MongoDB(一)
MongoDB数据库
一、NoSQL 简介
NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。
在现代的计算系统上每天网络上都会产生庞大的数据量。
这些数据有很大一部分是由关系数据库管理系统(RDBMS)来处理。 1970年 E.F.Codd’s提出的关系模型的论文 “A relational model of data for large shared data banks”,这使得数据建模和应用程序编程更加简单。
通过应用实践证明,关系模型是非常适合于客户服务器编程,远远超出预期的利益,今天它是结构化数据存储在网络和商务应用的主导技术。
NoSQL 是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
关系型数据库遵循ACID规则
事务在英文中是transaction,和现实世界中的交易很类似,它有如下四个特性:
1、A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
2、C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
3、I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
比如现在有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
4、D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
分布式系统
分布式系统(distributed system)由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成。
分布式系统是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。
因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。
分布式系统可以应用在不同的平台上如:Pc、工作站、局域网和广域网上等。
分布式计算的优点
可靠性(容错) :
分布式计算系统中的一个重要的优点是可靠性。一台服务器的系统崩溃并不影响到其余的服务器。
可扩展性:
在分布式计算系统可以根据需要增加更多的机器。
资源共享:
共享数据是必不可少的应用,如银行,预订系统。
灵活性:
由于该系统是非常灵活的,它很容易安装,实施和调试新的服务。
更快的速度:
分布式计算系统可以有多台计算机的计算能力,使得它比其他系统有更快的处理速度。
开放系统:
由于它是开放的系统,本地或者远程都可以访问到该服务。
更高的性能:
相较于集中式计算机网络集群可以提供更高的性能(及更好的性价比)。
分布式计算的缺点
故障排除:
故障排除和诊断问题。
软件:
更少的软件支持是分布式计算系统的主要缺点。
网络:
网络基础设施的问题,包括:传输问题,高负载,信息丢失等。
安全性:
开放系统的特性让分布式计算系统存在着数据的安全性和共享的风险等问题。
什么是NoSQL?
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
为什么使用NoSQL ?
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL 数据库的发展却能很好的处理这些大的数据。

实例
社会化关系网:
Each record: UserID1, UserID2
Separate records: UserID, first_name,last_name, age, gender,…
Task: Find all friends of friends of friends of … friends of a given user.
Wikipedia 页面 :
Large collection of documents
Combination of structured and unstructured data
Task: Retrieve all pages regarding athletics of Summer Olympic before 1950.
RDBMS vs NoSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL) (SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
-键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
NoSQL 简史
NoSQL一词最早出现于1998年,是Carlo Strozzi开发的一个轻量、开源、不提供SQL功能的关系数据库。
2009年,Last.fm的Johan Oskarsson发起了一次关于分布式开源数据库的讨论[2],来自Rackspace的Eric Evans再次提出了NoSQL的概念,这时的NoSQL主要指非关系型、分布式、不提供ACID的数据库设计模式。
2009年在亚特兰大举行的"no:sql(east)“讨论会是一个里程碑,其口号是"select fun, profit from real_world where relational=false;”。因此,对NoSQL最普遍的解释是"非关联型的",强调Key-Value Stores和文档数据库的优点,而不是单纯的反对RDBMS。
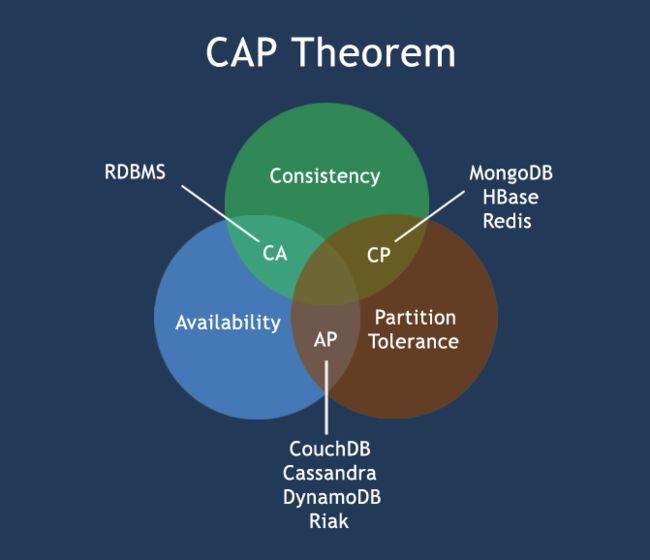
CAP定理(CAP theorem)
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer’s theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
NoSQL的优点/缺点
优点:
- - 高可扩展性
- - 分布式计算
- - 低成本
- - 架构的灵活性,半结构化数据
- - 没有复杂的关系
缺点:
- - 没有标准化
