【含泪提速!】一文全解相似度算法、跟踪算法在各个AI场景的应用(附代码)
大家好,我是cv君,大家是否为深度学习算法速度感到困扰?本次cv君倾力分享一个优秀的方法,通过相似度+跟踪方案优化速度问题,并提高了检测、分割算法稳定性,附带代码,一起肝起来吧~
今天给大家全解一下图像相似度算法以及跟踪算法。简单说就是判断俩图片、视频、画面是否相似的算法。
能做什么?
1: 当你老板说你目标检测算法耗时、耗电、耗内存的时候:请务必加上相似度算法!超低能耗、超快速度,适用于部分场景:你的检测算法慢,功耗高时,实际上,并不需要每秒都检测,检测算法ok,那么你前几帧检测,后几十帧跟踪,都行。相似度过小:即画面变化过大后,就重新检测;或者时间过了几秒,重新检测,再跟踪,功耗大大降低。
2: 判断画面是否变化,有人闯入你家,黑暗的时候,蒙面大盗是难以被目标检测、人脸识别的。
3: 相机在预览时,画面是否改变:调焦,物体运动,画面是否被放大缩小,云台是否转动。
4:画面是否稳定。
5:图像之间谁最相似、最不相似。
6:用作超分、去雾、去雨、去摩、图像修复、各种图像调试,以达到与你的GT最相似,用作损失计算。
等等
相似度算法全解
1.余弦相似度计算
把图片表示成一个向量,通过计算向量之间的余弦距离来表征两张图片的相似度。
# -*- coding: utf-8 -*-
# !/usr/bin/env python
# 余弦相似度计算
from PIL import Image
from numpy import average, dot, linalg
# 对图片进行统一化处理
def get_thum(image, size=(64, 64), greyscale=False):
# 利用image对图像大小重新设置, Image.ANTIALIAS为高质量的
image = image.resize(size, Image.ANTIALIAS)
if greyscale:
# 将图片转换为L模式,其为灰度图,其每个像素用8个bit表示
image = image.convert('L')
return image
# 计算图片的余弦距离
def image_similarity_vectors_via_numpy(image1, image2):
image1 = get_thum(image1)
image2 = get_thum(image2)
images = [image1, image2]
vectors = []
norms = []
for image in images:
vector = []
for pixel_tuple in image.getdata():
vector.append(average(pixel_tuple))
vectors.append(vector)
# linalg=linear(线性)+algebra(代数),norm则表示范数
# 求图片的范数
norms.append(linalg.norm(vector, 2))
a, b = vectors
a_norm, b_norm = norms
# dot返回的是点积,对二维数组(矩阵)进行计算
res = dot(a / a_norm, b / b_norm)
return res
image1 = Image.open('010.jpg')
image2 = Image.open('011.jpg')
cosin = image_similarity_vectors_via_numpy(image1, image2)
print('图片余弦相似度', cosin)
# 输出结果
# 图片余弦相似度 0.98584161582533342.哈希算法计算图片的相似度
cv君简介一下Hash哈希算法是一类算法的总称,包括aHash、pHash、dHash。顾名思义,哈希不是以严格的方式计算Hash值,而是以更加相对的方式计算哈希值,因为“相似”与否,就是一种相对的判定。
几种hash值的比较:
-
aHash:平均值哈希。速度比较快,但是常常不太精确。
-
pHash:感知哈希。精确度比较高,但是速度方面较差一些。
-
dHash:差异值哈希。精确度较高,且速度也非常快
值哈希算法、差值哈希算法和感知哈希算法都是值越小,相似度越高,取值为0-64,即汉明距离中,64位的hash值有多少不同。三直方图和单通道直方图的值为0-1,值越大,相似度越高。

cv君把算法的时间也打印出来。我们把图像都缩放到8*8进行相似度的计算,此时余弦相似度要花16.9ms,而Hash算法都接近0ms,3通道直方图需要 5ms,单通道直方图需要1ms,我们可以看到,下面的两张图片,有几处不同,但整体相似,我们一眼看到就好主观会认为很相似,但细细看,会发现,有几处不同,所以,相似度,几种方法都不太相同。
不过,我们需要一种稳定的算法,该相似的相似,不该相似的不相似。
cv君通过广泛实验,建议大家使用单通道直方图方案。或者感知哈希。

代码
# -*- coding: utf-8 -*-
# !/usr/bin/env python
# 余弦相似度计算
from PIL import Image
from numpy import average, dot, linalg
import time
# 对图片进行统一化处理
def get_thum(image, size=(8, 8), greyscale=False):
# 利用image对图像大小重新设置, Image.ANTIALIAS为高质量的
image = image.resize(size, Image.ANTIALIAS)
if greyscale:
# 将图片转换为L模式,其为灰度图,其每个像素用8个bit表示
image = image.convert('L')
