如何挖掘闲置硬件资源的潜力-PrestoDB缓存加速实践小结
用户体验的追求是无限的,而成本是有限的,如何平衡?
用户体验很重要,降本也很重要。做技术的都知道,加机器堆资源可以解决绝大多数的用户觉得慢的问题,但要加钱。没什么用户体验是开发不了的,但要排期,本质也要钱。在成本有限,包括机器资源和开发人力都有限的情况下,如何提升用户体验呢?
对于大数据查询引擎来说,用户体验的第一优先级是快,天下武功唯快不破。而缓存技术是很好的选择,可以有效达到我们的目的。
硬件上,我们可以挖掘服务器闲置资源的潜力。因为在cpu利用率的评估体系下,服务器的内存,本地磁盘可能有空闲资源,能够挖掘出一些可用资源为我们所用。
技术上,选择开源社区大规模实践过的、有成功案例的,免费的方案,可以降低开发成本,事半功倍。
PrestoDB社区的缓存方案就是一个很好的选择。已经在Meta公司(原Facebook)大规模落地实践过了,Uber也有落地;有源码和技术分享的资料;Alluxio社区也提供了很多支持。基于种种原因,我们选择使用该技术进行查询加速,官方Blog链接:https://prestodb.io/blog/2021/02/04/raptorx。
但即使有成功案例,在内部落地时也会遇到各种问题,
在不增加机器资源的前提下,查询时间tp95提速超过1倍,其他查询速度指标也有50%到1倍的提升。具体效果会在《从PrestoSQL到PrestoDB-Presto计算引擎版本升级小结》一文中详细介绍,详见链接:https://mp.weixin.qq.com/s/bPn8ncT_AXcPXbfAy6bAQw
PrestoDB的查询机制
PrestoDB查询数据的大概流程如图所示。缓存方案本质是将从外部服务获取的数据缓存在内存和本地硬盘中,减少和外部系统的交互,以提供更好的查询体验。

由于把无限的外部数据拉到了本地,缓存要考虑数据有效性,容量控制,以及如何监控缓存的效果,即统计命中率。
应用缓存
Hive MetaStore缓存
查询一个普通的hive分区表,至少会有以下的读取元数据操作:获取表信息,获取满足过滤条件的分区名列表,根据分区的数量拆成几个并发线程,每个线程通过批量接口获取10到100个分区的分区信息。
当离线集群规模达到几千上万台,hive表会非常多,查询量也非常大。即使物理上拆分了若干个mysql数据库,若干个metastore服务,在访问高峰期查询hive metastore也是一个较为耗时的操作。
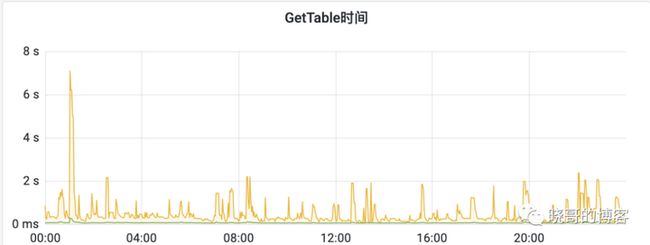
下图是某集群获取表操作的平均响应时间(绿线)和p99响应时间(橙线),可以看到即使是基本的获取表信息操作,在访问高峰时延时也会很高(Presto访问元数据的默认超时时间是10秒,超过10秒会重试三次,所以指标上限就是10秒)。

使用元数据缓存可以提高查询速度,减少metastore的交互,降低meastore的访问压力,但需要考虑时效性问题,即如何感知元数据变化。
元数据缓存是PrestoDB早期版本就有的功能,之前已经在线上使用了。实现基于guava cache,将hive metastore的表,分区等元数据信息缓存在内存中,通过刷新时间,过期时间和缓存实体的上限数的配置来控制数据的有效性和容量上限。
对一个元数据实体来说,第一次查询会先从远程获取,之后从缓存中读取。当元数据被缓存的时间达到刷新时间,再次请求还是会从缓存中读取,但会启动异步线程从远程获取并更新缓存,这样可以兼顾查询性能和数据有效性。当数据被缓存的时间超过过期时间,再次请求会堵塞,直到从远程获取并更新缓存。当缓存实体达到上限(按实体类型各自计算),再次写入缓存会删掉最旧的。以前使用PrestoSql的时候,遇到过同步缓存的线程死锁,原因是同步元数据的代码里有获取其他元数据实体缓存的逻辑,比如loadPartitionByName会先调用getTable方法,如果表缓存过期了且同步线程用满了就可能发生死锁。PrestoDB新版本不会在同步代码里获取其他实体的缓存,所以没有这个问题。