- - 有限的查询功能(到目前为止)
- - 最终一致是不直观的程序
BASE
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
- Basically Available --基本可用
- Soft-state --软状态/柔性事务。 “Soft state” 可以理解为"无连接"的, 而 “Hard state” 是"面向连接"的
- Eventually Consistency – 最终一致性, 也是 ACID 的最终目的。
ACID vs BASE
| ACID | BASE |
|---|---|
| 原子性(Atomicity) | 基本可用(Basically Available) |
| 一致性(Consistency) | 软状态/柔性事务(Soft state) |
| 隔离性(Isolation) | 最终一致性 (Eventual consistency) |
| 持久性 (Durable) |
NoSQL 数据库分类
| 类型 | 部分代表 | 特点 |
|---|---|---|
| 列存储 | Hbase Cassandra Hypertable | 顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
| 文档存储 | MongoDB CouchDB | 文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| key-value存储 | Tokyo Cabinet / Tyrant Berkeley DB MemcacheDB Redis | 可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
| 图存储 | Neo4J FlockDB | 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
| 对象存储 | db4o Versant | 通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
| xml数据库 | Berkeley DB XML BaseX | 高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
谁在使用
现在已经有很多公司使用了 NoSQL:
Mozilla
Adobe
Foursquare
Digg
McGraw-Hill Education
Vermont Public Radio
二、什么是MongoDB ?
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。

主要特点
- MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
- 你可以在MongoDB记录中设置任何属性的索引 (如:FirstName=“Sameer”,Address=“8 Gandhi Road”)来实现更快的排序。
- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
- Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
- Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
- MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
- MongoDB安装简单。
历史
- 2007年10月,MongoDB由10gen团队所发展。2009年2月首度推出。
- 2012年05月23日,MongoDB2.1 开发分支发布了! 该版本采用全新架构,包含诸多增强。
- 2012年06月06日,MongoDB 2.0.6 发布,分布式文档数据库。
- 2013年04月23日,MongoDB 2.4.3 发布,此版本包括了一些性能优化,功能增强以及bug修复。
- 2013年08月20日,MongoDB 2.4.6 发布。
- 2013年11月01日,MongoDB 2.4.8 发布。
- ……
MongoDB 下载
你可以在mongodb官网下载该安装包,地址为:https://www.mongodb.com/download-center#community。MonggoDB支持以下平台:
- OS X 32-bit
- OS X 64-bit
- Linux 32-bit
- Linux 64-bit
- Windows 32-bit
- Windows 64-bit
- Solaris i86pc
- Solaris 64
语言支持
MongoDB有官方的驱动如下:
- C
- C++
- C# / .NET
- Erlang
- Haskell
- Java
- JavaScript
- Lisp
- node.JS
- Perl
- PHP
- Python
- Ruby
- Scala
- Go
MongoDB 工具
有几种可用于MongoDB的管理工具。
监控
MongoDB提供了网络和系统监控工具Munin,它作为一个插件应用于MongoDB中。
Gangila是MongoDB高性能的系统监视的工具,它作为一个插件应用于MongoDB中。
基于图形界面的开源工具 Cacti, 用于查看CPU负载, 网络带宽利用率,它也提供了一个应用于监控 MongoDB 的插件。
GUI
- Fang of Mongo – 网页式,由Django和jQuery所构成。
- Futon4Mongo – 一个CouchDB Futon web的mongodb山寨版。
- Mongo3 – Ruby写成。
- MongoHub – 适用于OSX的应用程序。
- Opricot – 一个基于浏览器的MongoDB控制台, 由PHP撰写而成。
- Database Master — Windows的mongodb管理工具
- RockMongo — 最好的PHP语言的MongoDB管理工具,轻量级, 支持多国语言.