return image
# 计算图片的余弦距离
def image_similarity_vectors_via_numpy(image1, image2):
image1 = get_thum(image1)
image2 = get_thum(image2)
images = [image1, image2]
vectors = []
norms = []
for image in images:
vector = []
for pixel_tuple in image.getdata():
vector.append(average(pixel_tuple))
vectors.append(vector)
# linalg=linear(线性)+algebra(代数),norm则表示范数
# 求图片的范数
norms.append(linalg.norm(vector, 2))
a, b = vectors
a_norm, b_norm = norms
# dot返回的是点积,对二维数组(矩阵)进行计算
res = dot(a / a_norm, b / b_norm)
return res
image1 = Image.open('1.jpg')
image2 = Image.open('2.jpg')
time1 = time.time()
cosin = image_similarity_vectors_via_numpy(image1, image2)
print('图片余弦相似度', cosin, '时间:', time.time() - time1)
import cv2
import numpy as np
from PIL import Image
import requests
from io import BytesIO
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
def aHash(img):
# 均值哈希算法
# 缩放为8*8
img = cv2.resize(img, (8, 8))
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# s为像素和初值为0,hash_str为hash值初值为''
s = 0
hash_str = ''
# 遍历累加求像素和
for i in range(8):
for j in range(8):
s = s + gray[i, j]
# 求平均灰度
avg = s / 64
# 灰度大于平均值为1相反为0生成图片的hash值
for i in range(8):
for j in range(8):
if gray[i, j] > avg:
hash_str = hash_str + '1'
else:
hash_str = hash_str + '0'
return hash_str
def dHash(img):
# 差值哈希算法
# 缩放8*8
img = cv2.resize(img, (9, 8))
# 转换灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
hash_str = ''
# 每行前一个像素大于后一个像素为1,相反为0,生成哈希
for i in range(8):
for j in range(8):
if gray[i, j] > gray[i, j + 1]:
hash_str = hash_str + '1'
else:
hash_str = hash_str + '0'
return hash_str
def pHash(img):
# 感知哈希算法
# 缩放32*32
img = cv2.resize(img, (32, 32)) # , interpolation=cv2.INTER_CUBIC
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 将灰度图转为浮点型,再进行dct变换
dct = cv2.dct(np.float32(gray))
# opencv实现的掩码操作
dct_roi = dct[0:8, 0:8]
hash = []
avreage = np.mean(dct_roi)
for i in range(dct_roi.shape[0]):
for j in range(dct_roi.shape[1]):
if dct_roi[i, j] > avreage:
hash.append(1)
else:
hash.append(0)
return hash
def calculate(image1, image2):
# 灰度直方图算法
# 计算单通道的直方图的相似值
hist1 = cv2.calcHist([image1], [0], None, [256], [0.0, 255.0])
hist2 = cv2.calcHist([image2], [0], None, [256], [0.0, 255.0])
# 计算直方图的重合度
degree = 0
for i in range(len(hist1)):
if hist1[i] != hist2[i]:
degree = degree + \
(1 - abs(hist1[i] - hist2[i]) / max(hist1[i], hist2[i]))
else:
degree = degree + 1
degree = degree / len(hist1)
return degree
def classify_hist_with_split(image1, image2, size=(256, 256)):