在PrestoDB新版本中,新加了两个参数,设置只缓存分区信息,和检查分区版本功能。
前者是提高缓存的有效性,不缓存库,表这些轻量级的元数据信息,只缓存分区信息。后者是在获取分区名列表时,会获取带版本的分区名信息,使用分区缓存前先比较分区的版本,版本一致才使用缓存。
但检查分区版本需要hive metastore有对应的接口,该功能并没有贡献给hive社区,PrestoDB社区版是用不了的。而只缓存分区信息,其实设计目的是配合检查分区版本来使用,单独使用依然存在数据不一致的问题。考虑到业务高峰期的请求延时,所以我们决定缓存包括表信息在内的所有元数据。那元数据有变化时如何保证有效性呢?下面具体分析一下:
当元数据的变化是Presto引擎引起的,Presto可以自动清理掉发生变化元数据的缓存。还可以通过jconsole调用jmx接口清理掉缓存。除此之外,元数据过期只能等刷新和过期时间,以及容量上限自动清理掉最旧的。
因为我们hive表主要是Spark批任务写入的,所以Presto引擎无法感知到元数据的变化。所以对表信息缓存来说,如果修改了表字段,如果存在缓存,可能要过段时间才能感知。对于分区名列表缓存,如果添加了新分区,也可能要过段时间才能感知。而如果分区发生了数据回溯,由于我们的批任务没有写入分区的详细统计信息,并且我们未开启使用分区元数据统计信息预过滤功能,所以分区元数据缓存不受影响。
综上所示,缓存了的表,分区名列表元数据要等缓存过期才能刷新。所以我们需要严格保证元数据有效性的集群,比如做批任务数据质量校验的,就不开启元数据缓存。希望提高查询性能接受短时间有效性延时的,开启缓存且只缓存10分钟。
在实践中,我们遇到了业务方自己也缓存查询结果,引起缓存时间放大的问题。当新增一个分区后,有时会较长时间才能查询到。为了解决该问题,我们提供了清理指定表分区缓存的http接口,业务系统自己知道新增了,在清理自己查询结果缓存的同时也会调用接口清理Presto的分区缓存。这样就不会有缓存放大的问题了。
另外,在使用中还发现一个表分区太多引起的缓存刷新问题。
获取分区信息一般调用partitionCache的getAll方法一次获取一批partitons,但达到refreshAfterWrite时间后,再次获取分区信息,partitionCache的getAll会触发线程池异步的批量调用load。如果分区很多,会产生大量请求单个分区的getPartition请求,给hive metastore造成了较大负载压力。有些业务查询的分区会越来越多,甚至一次要查7,8千个分区。由于由一次100个分区的批量接口变成了调用100次1个分区接口,这种表的分区缓存刷新会极大影响metastore的性能,造成所有访问metastore的请求都变慢。见下图大量获取分区引起的查询毛刺。
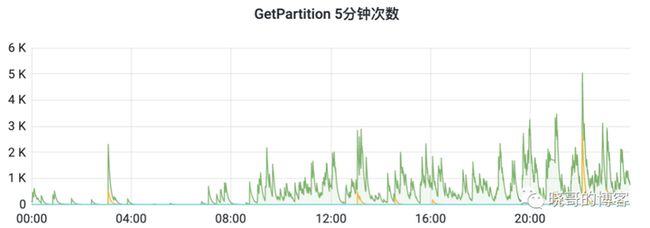


这个问题本质是,google guava的refreshAfterWrite机制和loadAll方法有冲突,即后台刷新机制和全量加载是有冲突的,为支持后台刷新,全量加载退化为批量的load一个。
详见guava社区讨论:https://github.com/google/guava/issues/1975,guava社区至今未解决。
所以我们在推动用户做数据治理,减少查询分区数的同时,关闭了refreshAfterWrite功能,这样就不会有大量的getPartition请求了。
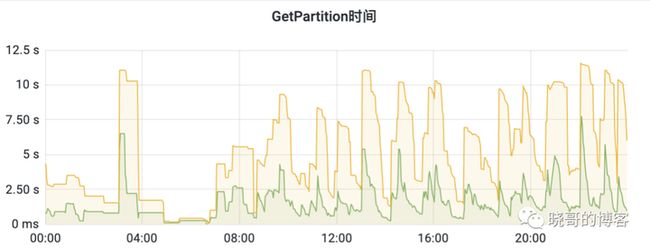
要注意的是一旦配置了超时时间ttl,refresh-interval就不可为空了。可以将两者配置的一样来关闭后台刷新功能。优化后的效果见下图,可以看到查询时间大幅降低了,毛刺也减少了。

未来我们会继续优化,将获取分区列表和其他元数据的配置分开,分区列表是批操作不开启后台刷新,其他元数据缓存开启。
数据文件列表缓存
