【计算机基础】-2万字总结《计算机速成课》全集笔记
前言
视频链接地址:
【【计算机科学速成课】[40集全/精校] - Crash Course Computer Science-哔哩哔哩】https://b23.tv/a33Kwq
视频的意义
- 能看到各大名鼎鼎的人物悉数登场,也能看到其他幕后的人物的努力。可以看到一个技术的发展需要人类通力合作,用人类的智慧结晶才造就了如今的计算机世界。
- 快速了解计算机的发展历史和相关技术
- 可以看到计算机演进过程中“不断抽象化”的思想和技术应用
1.计算机早期历史
- 发展历史
- 算盘 → 步进计算器→ 差分机 → 分析机 → 打孔卡片制表机。直到 继电器 → 真空管 → 晶体管,才算真正进入现代计算机的时代。
2.电子计算机
继电器
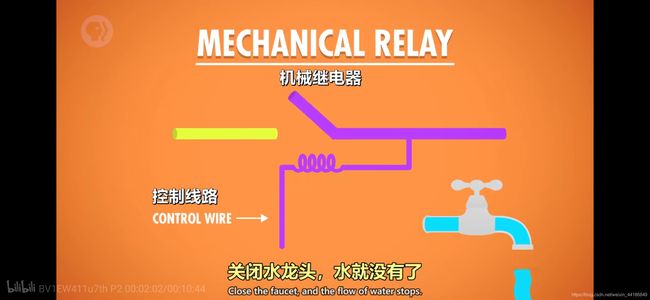
控制线路是一套线圈,线圈通电就会产生磁性,磁性会将电路一端吸过来,这时候电路就通了。然后控制线圈断电,失去磁性,电路一端会自动断开,为啥会断开?因为有弹簧, 控制线圈通电时的磁力大于弹簧阻力就吸过来了,失去磁力,弹簧就会发挥作用弹开。
真空管
正常状态下,灯泡中真空,灯泡正负极断开,是无法通电的, 但给控制线圈通电,线圈发热就会让负极电子处于激发态,从而击穿真空,形成回路。
电子式计算机
ENIAC 电子数值积分计算机
晶体管

- 晶体管(transistor)是一种固体半导体器件(包括二极管、三极管、场效应管、晶闸管等,有时特指双极型器件),具有检波、整流、放大、开关、稳压、信号调制等多种功能。晶体管作为一种可变电流开关,能够基于输入电压控制输出电流。与普通机械开关(如Relay、switch)不同,晶体管利用电信号来控制自身的开合,所以开关速度可以非常快,实验室中的切换速度可达100GHz以上。
- 晶体管的发展历史
- 真空三极管->点接触晶体管->双极型与单极型晶体管->硅晶体管->集成电路->场效应晶体管与MOS管->微处理器(CPU)
3.布尔逻辑和逻辑门
逻辑门
- 布尔变量的值是true和false。布尔代数中几个操作,分别是分别为非门,与门,或门,异或门。
非门
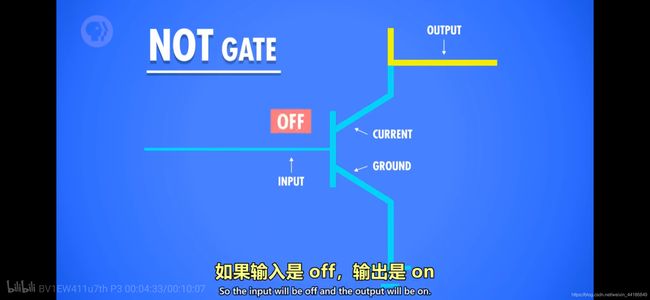
取反操作。正常状态 输出是通的, 当输入侧通电true,将结点联通,电流就接地了。输出就为 false。
与门
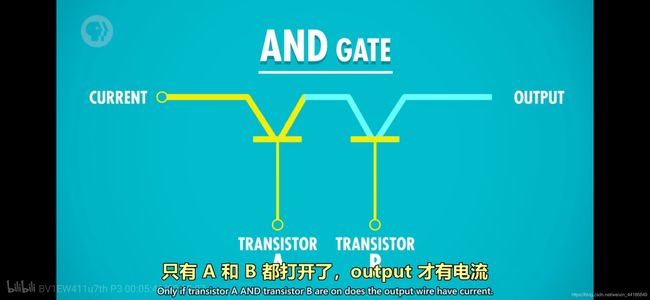
如图 条件A和条件B都要为true,输出才为true
或门
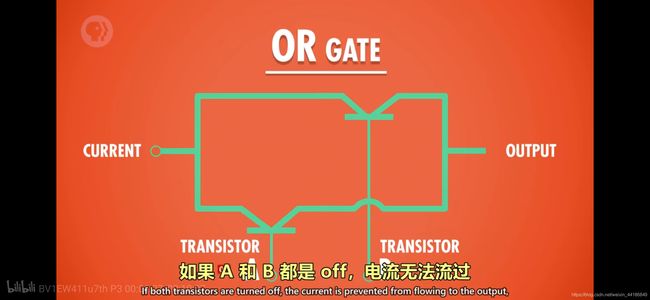
A或者B,有一个条件通了, 输出就为 true
异或门

- 异或门稍微有些复杂, 先用一个或门,异或门的结果和或门的结果很相似,只有 同为真时的结果不一样。给或门并一个与门,与门同为真时才为true,正好借用这一特性,再把这个结果串一个非门,同为真时为true就变成了false,其它情况都是true, 再与 或门的结果同作为一个与门的输入, 输出就是我们想要的结果了,异或门达成。