# RGB每个通道的直方图相似度
# 将图像resize后,分离为RGB三个通道,再计算每个通道的相似值
image1 = cv2.resize(image1, size)
image2 = cv2.resize(image2, size)
sub_image1 = cv2.split(image1)
sub_image2 = cv2.split(image2)
sub_data = 0
for im1, im2 in zip(sub_image1, sub_image2):
sub_data += calculate(im1, im2)
sub_data = sub_data / 3
return sub_data
def cmpHash(hash1, hash2):
# Hash值对比
# 算法中1和0顺序组合起来的即是图片的指纹hash。顺序不固定,但是比较的时候必须是相同的顺序。
# 对比两幅图的指纹,计算汉明距离,即两个64位的hash值有多少是不一样的,不同的位数越小,图片越相似
# 汉明距离:一组二进制数据变成另一组数据所需要的步骤,可以衡量两图的差异,汉明距离越小,则相似度越高。汉明距离为0,即两张图片完全一样
n = 0
# hash长度不同则返回-1代表传参出错
if len(hash1) != len(hash2):
return -1
# 遍历判断
for i in range(len(hash1)):
# 不相等则n计数+1,n最终为相似度
if hash1[i] != hash2[i]:
n = n + 1
return n
def getImageByUrl(url):
# 根据图片url 获取图片对象
html = requests.get(url, verify=False)
image = Image.open(BytesIO(html.content))
return image
def PILImageToCV():
# PIL Image转换成OpenCV格式
path = "/Users/waldenz/Documents/Work/doc/TestImages/t3.png"
img = Image.open(path)
plt.subplot(121)
plt.imshow(img)
print(isinstance(img, np.ndarray))
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
print(isinstance(img, np.ndarray))
plt.subplot(122)
plt.imshow(img)
plt.show()
def CVImageToPIL():
# OpenCV图片转换为PIL image
path = "/Users/waldenz/Documents/Work/doc/TestImages/t3.png"
img = cv2.imread(path)
# cv2.imshow("OpenCV",img)
plt.subplot(121)
plt.imshow(img)
img2 = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(122)
plt.imshow(img2)
plt.show()
def bytes_to_cvimage(filebytes):
# 图片字节流转换为cv image
image = Image.open(filebytes)
img = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
return img
def runAllImageSimilaryFun(para1, para2):
# 均值、差值、感知哈希算法三种算法值越小,则越相似,相同图片值为0
# 三直方图算法和单通道的直方图 0-1之间,值越大,越相似。 相同图片为1
# t1,t2 14;19;10; 0.70;0.75
# t1,t3 39 33 18 0.58 0.49
# s1,s2 7 23 11 0.83 0.86 挺相似的图片
# c1,c2 11 29 17 0.30 0.31
if para1.startswith("http"):
# 根据链接下载图片,并转换为opencv格式
img1 = getImageByUrl(para1)
img1 = cv2.cvtColor(np.asarray(img1), cv2.COLOR_RGB2BGR)
img2 = getImageByUrl(para2)
img2 = cv2.cvtColor(np.asarray(img2), cv2.COLOR_RGB2BGR)
else:
# 通过imread方法直接读取物理路径
img1 = cv2.imread(para1)
img2 = cv2.imread(para2)
time1 = time.time()
hash1 = aHash(img1)
hash2 = aHash(img2)
n1 = cmpHash(hash1, hash2)
print('均值哈希算法相似度aHash:', n1, '时间:', time.time() - time1)
time1 = time.time()
hash1 = dHash(img1)
hash2 = dHash(img2)
n2 = cmpHash(hash1, hash2)
print('差值哈希算法相似度dHash:', n2, '时间:', time.time() - time1)
time1 = time.time()
hash1 = pHash(img1)
hash2 = pHash(img2)
n3 = cmpHash(hash1, hash2)
print('感知哈希算法相似度pHash:', n3, '时间:', time.time() - time1)
time1 = time.time()
n4 = classify_hist_with_split(img1, img2)
print('三直方图算法相似度:', n4, '时间:', time.time() - time1)
time1 = time.time()
n5 = calculate(img1, img2)
print("单通道的直方图", n5, '时间:', time.time() - time1)
print("%d %d %d %.2f %.2f " % (n1, n2, n3, round(n4[0], 2), n5[0]))
print("相似概率|均值: %.2f 差值: %.2f 感知: %.2f 三直方图: %.2f 单通道: %.2f " % (1 - float(n1 / 64), 1 -
float(n2 / 64), 1 - float(n3 / 64), round(n4[0], 2), n5[0]))
plt.subplot(121)
plt.imshow(Image.fromarray(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)))
plt.subplot(122)
plt.imshow(Image.fromarray(cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)))
plt.show()
if __name__ == "__main__":
p1 = "1.jpg"
p2 = "2.jpg"
runAllImageSimilaryFun(p1, p2)3.直方图计算图片的相似度
利用直方图计算图片的相似度时,是按照颜色的全局分布情况来看待的,无法对局部的色彩进行分析,同一张图片如果转化成为灰度图时,在计算其直方图时差距就更大了。对于灰度图可以将图片进行等分,然后在计算图片的相似度。
代码在上面也有哦,这里是多了个size(64,64)
# 将图片转化为RGB
def make_regalur_image(img, size=(64, 64)):
gray_image = img.resize(size).convert('RGB')
return gray_image
# 计算直方图
def hist_similar(lh, rh):
assert len(lh) == len(rh)
hist = sum(1 - (0 if l == r else float(abs(l - r)) / max(l, r)) for l, r in zip(lh, rh)) / len(lh)
return hist
# 计算相似度
def calc_similar(li, ri):
calc_sim = hist_similar(li.histogram(), ri.histogram())
return calc_sim
if __name__ == '__main__':
image1 = Image.open('123.jpg')
image1 = make_regalur_image(image1)
image2 = Image.open('456.jpg')
image2 = make_regalur_image(image2)
print("图片间的相似度为", calc_similar(image1, image2))4.SSIM(结构相似度度量)计算图片的相似度 (重点)
这是图像修复很重要的方法,经常用在损失函数中
SSIM是一种全参考的图像质量评价指标,分别从亮度、对比度、结构三个方面度量图像相似性。SSIM取值范围[0, 1],值越大,表示图像失真越小。在实际应用中,可以利用滑动窗将图像分块,令分块总数为N,考虑到窗口形状对分块的影响,采用高斯加权计算每一窗口的均值、方差以及协方差,然后计算对应块的结构相似度SSIM,最后将平均值作为两图像的结构相似性度量,即平均结构相似性SSIM。
import numpy
import numpy as np
import math
import cv2
import torch
import pytorch_ssim
from torch.autograd import Variable
original = cv2.imread("1.jpg") # numpy.adarray
original = cv2.resize(original, (256, 256))
contrast = cv2.imread("2.jpg",1)
contrast = cv2.resize(contrast, (256, 256))
def psnr(img1, img2):
mse = numpy.mean( (img1 - img2) ** 2 )
if mse == 0:
return 100
PIXEL_MAX = 255.0
return 20 * math.log10(PIXEL_MAX / math.sqrt(mse))
def ssim_2(img1, img2):
"""Calculate SSIM (structural similarity) for one channel images.
It is called by func:`calculate_ssim`.
Args:
img1 (ndarray): Images with range [0, 255] with order 'HWC'.
img2 (ndarray): Images with range [0, 255] with order 'HWC'.
Returns:
float: ssim result.
"""
C1 = (0.01 * 255)**2
C2 = (0.03 * 255)**2
img1 = img1.astype(np.float64)
img2 = img2.astype(np.float64)
kernel = cv2.getGaussianKernel(11, 1.5)
window = np.outer(kernel, kernel.transpose())
mu1 = cv2.filter2D(img1, -1, window)[5:-5, 5:-5]
mu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5]
mu1_sq = mu1**2
mu2_sq = mu2**2
mu1_mu2 = mu1 * mu2
sigma1_sq = cv2.filter2D(img1**2, -1, window)[5:-5, 5:-5] - mu1_sq
sigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sq
sigma12 = cv2.filter2D(img1 * img2, -1, window)[5:-5, 5:-5] - mu1_mu2
# 公式二计算
ssim_map = ((2 * mu1_mu2 + C1) *
(2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) *
(sigma1_sq + sigma2_sq + C2))
return ssim_map.mean()
psnrValue = psnr(original,contrast)
ssimValue = ssim_2(original,contrast)
print('PSNR: ', psnrValue)
print('SSIM: ',ssimValue)SSIM当做Pytorch损失函数代码:基于pytorch计算ssim和ms-ssim_是依韵阿的博客-CSDN博客_pytorch计算ssim
psnr 和ssim,大家可以看网上参考哦,这个经常用在损失函数里面,大家可以看看Pytorch版SSIM 和PSNR
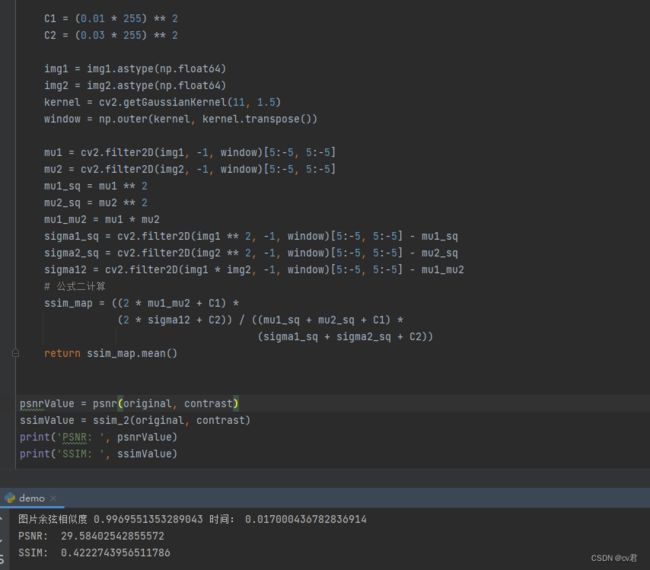
PSNR 是越大越相似,一般到30以上就没有什么很大的意义了,肉眼已经快看不出差别了。这时候就需要其他指标了。
SSIM 是越接近1 越相似。一半是用于去噪等修复任务中,我们这:找不同的任务,偏差较大~后续写写图像修复领域的文章~
互信息
互信息(Mutual Information)是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性
归一化互信息(NMI),就是将互信息放在[0,1]之间
from sklearn import metrics as mr
img1 = cv2.imread('1.jpg')
img2 = cv2.imread('2.jpg')
img2 = cv2.resize(img2, (img1.shape[1], img1.shape[0]))
nmi = mr.normalized_mutual_info_score(img1.reshape(-1), img2.reshape(-1))
print('nmi: ', nmi)nmi接近1为满分。
pixelmatch
利用像素之间的匹配来计算相似度,速度的话,下面例子7ms,还是比较慢的,但是比较准,能够知道两张图片哪些像素不太相似,然后标注出来,结果如图:

上图是两图相同的,显示出来就是浅色,说明完全相同;如果有不同处,会勾勒出来,下图是下面代码的结果,:

#第一步:
# pip install pixelmatch
#第二步:
from PIL import Image
from pixelmatch.contrib.PIL import pixelmatch
img_a = Image.open("1.jpg").resize((64, 64))
img_b = Image.open("2.jpg").resize((64, 64))
img_diff = Image.new("RGBA", img_a.size)
# note how there is no need to specify dimensions
time1 = time.time()
mismatch = pixelmatch(img_a, img_b, img_diff, includeAA=True)
print('pixelmatch Time: ', time.time() - time1)
img_diff.save("diff1.png")md5
粗暴的md5比较 返回是否完全相同,用的哈希方法,只能得到是否完全相同。
def md5_similarity(img1_path, img2_path):
file1 = open(img1_path, "rb")
file2 = open(img2_path, "rb")
md = hashlib.md5()
md.update(file1.read())
res1 = md.hexdigest()
md = hashlib.md5()
md.update(file2.read())
res2 = md.hexdigest()
if __name__ == "__main__":
p1 = "1.jpg"
p2 = "2.jpg"
print('md5_similarity:', md5_similarity(p1, p2))还有一些,比如基于布隆过滤器的图像相似度算法,这本质也是一种基于Hash改版的算法,实现起来还是有点复杂的,因为它本质是实现对数据搜索的过滤。在搜索中加速。
2.深度学习方法
思路:深度特征提取+特征向量相似度计算
cv君简述:就是换到Feature Map层去做相似度计算比对。没什么亮点。
参考:
2.1 论文1
-
名称: Learning to Compare Image Patches via Convolutional Neural Networks
-
论文:https://arxiv.org/pdf/1504.03641.pdf
-
讲解:https://blog.csdn.net/hjimce/article/details/50098483
-
code: https://github.com/szagoruyko/cvpr15deepcompare
2.2 论文2
-
名称: The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
-
论文:https://arxiv.org/pdf/1801.03924.pdf
-
讲解: https://blog.csdn.net/weixin_41605888/article/details/88887416
-
code: https://github.com/richzhang/PerceptualSimilarity
论文提出感知相似度度量方法
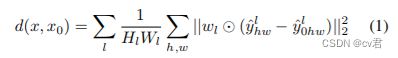
跟踪有十多种,原理和代码,我们下一章说,和这个配套使用,妙哉。
相似度算法总结
-
单通道直方图计算结果与直观视觉不符合,但准确率和速度很不错。推荐
-
余弦相似度准确度较高,但太耗时。不推荐。
-
互信息的方法从耗时和准确度上粗略观察,介于直方图和余弦相似度之间,次推荐。
-
感知哈希算法耗时较为可接受,且比对结果较有区分度且符合直观视觉。推荐。
-
SSIM 和PSNR,深度学习修复任务推荐使用loss ,需要多个loss组合使用
-
互信息的方法从耗时和准确度上粗略观察,介于直方图和余弦相似度之间,次推荐。
跟踪
跟踪算法普遍比较耗时,距今有几十年历史了。有2D,3D跟踪算法;
2D又快准又稳的跟踪方法介绍
2D像Sort ,匈牙利,Deepsort,Iou 追踪,光流估计,STC跟踪器,KF、KCF,CSRT,mosse,medianflow, tld, mil, boosting, 还有今年新出的ByteTrack。
上面的话,Sort就不说了,巨快(256输入估计只需要3-4ms),比较准(给7分),但物体离开视野或者被遮挡就寄了!和sort有同样的问题:STC跟踪器,KF、KCF,CSRT,mosse,medianflow, tld, mil, boosting , (并且这些更慢(当然有个别比较快,但准确率只能6-7分)),这些都是不需要保存、读取模型的,可以随插即用。仅支持单目标追踪;
传统跟踪可以看我这篇文章,附带代码(源码用的跟踪):【效率提高10倍项目原创发布!】深度学习数据自动标注器开源 目标检测和图像分类(高精度高效率)_cv君的博客-CSDN博客
Deepsort深度学习发方法做了特征提取后用改进版sort追踪,速度的话10-20ms,准确率9分,看输入尺寸, 追踪得比较准,抗遮挡,缺点是速度慢,需要保存、读取模型;
Deepsort可以看我文章:【AI全栈二】视频流多目标多类别无延迟高精度高召回目标追踪 YOLO+Deepsort 全解_cv君的博客-CSDN博客
光流估计方法追踪,是我想重点说的,速度比较快,8-13ms 256输入,准确率很高,9分;支持多目标追踪
原本被用在运动点的估计,可以更改代码改成:任何物体追踪,任何形状跟踪:以上所有2D方法都只能追踪矩形,不能接受倾斜四边形(因为有的是旋转目标检测)、不接受:三角形、随机四边形、圆形、点状物体识别与追踪,
而光流追踪统统可以实现(也不需要模型)
cv君已经改成了目标检测版本的跟踪,由于涉密,给出一个网上参考版本给大家学习~
官方思路:
步骤一:基于角点检测算法检测到第一帧的关键点;
步骤二:LK稀疏光流跟踪这些关键点;
于是就实现了点的追踪
矩形目标检测 + 光流追踪思路:
由于矩形目标检测边界框和物体之间有一些空隙,而光流点估计,我们需要得到运动点,因为目标检测直接有空隙,所以若是点落在了空隙处,那么跟踪结果将有偏差:某几个点跟踪的是背景 ,某几个点跟踪了物体,所以下一帧,你的目标框就会有偏差了。
