协同多智能体学习的价值分解网络的原理与代码复现
概念引入
强化学习
马尔可夫决策过程
算法思想
VDN可以说是QMIX算法的前身
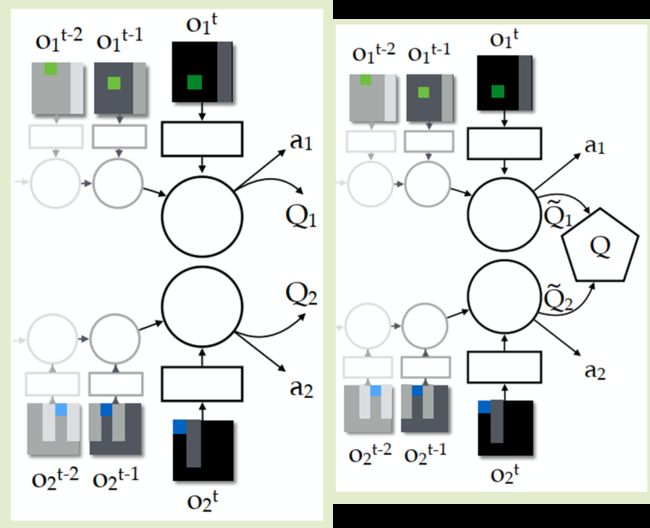
主要思想是把总的Q分解为多个Q之和,Q即对应智能体的动作价值

即:视多为一
但是也有副作用,那就是,累计出来的Q并不是针对具体情况,具体条件的Q,并没有具体意义。
算法复现
首先定义每个智能体的 QLearner类,将默认参数初始化后,判断为VDN网络,则将self.mixer初始化为VDNMixer(),并将网络参数复制给 self.optimiser使用优化算法RMSprop,其中参数根据类中的默认参数设置。
class QLearner:
def __init__(self,mac,scheme,logger,args):
self.args = args
self.mac=mac
self.logger = logger
self.params = list(mac.parametes())
self.last_target_update_episode=0
self.mixer = None
if args.mixer is not None:
if args.mixer == "vdn":
self.mixer = VDNMixer()
else:
raise ValueError("Mixer {} not recognised.".format(args.mixer))
self.params += list(self.mixer.parametes())
self.target_mixer = copy,deepcopy(self.mixer)
self.optimiser = RMSprop(params = self.params,lr = args.lr,alpha = args.optm_alpha,eps = args.optm_eps)
self.log_stats_t = -self.args.leraner_log_interval -1
在训练函数中,先获取有关参数的值,之后计算估计Q的值,将 agent_outs 存入 mac_out中,循环结束后,将 mac_out第一个维度数值进行叠加,形成新的tensor,最后为每个智能体所采取的操作选择Q值
def train(self,batch:EpisodeBatch,t_env:int,episode_num:int):
rewards = batch["rewards"][:,:-1]#视多为一
actions = batch["actions"][:,:-1]
terminated = batch["terminated"][:,:-1].float()
mask = batch["filled"][:,:-1].float()
mask[:,:-1]=mask[:,:-1]*(1 - terminated[:,:-1])
avail_actions = batch["avail_actions"]
mac_out = []
self.mac.init_hidden(batch.batch_size)
for t in range(batch.max_seq_length):
agent_outs = self.max.forward(batch,t = t)
mac_out.append(agent_outs)
mac_out - torch.stack(mac,dim = 1)
chosen_action_qvals = th.gather(mac_out[:,:-1],dim = 3,index = actions).squeeze(3)
之后计算目标网络所需的Q值,得到 target_mac_out.同上,对第一个维度进行叠加, target_mac_out = th.stack(target_mac_out[1:],dim=1)
剔除不可用动作,target_mac_out[avail_actions[:,1:]==0] = -9999999若设置为双Qlearning则同样的操作用于 mac_out
即原网络的Q值并得到其中的最大值索引,并提取 target_mac_out中对应的值,target_max_qvals = torch.gather(target_mac_out,3,cur_max_actions).squeeze(3)
否则,target_max_qvals = target_mac_out.max(dim=3)[0]
target_mac_out = []
self.target_mac.init_hidden(batch.batch_size)
for t in range(batch.max_seq_length):
target_agent_outs = self.target_mac.forward(batch,t=t)
target_mac_out.append(target_agent_outs)
target_mac_out = th.stack(target_mac_out[1:],dim=1)
target_mac_out[avail_actions[:,1:]==0] = -9999999
if self.args.double_q:
mac_out[avail_actions==0] = -9999999
cur_max_actions = mac_out[:,1:].max(dim=3,keepdim = True)[1]
else:
target_max_qvals = target_mac_out.max(dim=3)[0]
原网络和目标网络分别将操作选择Q值和最大Q值估计输入网络,之后计算1步Q-learning目标,targets = rewards + self.args.gamma * (1 - terminated) * target_max_qvals
和 td_error = (chosen_action_qvals - targets.detach())输出来自填充数据的目标,masked_td_error = td_error * mask最后计算l2损失,即实际数据的平均值
if self,mixer is not None:
chosen_action_qvals = self.mixer(chosen_action_qvals,batch["state"][:,:-1])
target_max_qvals = self.target_mixer(target_max_qvals,batch["state"][:,:-1])
targets = rewards + self.args.gamma * (1 - terminated) * target_max_qvals
td_error = (chosen_action_qvals - targets.detach())
mask = mask.expend_as(td_error)
masked_td_error = td_error * mask
loss = (masked_td_error **2).sum()/mask.sum()