4.二进制
- 二进制:开始时晶体管用来表示3进制,5进制。但二进制有易于区分,抗噪。
- 在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0)
- 二进制的加减法
- 二进制表示符号:ASCII码,Unicode
- ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符 。
- **ASCII编码:**用来表示英文,它使用1个字节表示,其中第一位规定为0,其他7位存储数据,一共可以表示128个字符。
- **拓展ASCII编码:**用于表示更多的欧洲文字,用8个位存储数据,一共可以表示256个字符
- **GBK/GB2312/GB18030:**表示汉字。GBK/GB2312表示简体中文,GB18030表示繁体中文。
- **Unicode编码:**包含世界上所有的字符,是一个字符集。
- **UTF-8:**是Unicode字符的实现方式之一,它使用1-4个字符表示一个符号,根据不同的符号而变化字节长度。
5.算法逻辑单元
半加器
用于计算两个一位二进制相加,不考虑低位进位。
半加器用于计算2个单比特二进制数a与b的和,输出结果sum(s)和进位carry(c)。在多比特数的计算中,进位c将作为下一相邻比特的加法运算中。单个半加器的计算结果是2c+s。其真值表、逻辑表达式、verilog描述和电路图分别如下所示。
真值表

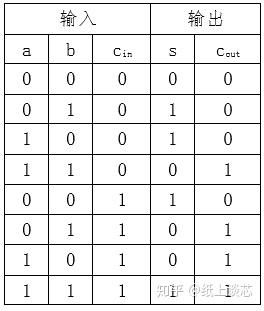
全加器

模拟下 1101+1001的情况, 可以看出会有进位的产生, 进位和选原先的两个数一起相加计算, 这样最多会有三个数相加的情况, 而半加器只有两个数相加,所以我们需要一个能处理三个数相加的全加器。全加器什么特点呢?其实就是模拟上述算式的方式, 三个数ABC先计算两个数AB的结果, 然后把结果的sum位与C相加得到的sum位就是最终的sum位, 那 进位呢? AB相加的进位X , 然后 第一次结果与C相加的进位Y, 这两个进位相或就是最终的进位。为啥?其实 两个进位XY分别是0+0,1+0,0+1的情况都好理解,XY相或的结果就是0,1,1这个是完全符合的,但是1+1的结果不应该是10吗?这样会溢出,不会的,因为进位上不会有1+1的情况,你可以反推,如果A+B的进位X是1,说明A B都要为1, A+B的sum位就为0,0+C,无论C是0还是1都不会出现进位Y为1的情况。其实你也可以列一张表,就是ABC分别为0和1的情况下的sum位和进位的表,只有222=8种情况,你会发现,全加器的结果就是完全符合的。
真值表
浮点数
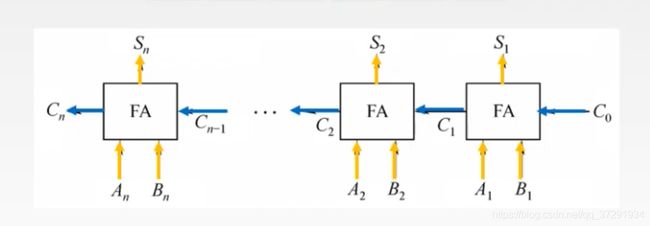
行波进位加法器
构成了一个8bit数相加的加法器,输入 A和B (为8bit位宽),可计算出结果,C0 位相加有进位, 进位和 C1位的两个数A1 和B1相加 就是三个数相加使用全加器,依次排布,构成了一个8bit位宽的加法器,最终结果 可以看到,会有一个最终进位carry, 这个会反应溢出的情况。前面的sum0-7 已经有8bit了。
