广义线性模型[generalize linear model(GLM)]是线性模型的扩展,通过联系函数建立响应变量的数学期望值与线性组合的预测变量之间的关系。它的特点是不强行改变数据的自然度量,数据可以具有非线性和非恒定方差结构。是线性模型在研究响应值的非正态分布以及非线性模型简洁直接的线性转化时的一种发展。

在广义线性模型的理论框架中,则假设目标变量Y则是服从指数分布族,正态分布和伯努利分布都属于指数分布族,因此线性回归和逻辑回归可以看作是广义线性模型的特例。
这是概率分布及其正则联系函数(Canonical Link function)的列表。
- 正态分布:恒等函数
- 泊松分布:对数函数
二项分布:分对数函数
除此以外我们还可以自定义联系函数,如果不喜欢自己编写可以使用在 statsmodels 中实现了的各种联系函数,Stan、PyMC3 和 TensorFlow Probability 等概率编程框架也给我们提供了这些函数。
link function也被翻译为连接函数,这里觉得联系函数更为贴切所以还是翻译为联系函数
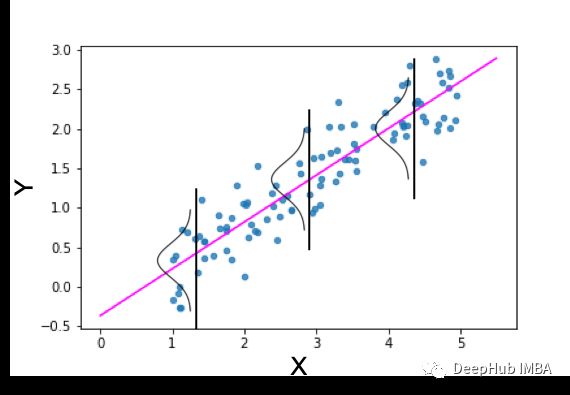
线性回归
线性回归用于通过解释变量 X 的线性组合来预测连续变量 y 的值。
在单变量情况下,线性回归可以表示如下

模型假定噪声项的正态分布。该模型说明如下
泊松回归
泊松分布用于对计数数据进行建模。它只有一个参数代表分布的均值和标准差。这意味着平均值越大,标准差越大。


如果我们将泊松回归应用于数据。结果应该是这样的。

预测曲线是指数的,因为对数联系函数( log link function)的反函数是指数函数。由此也可以清楚地看出,由线性预测器计算的泊松回归参数保证为正。
以下是一个泊松回归的示例代码
import numpy as np
from numpy.random import uniform, normal, poisson, binomial
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
%matplotlib inline
## ============Poisson regression
# generate simulation data
np.random.seed(5)
n_sample = 100
a = 0.6
b = -0.4
x = uniform(1, 5, size=n_sample)
mu = np.exp(a * x + b)
y = poisson(mu)
import statsmodels.api as sm
exog, endog = sm.add_constant(x), y
# Poisson regression
mod = sm.GLM(endog, exog, family=sm.families.Poisson(link=sm.families.links.log()))
res = mod.fit()
display(res.summary())
y_pred = res.predict(exog)
idx = x.argsort()
x_ord, y_pred_ord = x[idx], y_pred[idx]
plt.plot(x_ord, y_pred_ord, color='m')
plt.scatter(x, y, s=20, alpha=0.8)
plt.xlabel("X")
plt.ylabel("Y")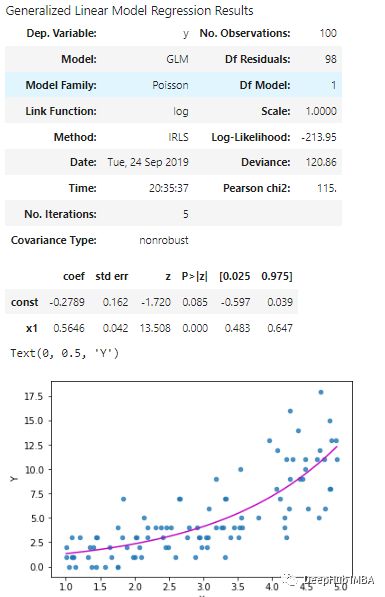
粉色曲线是泊松回归的预测。
逻辑回归
如果使用分对数( logit)函数作为联系函数,使用二项式/伯努利分布作为概率分布,则该模型称为逻辑回归。

第二个方程的右边叫做logistic函数。因此这个模型被称为逻辑回归。对于任意输入,logistic函数返回的值在0到1之间,对于二项分布它是一个合适的联系函数。逻辑回归也就是我们常看到的这个样子

总结
如果要进行“广义线性模型(GLM)”分析,只需要摘到我们需要的联系函数,它的作用就是把Y与X间的非线性关系转换成线性关系,我们完全可以自己编写我们需要的联系函数。
实际使用中我们只要把联系函数和方差函数假设正确,甚至不用管是什么分布的,如果使用的就是一些典型联系函数,则方差函数都可以不用假设。所以其实广义线性模型的要点就是:联系函数和/或方差函数要假设正确,这样就ok了。
本文代码:
https://avoid.overfit.cn/post/eb42f5cb4a534dfa9844600acb1fc546
作者:Rana singh