k8s集群部署vmalert和prometheusalert实现钉钉告警
先决条件
安装以下软件包:git, kubectl, helm, helm-docs,请参阅本教程。
1、安装 helm
wget https://xxx-xx.oss-cn-xxx.aliyuncs.com/helm-v3.8.1-linux-amd64.tar.gz
tar xvzf helm-v3.8.1-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin
rm -rf linux-amd642、安装victoria-metrics-alert
(1)使用以下命令添加 helm chart存储库
helm repo add vm https://victoriametrics.github.io/helm-charts/
helm repo update(2)列出vm/victoria-metrics-alert可供安装的helm版本
helm search repo vm/victoria-metrics-alert -l(3)victoria-metrics-alert将图表的默认值导出到文件values.yaml
helm show values vm/victoria-metrics-alert > values.yaml(4)根据环境需要更改values.yaml文件中的值,完整配置参考如下
# Default values for victoria-metrics-alert.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
serviceAccount:
# Specifies whether a service account should be created
create: true
# Annotations to add to the service account
annotations: {}
# The name of the service account to use.
# If not set and create is true, a name is generated using the fullname template
name:
# mount API token to pod directly
automountToken: true
imagePullSecrets: []
rbac:
create: true
pspEnabled: true
namespaced: false
extraLabels: {}
annotations: {}
server:
name: server
enabled: true
image:
repository: victoriametrics/vmalert
tag: "" # rewrites Chart.AppVersion
pullPolicy: IfNotPresent
nameOverride: ""
fullnameOverride: ""
## See `kubectl explain poddisruptionbudget.spec` for more
## ref: https://kubernetes.io/docs/tasks/run-application/configure-pdb/
podDisruptionBudget:
enabled: false
# minAvailable: 1
# maxUnavailable: 1
labels: {}
# -- Additional environment variables (ex.: secret tokens, flags) https://github.com/VictoriaMetrics/VictoriaMetrics#environment-variables
env:
[]
# - name: VM_remoteWrite_basicAuth_password
# valueFrom:
# secretKeyRef:
# name: auth_secret
# key: password
replicaCount: 1
# deployment strategy, set to standard k8s default
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
# specifies the minimum number of seconds for which a newly created Pod should be ready without any of its containers crashing/terminating
# 0 is the standard k8s default
minReadySeconds: 0
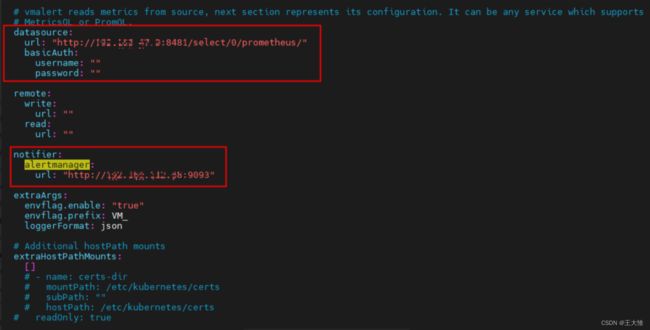
# vmalert reads metrics from source, next section represents its configuration. It can be any service which supports
# MetricsQL or PromQL.
datasource:
url: "http://192.168.47.9:8481/select/0/prometheus/"
basicAuth:
username: ""
password: ""
remote:
write:
url: ""
read:
url: ""
notifier:
alertmanager:
url: "http://192.168.112.68:9093"
extraArgs:
envflag.enable: "true"
envflag.prefix: VM_
loggerFormat: json
# Additional hostPath mounts
extraHostPathMounts:
[]
# - name: certs-dir
# mountPath: /etc/kubernetes/certs
# subPath: ""
# hostPath: /etc/kubernetes/certs
# readOnly: true
# Extra Volumes for the pod
extraVolumes:
[]
#- name: example
# configMap:
# name: example
# Extra Volume Mounts for the container
extraVolumeMounts:
[]
# - name: example
# mountPath: /example
extraContainers:
[]
#- name: config-reloader
# image: reloader-image
service:
annotations: {}
labels: {}
clusterIP: ""
## Ref: https://kubernetes.io/docs/user-guide/services/#external-ips
##
externalIPs: []
loadBalancerIP: ""
loadBalancerSourceRanges: []
servicePort: 8880
type: ClusterIP
# Ref: https://kubernetes.io/docs/tasks/access-application-cluster/create-external-load-balancer/#preserving-the-client-source-ip
# externalTrafficPolicy: "local"
# healthCheckNodePort: 0
ingress:
enabled: false
annotations: {}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: 'true'
extraLabels: {}
hosts: []
# - name: vmselect.local
# path: /select
# port: http
tls: []
# - secretName: vmselect-ingress-tls
# hosts:
# - vmselect.local
# For Kubernetes >= 1.18 you should specify the ingress-controller via the field ingressClassName
# See https://kubernetes.io/blog/2020/04/02/improvements-to-the-ingress-api-in-kubernetes-1.18/#specifying-the-class-of-an-ingress
# ingressClassName: nginx
# -- pathType is only for k8s >= 1.1=
pathType: Prefix
podSecurityContext: {}
# fsGroup: 2000
securityContext:
{}
# capabilities:
# drop:
# - ALL
# readOnlyRootFilesystem: true
# runAsNonRoot: true
# runAsUser: 1000
resources:
{}
# We usually recommend not to specify default resources and to leave this as a conscious
# choice for the user. This also increases chances charts run on environments with little
# resources, such as Minikube. If you do want to specify resources, uncomment the following
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
# limits:
# cpu: 100m
# memory: 128Mi
# requests:
# cpu: 100m
# memory: 128Mi
# Annotations to be added to the deployment
annotations: {}
# labels to be added to the deployment
labels: {}
# Annotations to be added to pod
podAnnotations: {}
podLabels: {}
nodeSelector: {}
priorityClassName: ""
tolerations: []
affinity: {}
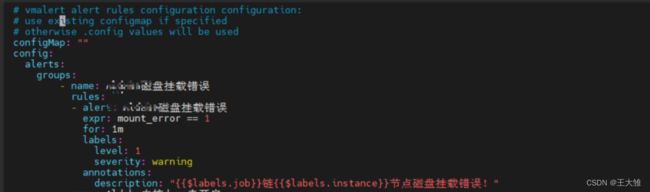
# vmalert alert rules configuration configuration:
# use existing configmap if specified
# otherwise .config values will be used
configMap: ""
config:
alerts:
groups:
- name: 磁盘挂载错误
rules:
- alert: 磁盘挂载错误
expr: mount_error == 1
for: 1m
labels:
level: 1
severity: warning
annotations:
description: "{{$labels.job}}链{{$labels.instance}}节点磁盘挂载错误!"
serviceMonitor:
enabled: false
extraLabels: {}
annotations: {}
# interval: 15s
# scrapeTimeout: 5s
# -- Commented. HTTP scheme to use for scraping.
# scheme: https
# -- Commented. TLS configuration to use when scraping the endpoint
# tlsConfig:
# insecureSkipVerify: true
alertmanager:
enabled: true
replicaCount: 1
podMetadata:
labels: {}
annotations: {}
image: prom/alertmanager
tag: v0.20.0
retention: 120h
nodeSelector: {}
priorityClassName: ""
resources: {}
tolerations: []
imagePullSecrets: []
podSecurityContext: {}
extraArgs: {}
# key: value
# external URL, that alertmanager will expose to receivers
baseURL: ""
# use existing configmap if specified
# otherwise .config values will be used
configMap: ""
config:
global:
resolve_timeout: 5m
route:
# default receiver
receiver: ops_notify
# tag to group by
group_by: [alertname]
# How long to initially wait to send a notification for a group of alerts
group_wait: 30s
# How long to wait before sending a notification about new alerts that are added to a group
group_interval: 60s
# How long to wait before sending a notification again if it has already been sent successfully for an alert
repeat_interval: 1h
receivers:
- name: ops_notify
webhook_configs:
- url: http://192.168.157.59:8080/prometheusalert?type=dd&tpl=prometheus-dd&split=false
send_resolved: true
inhibit_rules:
- source_match:
severity: 'warning'
target_match:
severity: 'warning'
equal: ['alertname', 'job']
templates: {}
# alertmanager.tmpl: |-
service:
annotations: {}
type: ClusterIP
port: 9093
# if you want to force a specific nodePort. Must be use with service.type=NodePort
# nodePort:
ingress:
enabled: false
annotations: {}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: 'true'
extraLabels: {}
hosts: []
# - name: alertmanager.local
# path: /
# port: web
tls: []
# - secretName: alertmanager-ingress-tls
# hosts:
# - alertmanager.local
# For Kubernetes >= 1.18 you should specify the ingress-controller via the field ingressClassName
# See https://kubernetes.io/blog/2020/04/02/improvements-to-the-ingress-api-in-kubernetes-1.18/#specifying-the-class-of-an-ingress
# ingressClassName: nginx
# -- pathType is only for k8s >= 1.1=
pathType: Prefix
persistentVolume:
# -- Create/use Persistent Volume Claim for alertmanager component. Empty dir if false
enabled: false
# -- Array of access modes. Must match those of existing PV or dynamic provisioner. Ref: [http://kubernetes.io/docs/user-guide/persistent-volumes/](http://kubernetes.io/docs/user-guide/persistent-volumes/)
accessModes:
- ReadWriteOnce
# -- Persistant volume annotations
annotations: {}
# -- StorageClass to use for persistent volume. Requires alertmanager.persistentVolume.enabled: true. If defined, PVC created automatically
storageClass: ""
# -- Existing Claim name. If defined, PVC must be created manually before volume will be bound
existingClaim: ""
# -- Mount path. Alertmanager data Persistent Volume mount root path.
mountPath: /data
# -- Mount subpath
subPath: ""
# -- Size of the volume. Better to set the same as resource limit memory property.
size: 50Mi

(5)使用命令测试安装:
helm install vmalert vm/victoria-metrics-alert -f values.yaml -n victoria-metrics --debug --dry-run(6)使用以下命令安装
helm install vmalert vm/victoria-metrics-alert -f values.yaml -n victoria-metrics(7)通过运行以下命令获取 pod 列表
kubectl get pods -A | grep 'alert'(8)通过运行以下命令获取应用程序
helm list -f vmalert -n victoria-metrics(9)使用命令查看应用程序版本的历史记录vmalert
helm history vmalert -n victoria-metrics(10)更新配置
cd /root/vmalert
#修改value.yaml文件
helm upgrade vmalert vm/victoria-metrics-alert -f values.yaml -n victoria-metrics(11)查看service
kubectl get svc -n victoria-metrics
3、安装prometheusalert
(1)使用helm部署
git clone https://github.com/feiyu563/PrometheusAlert.git
cd PrometheusAlert/example/helm/prometheusalert
#如需修改配置文件,请更新config中的app.conf
helm install -n victoria-metrics prometheus-alert .(2)values.yaml配置文件参考
cat /root/PrometheusAlert/example/helm/prometheusalert/values.yaml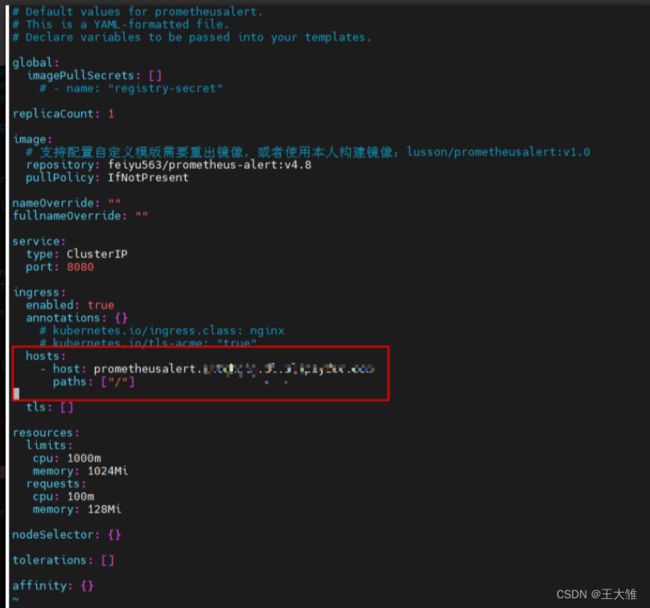
# Default values for prometheusalert.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
global:
imagePullSecrets: []
# - name: "registry-secret"
replicaCount: 1
image:
# 支持配置自定义模版需要重出镜像,或者使用本人构建镜像:lusson/prometheusalert:v1.0
repository: feiyu563/prometheus-alert:v4.8
pullPolicy: IfNotPresent
nameOverride: ""
fullnameOverride: ""
service:
type: ClusterIP
port: 8080
ingress:
enabled: true
annotations: {}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
hosts:
- host: prometheusalert.xxxxx.com
paths: ["/"]
tls: []
resources:
limits:
cpu: 1000m
memory: 1024Mi
requests:
cpu: 100m
memory: 128Mi
nodeSelector: {}
tolerations: []
affinity: {}
(3)app.conf配置参考
cat /root/PrometheusAlert/example/helm/prometheusalert/config/app.conf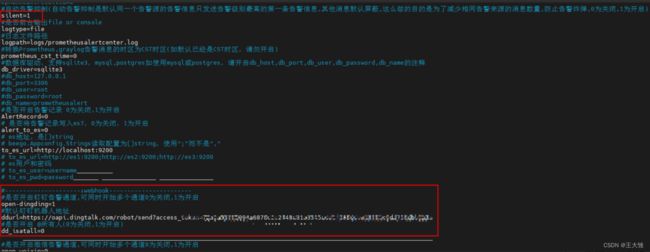
(4)ingress.yaml配置参考
cat /root/PrometheusAlert/example/helm/prometheusalert/templates/ingress.yaml
{{- if .Values.ingress.enabled -}}
{{- $fullName := include "prometheusalert.fullname" . -}}
{{- $svcPort := .Values.service.port -}}
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: {{ $fullName }}
labels:
{{ include "prometheusalert.labels" . | indent 4 }}
{{- with .Values.ingress.annotations }}
annotations:
{{- toYaml . | nindent 4 }}
{{- end }}
spec:
{{- if .Values.ingress.tls }}
tls:
{{- range .Values.ingress.tls }}
- hosts:
{{- range .hosts }}
- {{ . | quote }}
{{- end }}
secretName: {{ .secretName }}
{{- end }}
{{- end }}
rules:
{{- range .Values.ingress.hosts }}
- host: {{ .host | quote }}
http:
paths:
{{- range .paths }}
- path: {{ . }}
pathType: Prefix
backend:
service:
name: {{ $fullName }}
port:
number: {{ $svcPort }}
{{- end }}
{{- end }}
{{- end }}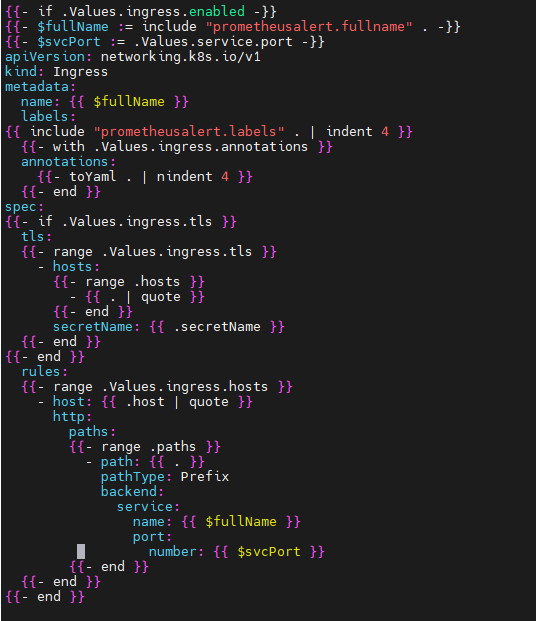
(5)更新配置
cd /root/PrometheusAlert/example/helm/prometheusalert
helm upgrade -n victoria-metrics prometheus-alert .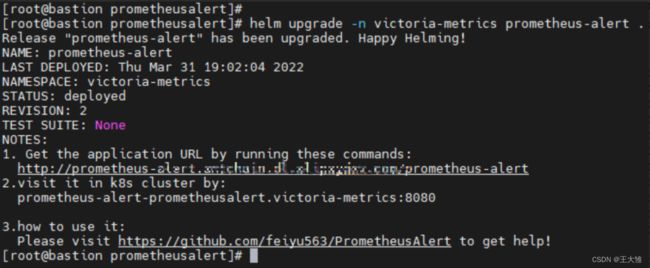
(6)重启pod
删除Pod
helm delete prometheus-alert -n victoria-metrics
查看pods和service
kubectl get pods -n victoria-metrics
kubectl get svc -n victoria-metrics
重新安装
helm install -n victoria-metrics prometheus-alert .