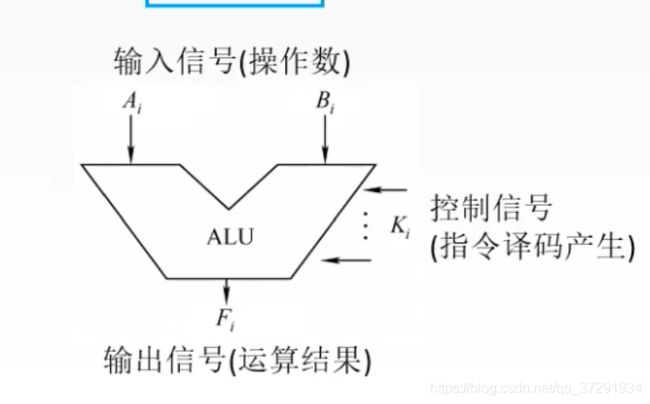
ALU逻辑计算单元
-
计算机中执行各种算术和逻辑运算操作的部件 。 运算器 的基本操作包括加、减、乘、除四则运算,与、或、非、异或等逻辑操作,以及移位、比较和传送等操作,亦称算术逻辑部件(ALU)。计算机运行时,运算器的操作和操作种类由控制器决定。运算器处理的数据来自存储器;处理后的结果数据通常送回存储器,或暂时寄存在运算器中。 A数据运算器的处理对象是数据,所以数据长度和计算机数据表示方法,对运算器的性能影响极大。
-
串行加法器,只有一个全加器,数据逐位串行送入加法器中进行运算。若操作数长n位,则加法就要分n次进行。串行加法器具有器件少,成本低的优点,但运算速度慢,多用于某些低速的专用运算器。
-
并行加法器,由多个全加器组成,其位数与机器的字长相同,各位数据同时运算,虽然操作数的各位是同时提供的,但低位运算所产生的进位将逐位影响至最高位,所以并行加法器的最长运算时间主要是由进位信号的传递时间决定的,而每个全加器本身的求和延迟只是次要因素。
进位表达式为 ,Gi是进位产生的函数,Gi=AiBi;Pi是进位传递函数,
并行加法器的进位通常分为串行进位与并行进位。
把n个全加器串接起来,就可进行两个n位数的相加,这种加法器称为串行进位的并行加法器。
6.寄存器 & 内存
-
逐层的抽象封装 :逻辑门 -> 锁存器 -> 1.寄存器(并列), 2.256位内存(矩阵) -> 小块内存- > 整块内存
-
矩阵压缩了引线的使用量
锁存器
我们如何维持一个bit的信息保持不变, 这幅图的构建就是能保持1即true的信息不变,当起初AB都为0,A输入1,则OUTPUT也为1,立马会回到B,同置为1,再经过OR门,OUTPUT还是为1,这样1就被保存了起来, 这时候无论A输入0还是1,OUTPUT都不会改变了。

我们如何维持一个bit的信息保持不变, 这幅图的构建就是能保持0即tfalse的信息不变,无论A输入0还是1,OUTPUT都不会改变了。
将上面的结构组合一下,设置和复位都为0时,电路最后输入的是啥就为锁住啥,当复位打开为1,设置什么0还是1都不管用,OUTPUT都是0。复位为0时,会锁住1,但是如果为0,SET给1的话,就会OUTPUT为1,这个时候SET就不管用了。要想管用得把复位调到1。
门锁
这个电路你试试就知道,允许写入线的开关,决定数据输入是否有效。只是这个电路是怎么想出来的?咋们的目的事要做一个可以存储数据的电路,输入一个值,能保存下来,先从简单的1bit开始。输入了一个数值,电路能保存这个数值。由上面自连接的或门和与门,可以看出,想要锁定一个值,还是容易的,但是锁住之后就不能修改了,然后你就会想到扩充,输入一根控制先,让它受控制。锁存器就出来了。锁存器的操作不是我们常规容易理解的。然后门锁就出来了。这样一步一步的制造出来的一个电路,当然这里面一定是包含了大量的非常熟悉的对逻辑门的理解,这种电路的设计就是经验和创造力了的体现。