MongoDB 应用案例
下面列举一些公司MongoDB的实际应用:
- Craiglist上使用MongoDB的存档数十亿条记录。
- FourSquare,基于位置的社交网站,在Amazon EC2的服务器上使用MongoDB分享数据。
- Shutterfly,以互联网为基础的社会和个人出版服务,使用MongoDB的各种持久性数据存储的要求。
- bit.ly, 一个基于Web的网址缩短服务,使用MongoDB的存储自己的数据。
- spike.com,一个MTV网络的联营公司, spike.com使用MongoDB的。
- Intuit公司,一个为小企业和个人的软件和服务提供商,为小型企业使用MongoDB的跟踪用户的数据。
- sourceforge.net,资源网站查找,创建和发布开源软件免费,使用MongoDB的后端存储。
- etsy.com ,一个购买和出售手工制作物品网站,使用MongoDB。
- 纽约时报,领先的在线新闻门户网站之一,使用MongoDB。
- CERN,著名的粒子物理研究所,欧洲核子研究中心大型强子对撞机的数据使用MongoDB。
三、MongoDB快速上手
docker安装MongoDB
docker pull mongo:latest
docker images
docker run -itd --name mongo -p 27017:27017 mongo --auth
参数说明:
- -p 27017:27017 :映射容器服务的 27017 端口到宿主机的 27017 端口。外部可以直接通过 宿主机 ip:27017 访问到 mongo 的服务。
- –auth:需要密码才能访问容器服务。
接着使用以下命令添加用户和设置密码,并且尝试连接。
$ docker exec -it mongo mongo admin
# 创建一个名为 admin,密码为 123456 的用户。
> db.createUser({ user:'admin',pwd:'123456',roles:[ { role:'userAdminAnyDatabase', db: 'admin'},"readWriteAnyDatabase"]});
# 尝试使用上面创建的用户信息进行连接。
> db.auth('admin', '123456')
db.createUser({user: "root",pwd: "123456",roles:[{ role: "root", db: "admin" }]})
数据库使用
docker 安装时候无密码,使用mongo DB
进入
docker exec -it 0208ffd386bb bash
使用
mongo
查询数据库
show databases;
MongoDB 将数据存储为一个文档,BSON格式。由key 和 value组成
JSON 是把对象序列化为字符串,BSON 是把对象序列化为二进制。因为是用二进制的方式来序列化,所以无论是在时间(序列化、反序列化的速度)还是空间(序列化之后的体积)上都优于 JSON,缺点就是二进制没什么可读性可言。
{
"_id" : ObjectId("5e141148473cce6a9ef349c7"),
"title" : "批量更新",
"url" : "http://cxytiandi.com/blog/detail/8",
"author" : "yinjihuan",
"tags" : [
"java",
"mongodb",
"spring"
],
"visit_count" : NumberLong(10),
"add_time" : ISODate("2019-02-11T07:10:32.936+0000")
}
登陆数据库:db.auth(‘admin’, ‘123456’)
新建立数据库、查询数据库
use study
switched to db study
db
study
show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
新建并没有数据库,这时候需要新增数据
db.study.insert({“name”:“第一次学习”})
WriteResult({ “nInserted” : 1 })
show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
study 0.000GB
这个用户没有操作权限
切换admin数据库,添加用户
切换到admin库
use admin;
添加用户
db.createUser( {
user: “sa”,
pwd: “sa”,
roles: [ { role: “root”, db: “admin” } ]
});
既然已经添加了用户
用sa账号登录
db.auth(‘sa’,‘sa’);
切换数据库:use study
删除:db.dropDatabase()
集合操作
启动docker里面的MongoDB,用户连接
[root@WangYiHui ~]# docker exec -it mongo mongo admin
MongoDB shell version v5.0.3
connecting to: mongodb://127.0.0.1:27017/admin?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("aa1ce9b3-d418-42ab-814b-287df057044a") }
MongoDB server version: 5.0.3
> db.auth('sa','sa')
1
>
使用数据库
创建集合
简单集合名字是student,
> db.createCollection("student")
{ "ok" : 1 }
带参数集合
> db.createCollection("mycol", { capped : true, autoIndexId : true, size :
... 6142800, max : 10000 } )
{
"note" : "The autoIndexId option is deprecated and will be removed in a future release",
"ok" : 1
}
创建固定集合 mycol,整个集合空间大小 6142800 B, 文档最大个数为 10000 个。
查看集合
> show tables
mycol
student
study
> show collections
mycol
student
study
删除集合名是mycol
> db.mycol.drop()
true
文档操作
指定集合插入数据
db.student.save({"name":"王二辉","id":"1831310109","sex":"男"})
WriteResult({ "nInserted" : 1 })
查看集合里面的数据
db.student,find()
插入相同的数据内容,不会报错
> db.student.find()
{ "_id" : ObjectId("616ce52f5797b43351fcbee0"), "name" : "王一辉", "id" : "1831310109", "sex" : "男" }
{ "_id" : ObjectId("616ce56e5797b43351fcbee1"), "name" : "王二辉", "id" : "1831310109", "sex" : "男" }