hive.file-status-cache前缀的配置,可以根据目录key缓存目录下的数据文件信息列表,支持配置作用于哪些表,对s3这种对象存储提速会更明显。
只有确定分区不会回溯重写数据的表才能配置这个,否则查询可能会报错。实践中发现我们无法做这个假设,所以未配置这个缓存。
本地数据缓存
使用alluxio缓存HDFS数据。技术介绍可以阅读下面的链接:
https://mp.weixin.qq.com/s/2txWX40aOZVcyfxRL8KLKA
使用时要注意几点:
√ 首先,使用社区的PrestoDB版本,开启本地缓存功能,读数据会报错。原因是引用的社区版alluxio在schema中定义未定义file类型,而本地缓存的文件是file类型,需要在alluxio的源码里加上file类型,重新打包。
√ 其次,PrestoDB为实现hdfs本地缓存,用反射方式修改了FileSystem cache的实现,所以配置里禁用FileSystem cache,运行时会报错。而对于har类型的归档文件,是必须要关闭cache,设置fs.har.impl.disable.cache=true的,否则har文件的读取会报错。需要修改PrestoDB获取FileSystem的代码。
√ 再就是要考虑调度的一致性,同一个数据块的查询尽量调用同一个worker节点,否则会占用太多本地存储,命中率还不高。监控发现在高峰期缓存命中率只有30%,需要优化调度参数。在调度章节会详细介绍。
本地缓存一般放在ssd或更快的本地存储里。由于我们服务器的ssd磁盘存储小的只有120GB,所以alluxio本地存储只配置了60G,但效果依然很可观,单机的命中率有84%左右:


5分钟命中率图
下面介绍一些有用的alluxio缓存实践经验:
√ 指标名后缀统一
指标项的名字类似,com.facebook.alluxio:name=Client.CacheShadowCacheBytesHit.presto-test-001_docker,type=counters,带着hostName后缀。而我们的采集和展示规则需要指标名一致。
所以设置presto启动参数alluxio.user.app.id=presto,来统一指标名。
√ 使用ShadowCache
简单来说,这个功能是假设有无限的本地存储时,缓存命中率能达到多少。
Alluxio提供了一个Shadow Cache功能,可以使用布隆过滤器记录计算引擎访问过哪些数据以及总数据量的大小。每次计算引擎访问数据,都统计一次是否命中shadow cache中的数据。结合shadow cache和Alluxio的命中率可以检测业务是否适合使用缓存。
统计shadow cache的命中率,如果较低,则说明业务场景中极少会访问重复数据,那么是不适合使用缓存的。
如果shadow cache的命中率高,但Alluxio缓存的命中率低,说明业务场景适合使用缓存,但是当前Alluxio缓存的空间过小了。因为在数据文件被重复访问时,之前存入Alluxio的缓存,已经因为缓存满了而被淘汰了,所以重复访问时将得不到任何加速。那么此时加大Alluxio缓存空间,即换个大硬盘,会取得更好的加速收益。
shadow cache命中率统计见下图:
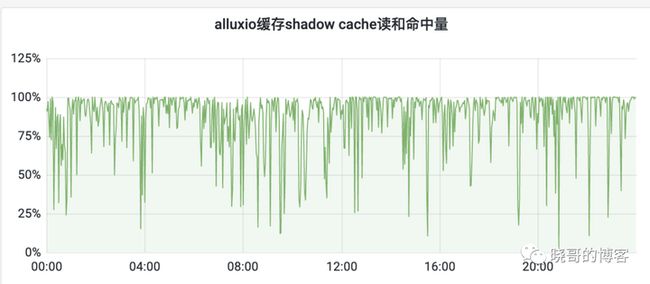
shadow cache五分钟粒度命中率
我们shadow平均数据命中率87% 左右,和目前实际的命中率84%差不多。说明当前缓存效果已经不错了。
√ 未统计到的不走缓存
worker繁忙时,master调度会随机选空闲的worker,即cacheable为false,这时不走alluxio的LocalCacheFileSystem,直接读底层文件系统。而现在的命中率统计,都是基于LocalCacheFileSystem的。但在业务高峰,很多查询没有走alluxio。那么如何统计计算读alluxio的数据量和读的总数据量(读alluxio+直接读底层文件系统之和)的比率呢?
