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(d2)xception.py–Xception类和xception函数
第四章deeplabv3+源码之慢慢解析 network文件夹(2)_deeplab.py–ASPP相关的4个类和1个函数
第四章deeplabv3+源码之慢慢解析 network文件夹(3)_deeplab.py–DeepLabV3类,DeepLabHeadV3Plus类和DeepLabHead类
第四章deeplabv3+源码之慢慢解析 network文件夹(4)modeling.py–5个私有函数(4个骨干网,1个模型载入)
第四章deeplabv3+源码之慢慢解析 network文件夹(5)modeling.py–12个调用函数
第四章deeplabv3+源码之慢慢解析 network文件夹(6)utils.py–_SimpleSegmentationModel类和IntermediateLayerGetter类
第五章deeplabv3+源码之慢慢解析 utils文件夹(1)ext_transforms.py.py–[17个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(2)loss.py–[1个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(3)scheduler.py–[1个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(4)utils.py–[1个类,4个函数]
第五章deeplabv3+源码之慢慢解析 utils文件夹(5)visualizer.py–[1个类]
总结
文章目录
- 系列文章目录
-
- 第二章datasets文件夹(2)voc.py--VOCSegmentation类
- VOCSegmentation类
第二章datasets文件夹(2)voc.py–VOCSegmentation类
本篇介绍voc.py中的VOCSegmentation类,整个voc.py中最重要的部分。
VOCSegmentation类
提示:先看完上个部分所说的voc_cmap函数和download_extract函数,本段代码会使用这部分功能。
class VOCSegmentation(data.Dataset):
"""`Pascal VOC Tips
- 补充,感兴趣的话新手同学可以参考os.path的简单介绍。
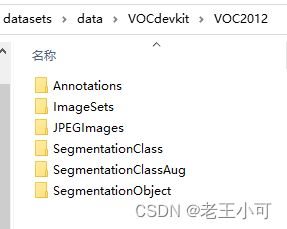
- 补充一次前文的文件夹结构目录。
如VOC数据集的文件夹层级:

- voc.py已全部梳理完。下一个节是cityscapes.py–Cityscapes类。