{ "_id" : ObjectId("616ce5765797b43351fcbee2"), "name" : "王二辉", "id" : "1831310109", "sex" : "男" }
这个id是mongodb给我们分配的,如果插入相同id,就会报错
插入数据的键可以不需要双引号
> db.student.save({name:"王三辉",id:"1831310109",sex:"男"})
WriteResult({ "nInserted" : 1 })
更新数据,根据id更新数据
> db.student.update({"_id" : ObjectId("616ce52f5797b43351fcbee0")},{$set:{"name":"王三辉"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
根据内容
> db.student.update({"name":"王二辉"},{$set:{"name":"王三辉"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
如果多个文档类容相同、只能修改第一个文档
删除文档就是删除符合条件的文档
> db.student.remove({'name':'王三辉'})
WriteResult({ "nRemoved" : 3 })
查询
> db.student.find({"name":"王二辉"})
{ "_id" : ObjectId("616ce5765797b43351fcbee2"), "name" : "王二辉", "id" : "1831310109", "sex" : "男" }
易读方式
> db.student.find({"name":"王二辉"}).pretty()
{
"_id" : ObjectId("616ce5765797b43351fcbee2"),
"name" : "王二辉",
"id" : "1831310109",
"sex" : "男"
}
如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | {:} |
db.col.find({"by":"菜鸟教程"}).pretty() |
where by = '菜鸟教程' |
| 小于 | {:{$lt:}} |
db.col.find({"likes":{$lt:50}}).pretty() |
where likes < 50 |
| 小于或等于 | {:{$lte:}} |
db.col.find({"likes":{$lte:50}}).pretty() |
where likes <= 50 |
| 大于 | {:{$gt:}} |
db.col.find({"likes":{$gt:50}}).pretty() |
where likes > 50 |
| 大于或等于 | {:{$gte:}} |
db.col.find({"likes":{$gte:50}}).pretty() |
where likes >= 50 |
| 不等于 | {:{$ne:}} |
db.col.find({"likes":{$ne:50}}).pretty() |
where likes != 50 |
插入数据:
db.grade.save([{name:"张三","math":67,"java":88},{name:"李四","math":59,"java":93},{name:"王五","math":57,"java":56}])
and 查询
> db.grade.find({"name" : "王五", "math" : 57})
{ "_id" : ObjectId("616d0fcf32be258d716d48b5"), "name" : "王五", "math" : 57, "java" : 56 }
数学成绩大于60的学生
> db.grade.find({ "math" : {$gt:60}})
{ "_id" : ObjectId("616d0fcf32be258d716d48b3"), "name" : "张三", "math" : 67, "java" : 88 }
查找数学及格或者Java及格的学生
> db.grade.find({$or:[{ "math":{$gt:60}},{"java":{$gt:60}}]})
{ "_id" : ObjectId("616d0fcf32be258d716d48b3"), "name" : "张三", "math" : 67, "java" : 88 }
{ "_id" : ObjectId("616d0fcf32be258d716d48b4"), "name" : "李四", "math" : 59, "java" : 93 }
指定查询条数
> db.grade.find().limit(3)
{ "_id" : ObjectId("616d0fcf32be258d716d48b3"), "name" : "张三", "math" : 67, "java" : 88 }
{ "_id" : ObjectId("616d0fcf32be258d716d48b4"), "name" : "李四", "math" : 59, "java" : 93 }
{ "_id" : ObjectId("616d0fcf32be258d716d48b5"), "name" : "王五", "math" : 57, "java" : 56 }
limit(3)从第一条到第3条,
只查询第三条,那么就要排除前面的
> db.grade.find().limit(3).skip(2)
{ "_id" : ObjectId("616d0fcf32be258d716d48b5"), "name" : "王五", "math" : 57, "java" : 56 }
排序sort()
数学的降序与升序
> db.grade.find().sort({"math":-1})
{ "_id" : ObjectId("616d0fcf32be258d716d48b3"), "name" : "张三", "math" : 67, "java" : 88 }
{ "_id" : ObjectId("616d0fcf32be258d716d48b4"), "name" : "李四", "math" : 59, "java" : 93 }
{ "_id" : ObjectId("616d0fcf32be258d716d48b5"), "name" : "王五", "math" : 57, "java" : 56 }
> db.grade.find().sort({"math":1})
{ "_id" : ObjectId("616d0fcf32be258d716d48b5"), "name" : "王五", "math" : 57, "java" : 56 }
{ "_id" : ObjectId("616d0fcf32be258d716d48b4"), "name" : "李四", "math" : 59, "java" : 93 }
{ "_id" : ObjectId("616d0fcf32be258d716d48b3"), "name" : "张三", "math" : 67, "java" : 88 }
>
skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit()。
索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
创建索引
> db.grade.createIndex({name:1})
{
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"createdCollectionAutomatically" : false,
"ok" : 1
}
createIndex() 方法中你也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)。
>db.col.createIndex({"title":1,"description":-1})
1、查看集合索引
db.col.getIndexes()
2、查看集合索引大小
db.col.totalIndexSize()
3、删除集合所有索引
db.col.dropIndexes()
4、删除集合指定索引
db.col.dropIndex("索引名称")
MongoDB 聚合
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。
有点类似 SQL 语句中的 count(*)。
查询王五的总成绩
> db.grade.aggregate([{"$project":{"classes":["$math","$java"]}}, {"$unwind": "$classes"},{"$group": {"_id":ObjectId("616d0fcf32be258d716d48b5"),"classes":{ "$sum":"$classes"}}}])
{ "_id" : ObjectId("616d0fcf32be258d716d48b5"), "classes" : 420 }
求单文档内部各科成绩,因此可以考虑分成以下几个步骤。
db.class1.insert({chinese:92,math:98,english:88})
db.class1.insert({chinese:70,math:60,english:50})
db.class1.insert({chinese:56,math:90,english:90})
db.class1.aggregate([
/* 1. 使用project将各学课字段重新转换,为新字段classes */
{ "$project": {"classes": [ "$chinese", "$math", "$english"]}},
/* 2. 因为project转换成的project字段为数组形式,需要使用unwind各数组元素拆开*/
{ "$unwind": "$classes" },
/* 3. 使用group, 根据各文档_id求classes字段和 */
{ "$group": {"_id": "$_id","classes": { "$sum": "$classes" }}}
])
四、springboot整合MongoDB
pom文件添加依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-mongodbartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
MongoDB数据库连接地址
spring:
data:
mongodb:
username: sa
password: sa
host: 47.108.170.87
port: 27017
database: study
po实体类
package com.wang.mongodb.demo.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document("grade")//指明实体类对应mongodb的哪个集合
public class Grade implements Serializable {
@Id //与MongoDB数据库里面_id对应起来,并且数据类型要一致
private Object id;
private String name;
private int math;
private int java;
}
测试
package com.wang.mongodb.demo;
import com.wang.mongodb.demo.pojo.Grade;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.data.mongodb.core.query.Update;
import java.util.List;
@SpringBootTest
class DemoApplicationTests {
@Autowired
private MongoTemplate mongoTemplate;
@Test
void contextLoads() {
}
/** 查询集合里面的所有文档 */
@Test
public void getAll(){
List<Grade> list=mongoTemplate.findAll(Grade.class);
System.out.println(list);
}
/** 集合添加文档 */
@Test
public void add(){
Grade grade = new Grade(13,"赵六",88,99);
mongoTemplate.save(grade);
List<Grade> list=mongoTemplate.findAll(Grade.class);
System.out.println(list);
}
/** 修改文档 */
@Test
public void update(){
Grade grade = new Grade(13,"赵六",0,0);
Query query=new Query(Criteria.where("id").is(grade.getId()));
Update update= new Update().set("math", grade.getMath()).set("java",grade.getJava());
//更新查询返回结果集的第一条
mongoTemplate.updateFirst(query,update,Grade.class);
List<Grade> list=mongoTemplate.findAll(Grade.class);
System.out.println(list);
}
/** 删除文档 */
@Test
public void delete(){
Query query=new Query(Criteria.where("id").is(13));
mongoTemplate.remove(query,Grade.class);
List<Grade> list=mongoTemplate.findAll(Grade.class);
System.out.println(list);
}
}
db.createUser(
{
user: "wangyihui",
pwd: "123456",
roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]
}
)