可以用
(Client.CacheBytesReadCache.presto,type=meters:FiveMinuteRate + Client.CacheBytesRequestedExternal.presto,type=meters:FiveMinuteRate) * 300作为5分钟读alluxio的数据量,除以com.facebook.presto.hive:type=FileFormatDataSourceStats,name=hive:ReadBytes.FiveMinutes.Total ,五分钟hive读的总数据量指标,来计算最近5分钟的真实命中率比率。
√ put失败率高
presto日志里有很多alluxio的异常日志,监控也看到put缓存的失败率在业务高峰期比较高,见下图。
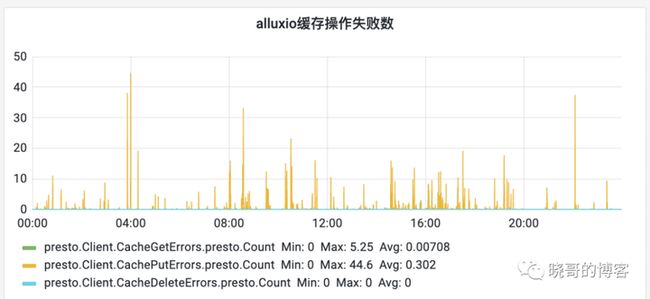
问题的本质是在高并发场景下,写入要先删除旧数据,并发删除同一个文件的不同块,尽可能递归删除父目录的策略,在删除父目录时遇到了并发冲突,中断写缓存。实际上,在异常的上下文里,父目录不存在只能说明被其他线程删了,继续操作就好。
做了个简单优化,删除旧缓存时,如果出现父目录不存在的异常,继续操作。社区已接收,见
https://github.com/Alluxio/alluxio/pull/16252
√ 数据有效性保障
alluxio的配置没有超时时间,只有容量。看代码在openfile时传入了文件的修改时间。但是,实现为了性能,并没有用传入的文件修改时间来判断缓存是否失效。所以只会容量满了被替换,不会由于时间变化过期。
这对于spark/hive sql写入的数据是没问题的,文件名自带jobid前缀,不会修改原有文件。但对于hudi,iceberg这些新技术,文件内容可能改变,就会有问题。需要做额外的优化加入版本的判断,并保证旧版本的缓存数据失效后能被清理掉。
√ 异步还是同步写
默认配置是不开启alluxio异步写缓存的,而同步写缓存会降低读操作的速度。那么异步写缓存会显著提高查询性能吗?
看alluxio实现,异步写是提交到16个线程的池中异步写,线程不够了直接写失败。所以异步线程配的少了会影响缓存写入,但异步线程多了又会影响worker自身的线程模型。在一个小集群做了测试,异步写并没有显著提高查询性能。所以目前在实践中未开启异步写功能。
未来我们会添加一种异步写策略,默认异步线程写缓存,当异步线程池满了就降级到当前线程写入。
数据文件索引块缓存
在内存中缓存orc和parquet文件的索引块。这个缓存有提速效果但不如alluxio数据缓存明显,按照官方示例配置就行,注意内存容量。
监控看,该缓存的命中率在87%到93%之间。
分片结果缓存
本质是按文件的数据块粒度,缓存一组计算的计算结果到本地存储里。比如某个文件块经过过滤,sum后的计算结果。由于业务方自己也做了查询结果缓存,所以该缓存的命中率不高,只有14%。
这个功能的实现上还有很多优化空间,未来可以持续优化。
调度策略
如上文所说,调度要考虑数据处理的一致性,同一个数据块的查询尽量调用同一个worker节点。所以需要配置调度策略为SOFT_AFFINITY,数据块一致性优先。
考虑到节点的上下线,hash策略需要设置为一致性hash,减少节点上下线对调度的影响。
另外,业务高峰期有的节点会太繁忙,调度会放弃一致性,随机选个节点。而在业务高峰时,所有节点都会繁忙,随机选择的意义不大,还是应该优先数据一致性。所以要把繁忙判断的阈值调大。具体配置如下
hive.node-selection-strategy=SOFT_AFFINITY
node-scheduler.node-selection-hash-strategy=CONSISTENT_HASHING
node-scheduler.max-splits-per-node=400
node-scheduler.max-pending-splits-per-task=40后续我们会针对k8s容器化环境,进行专门的调度策略优化,确保新的worker容器会优先使用宿主机上已存在,且无其他worker使用的缓存目录空间,并确保master将相应的数据处理请求发到该worker上。
想要了解更多关于Alluxio的干货文章、热门活动、专家分享,可点击进入【Alluxio智库】:
