使用python读Excel文件并写入另一个xls模版
效果如下:
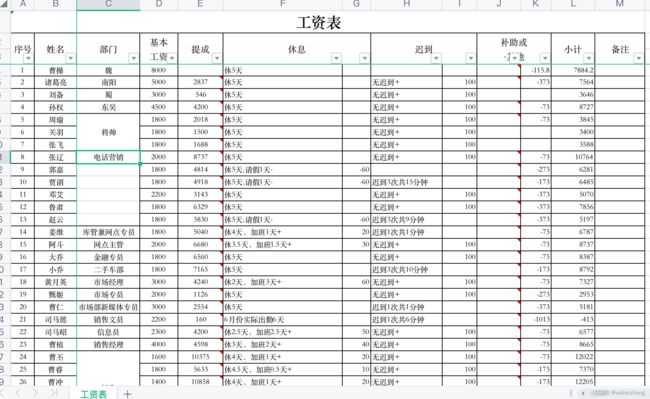
原文件内容
转化后的内容

大致代码如下:
1. load_it.py
#!/usr/bin/env python
import re
from datetime import datetime
from io import BytesIO
from pathlib import Path
from typing import List, Union
from fastapi import HTTPException
from openpyxl import load_workbook
RE_SPACES = re.compile(r"\s{2,}")
def slim(s: str) -> str:
return RE_SPACES.sub(" ", s)
class ValidationError(HTTPException):
def __init__(self, detail: str, status_code: int = 400):
super().__init__(status_code, detail=detail)
def remove_author(s: str) -> str:
if s := s.replace("作者:\n", "").replace("Administrator:\n", ""):
return str(s)
return ''
def read_excel(filename: Union[Path, str, bytes, BytesIO]):
if isinstance(filename, bytes):
filename = BytesIO(filename)
return load_workbook(filename)
def load(filename: Union[Path, str, bytes, BytesIO]):
wb = read_excel(filename)
sheet_name = "工资表"
try:
sheet = wb[sheet_name]
except KeyError:
try:
sheet = wb["Sheet1"]
except KeyError:
raise ValidationError(f"未找到名称为{sheet_name!r}的工作表")
title = sheet.cell(1, 1).value.strip()
now = datetime.now()
if "月" in title:
remark = title.split("年")[-1].strip("表").replace("份", "")
else:
if (month := now.month - 1) == 0:
month = 12
remark = f"{month}月工资"
day = f"{now:%Y.%m.%d}"
lines: List[list] = []
for row in range(4, sheet.max_row):
xuhao = sheet.cell(row, 1).value
if xuhao and (isinstance(xuhao, int) or xuhao.isdigit()):
name = sheet.cell(row, 2).value
total = 0
if (base := sheet.cell(row, 4).value) is None:
base = "/"
else:
if isinstance(base, str):
if base.startswith("="):
base = eval(base[1:])
else:
raise TypeError(f"Expect int value, got: {base=}")
total += base
commission_comment = "" # 提成批注
commission_cell = sheet.cell(row, 5)
if (commission := commission_cell.value) is None:
commission = "/"
else:
if isinstance(commission, str) and commission.startswith('='):
commission = eval(commission[1:])
total += commission
if _cc := commission_cell.comment:
if _ct := _cc.text:
commission_comment = remove_author(_ct)
if (attend := sheet.cell(row, 6).value) is None:
if (attend := sheet.cell(row, 13).value) is None:
attend = "/"
if (attend_money := sheet.cell(row, 7).value) is not None:
total += attend_money
attend = attend.strip().strip("+-/").strip()
if attend_money > 0:
attend += f" +{attend_money}"
else:
attend += f" {attend_money}"
if (late := sheet.cell(row, 8).value) is None:
late = "/"
else:
late = slim(late)
if late_money := sheet.cell(row, 9).value:
total += late_money
if late_money > 0:
late = f"{late}{late_money}"
else:
late = late.strip("/") + str(late_money)
if subsidy_value := sheet.cell(row, 11).value: # 补助
if isinstance(subsidy_value, str) and subsidy_value.startswith("="):
subsidy_value = eval(subsidy_value[1:])
try:
total += subsidy_value
except TypeError:
raise ValidationError(
f"第{row}行第11列数据异常:预期为数值,得到的是{subsidy_value!r}"
)
subsidy = "/"
if _c := sheet.cell(row, 10).comment:
if _s := _c.text:
subsidy = remove_author(_s)
one = [
name,
base,
commission,
attend,
late,
subsidy,
total,
remark,
day,
commission_comment,
]
lines.append(one)
return lines
def main():
import sys
if not sys.argv[1:]:
print("No args, do nothing.")
return
print(load(sys.argv[1]))
if __name__ == "__main__":
main()
2. gen_excel.py
#!/usr/bin/env python
from datetime import datetime
from pathlib import Path
from typing import List, Optional, Tuple, Union
import xlrd
import xlwt
from xlutils.copy import copy as xls_copy
from load_it import load, read_excel, remove_author
from settings import BASE_DIR, MEDIA_ROOT
SAMPLE = "salary_tips.xls"
DataType = Union[int, float, str, None]
def cell_style(is_top: bool = False, is_bottom: bool = False, has_border=True):
"""单元格样式"""
style = xlwt.XFStyle()
# 字体大小,11为字号,20为衡量单位
# font = xlwt.Font()
style.font.height = 20 * 9
align = xlwt.Alignment()
# 0x01(左端对齐)、0x02(水平方向上居中对齐)、0x03(右端对齐)
align.horz = 0x02
# 0x00(上端对齐)、 0x01(垂直方向上居中对齐)、0x02(底端对齐)
align.vert = 0x01
# 设置自动换行
align.wrap = 1
style.alignment = align
# 设置边框
# 细实线:1,小粗实线:2,细虚线:3,中细虚线:4,大粗实线:5,双线:6,细点虚线:7
# 大粗虚线:8,细点划线:9,粗点划线:10,细双点划线:11,粗双点划线:12,斜点划线:13
if has_border:
borders = xlwt.Borders()
borders.left = 2
borders.right = 2
borders.top = 1 + is_top
borders.bottom = 1 + is_bottom
style.borders = borders
return style
def boom(tips: List[List[Tuple[int, int, DataType]]]) -> str:
"""将数据填入模板生成Excel表"""
sample = BASE_DIR / SAMPLE
xls = xls_copy(xlrd.open_workbook(sample, formatting_info=True))
ws = xls.get_sheet(0)
style = cell_style()
top_style = cell_style(is_top=True)
bottom_style = cell_style(is_bottom=True)
plain_style = cell_style(has_border=False)
last_index = 8
for datas in tips:
for i, d in enumerate(datas[:-1]):
if i == 0:
ws.write(*d, top_style)
elif i == last_index:
ws.write(*d, bottom_style)
else:
ws.write(*d, style)
if _tc := datas[-1]:
row, col, text = _tc
if text:
ws.write_merge(row, row, col - 1, col, text, plain_style)
fname = MEDIA_ROOT / f"gzt_{datetime.now():%Y%m%d%H%M%S}.xls"
try:
xls.save(fname)
except TypeError as e:
print("May be you can look at this to fix it:")
print("https://blog.csdn.net/zhangvalue/article/details/105170305")
raise e
return str(fname).replace(str(BASE_DIR), "") # 返回相对路径
def build_tips(lines: List[List[DataType]]):
row_delta = 10 # 每隔10行填下一排的数据
col_delta = 3 # 每隔3列填下一组数据
line_tip = 5 # 每行有5个工资条
row_begin = 0 # 从第一行开始
col_begin = 1 # 从第二列开始填数据(第一列是固定的表头)
tips = []
for tip_index, tip in enumerate(lines):
first_row = row_begin + tip_index // line_tip * row_delta
col_index = col_begin + tip_index % line_tip * col_delta
d = [
(row_index + first_row, col_index, value)
for row_index, value in enumerate(tip)
]
tips.append(d)
return tips
def burn_life(content: bytes) -> str:
return boom(build_tips(load(content)))
def dear_sister(content: bytes, origin_name: Optional[str] = None) -> str:
"""2022-04-04 亲爱的妹妹想要一个可以把批注提取出来的"""
wb = read_excel(content)
sheet = wb.worksheets[0]
count = 0
# openpyxl的行和列都是从1开始
for row in range(1, sheet.max_row):
for col in range(1, sheet.max_column):
cell = sheet.cell(row, col)
if comment := cell.comment:
if text := comment.text:
cell.value = remove_author(text)
count += 1
if origin_name:
fname = MEDIA_ROOT / f"{Path(origin_name).stem}-批注提取{count}.xls"
else:
fname = MEDIA_ROOT / f"批注提取{count}.xls"
wb.save(fname)
return str(fname).replace(str(BASE_DIR), "") # 返回相对路径
def main():
import sys
if not sys.argv[1:]:
print("No args, do nothing.")
return
if (p := Path(sys.argv[1])).is_file():
lines = load(p.read_bytes())
else:
day = f"{datetime.now():%Y.%m.%d}"
ss = [
"狄仁杰",
1600,
360,
"休5天,请假7.5天 -400",
"迟到3次共16分钟",
"扣社保-373\n工龄+100\n漏刷卡6次-300",
987,
"12月工资",
day,
]
lines = [ss, ss]
print(boom(build_tips(lines)))
if __name__ == "__main__":
main()