查看pods和service
kubectl get pods -n victoria-metrics
kubectl get svc -n victoria-metrics(1)告警测试
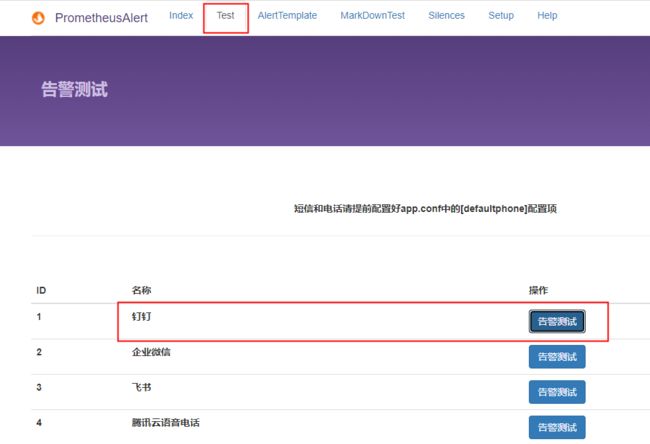
模板内容:
{{ $var := .externalURL}}{{ range $k,$v:=.alerts }}
{{if eq $v.status "resolved"}}
## [巡检恢复信息]({{$v.generatorURL}})
#### [{{$v.labels.alertname}}]({{$var}})
###### 告警级别:{{$v.labels.level}}
###### 开始时间:{{$v.startsAt}}
###### 故障主机:{{$v.labels.instance}}
##### {{$v.annotations.description}}
{{else}}
## [巡检告警信息]({{$v.generatorURL}})
#### [{{$v.labels.alertname}}]({{$var}})
###### 告警级别:{{$v.labels.level}}
###### 开始时间:{{$v.startsAt}}
###### 故障主机:{{$v.labels.instance}}
##### {{$v.annotations.description}}
{{end}}
{{ end }}(2)查看日志
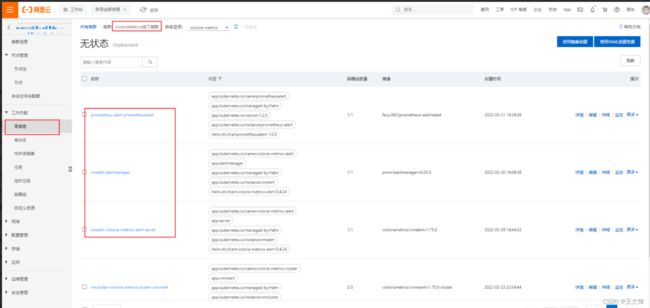
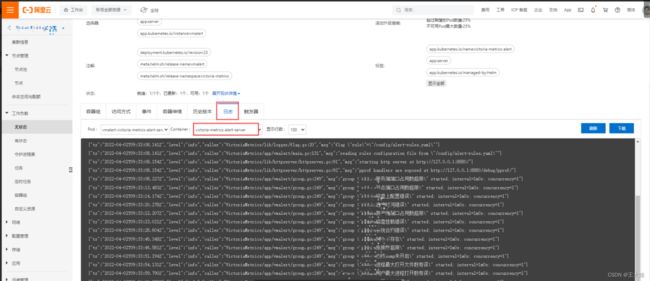
(3)查看钉钉告警
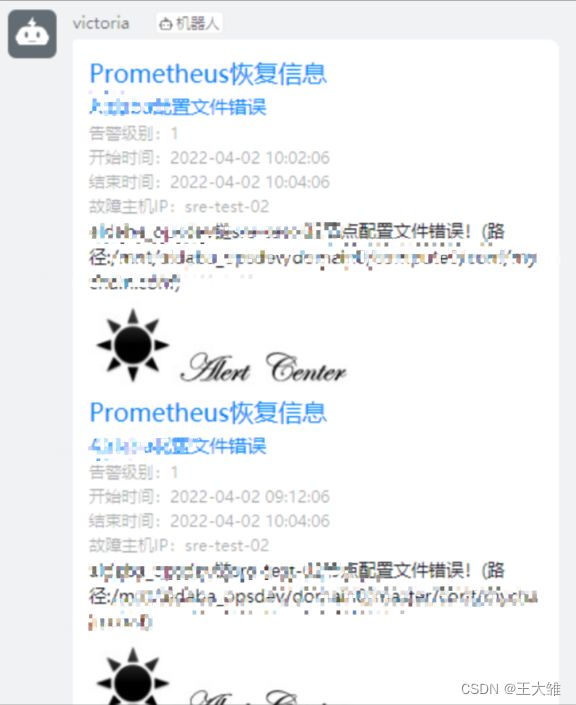
参考文档:https://github.com/VictoriaMetrics/helm-charts/tree/master/charts/victoria-metrics-alert
参考文档:https://github.com/feiyu563/PrometheusAlert/tree/master/example/helm/prometheusalert