所以使用光流很困难,这就是业界没人使用的原因
我的建议方案:
步骤一:将矩形中心点替换掉上一步骤一;
步骤二:一样走LK算法;
步骤三:根据先前四周点到中心点(由于运动而改变)的距离,算出新的跟踪框位置;
多边形、倾斜目标检测+光流跟踪思路:
这种多边形的检测结果,基本上box边界就落在运动物体上,或者偏外几个像素,我们就可以:
方案:
步骤一,将边界点当做特征点;
后续步骤同上
图像分割+光流追踪:
分割结果就是物体边缘,那么也是直接将边界点当做特征点,后续步骤一样;

# -*- coding:utf-8 -*-
__author__ = 'Microcosm'
import cv2
import numpy as np
cap = cv2.VideoCapture("E:/python/Python Project/opencv_showimage/videos/visionface.avi")
# 设置 ShiTomasi 角点检测的参数
feature_params = dict( maxCorners=100,
qualityLevel=0.3,
minDistance=7,
blockSize=7 )
# 设置 lucas kanade 光流场的参数
# maxLevel 为使用图像金字塔的层数
lk_params = dict( winSize=(15,15),
maxLevel=2,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# 产生随机的颜色值
color = np.random.randint(0,255,(100,3))
# 获取第一帧,并寻找其中的角点
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
# 创建一个掩膜为了后面绘制角点的光流轨迹
mask = np.zeros_like(old_frame)
while(1):
ret, frame = cap.read()
if ret:
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算能够获取到的角点的新位置
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 选取好的角点,并筛选出旧的角点对应的新的角点
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制角点的轨迹
for i,(new,old) in enumerate(zip(good_new,good_old)):
a,b = new.ravel()
c,d = old.ravel()
cv2.line(mask, (a,b), (c,d), color[i].tolist(), 2)
cv2.circle(frame, (a,b), 5, color[i].tolist(), -1)
img = cv2.add(frame, mask)
cv2.imshow("frame", img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
# 更新当前帧和当前角点的位置
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1,1,2)
else:
break
cv2.destroyAllWindows()
cap.release()
3D跟踪算法
3D的话,可以查一下KIITI数据集的排行榜,找一些高排名的:

像速度比较快的就是第二幅图里的AB3DMOT,GPU 5ms,很快了,毕竟是多点追踪,维度比2D多很多;
单目准稠密三维目标跟踪(QD-3DT)是一个在线框架,使用二维图像中的准稠密目标方案检测和跟踪三维目标
根据在移动平台上捕获的二维图像序列估计其完整的三维边界框信息。对象关联利用准密集相似性学习来识别仅具有外观线索的各种姿势和视点中的对象。在初始2D关联之后,我们进一步利用3D边界盒深度排序启发式算法进行鲁棒实例关联,并利用基于运动的3D轨迹预测进行遮挡车辆的重新识别。最后,一个基于LSTM的目标速度学习模块聚合长期轨迹信息,以进行更精确的运动外推。在我们提出的模拟数据和真实基准(包括KITTI、nuScenes和Waymo数据集)上的实验表明,我们的跟踪框架在城市驾驶场景中提供了鲁棒的对象关联和跟踪。在Waymo开放基准上,我们在3D跟踪和3D检测挑战中建立了第一条仅限摄像头的基线。我们的准密集3D跟踪管道在nuScenes 3D跟踪基准上实现了令人印象深刻的改进,在所有已发布的方法中,其跟踪精度是best vision only submission的近五倍。
跳转中...

总结
相似度算法+跟踪算法辅助目标检测、图像分割,规则设计好,既可以无痛提速,又可以提高稳定性(跟踪稳定),何乐而不为呢?cv君提供技术帮助,可以免费随便咨询我,我的联系方式在下面啦~欢迎订阅博主专栏~没钱恰饭啦。哈哈哈