我再来整理一下这个门锁的运行流程。为了书写方便,数据输入端我设为A,允许写入端我设为B,先从图上的内容说起,我们将B端置为1,A端直连的与门结果就为A端输出的结果,再经过或门。我们就输入1好了,好,我们现在来看看下面这个与门,由于经过一个非门,变成0,再过与门,一定为0,再经过非门又变成1,所以最后一个与门的下面的输入为1,上面的输入也为1,最终的输出就为1。现在我们把A端输入变成0,依旧推演一下,上面的与门结果必定为0,下面的与门由A端的0经过非门变成1后结果为1再经过非门变成0,最终的结果就为0。现在把B端的输入变为0即,不允许写入,我们刚刚将0锁存了, 现在把A端变为1试试能不能改变结果,B端为0,会控制上下连个与门的结果都为0,无论你A端输入什么,所以下面的0再经过非门就变成1,再到最后的与门,这个与门输出最终结果为0还是1,就取决于上面一根输入线了,上面的输入线是或门而来,或门的下面一根线我们已经确定一定为0,那或门的结果就取决于已经锁存的数值,锁存的是什么,就依旧是什么,所以实现了不允许写入。
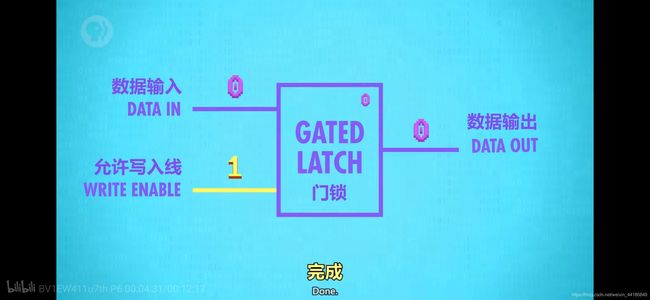
理解了上面的电路的逻辑原理,就能实现,我们想要的结果,不用在关心里面的逻辑。我们把它抽象,一根数据输入线,一根允许写入线,一根数据输出线。只有当允许数据写入线打开时,门锁才受数据输入的影响,否则门锁会保持原先锁住的内容。
寄存器
一个门锁做好了,很显然它的数据量太小了,只有1bit,将其扩充,并排摆放8个,用 1根线控制8个门锁的允许写入线,8根数据线发数据,8根数据线输出数据。当我们打开控制线时,输入可存放到这个寄存器当控制线关闭,输入就不能影响寄存器了,寄存器保留之前的数据。其实这里我们要理一下思绪,就是我们默认的经验是一个数据输入,然后统一存储,比如这个寄存器,不是有8bit的位置,那我输入一个数据10010011,不就能存下这个值吗,确实可以,但是它不方面,实际上,这一排的门锁都只会存一个数据的特定位置的1bit的信息,因为这一系列的内容的索引是不同地址。下面的门锁矩阵个就能比较直观的体现这一点。
多路复用器
-
电子学中,多路复用器(multiplexer或mux)能从多个模拟或数字输入信号中选择某个信号并将其转发,将不同的被选信号输出到同一个输出线路中。
-
复用技术可能遵循以下原则之一,如:TDM、FDM、CDM或WDM。复用技术也应用于软件操作上,如:同时将多线程信息流传送到设备或程序中。
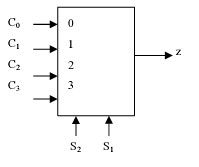
在工业上为了节省成本,我们又要扩大内存,如果还按照上面的并排摆放门锁,那就会产生很多不必要的开销。比如做一个256bit的寄存器,那就要256+256+1=513根线。我们换一种思路,将他们排布成矩阵,16*16,每一个门锁都对应独一的位置,由行号和列号决定。
在工业上为了节省成本,我们又要扩大内存,如果还按照上面的并排摆放门锁,那就会产生很多不必要的开销。比如做一个256bit的寄存器,那就要256+256+1=513根线。我们换一种思路,将他们排布成矩阵,16*16,每一个门锁都对应独一的位置,由行号和列号决定。
将这个1616根线,分别接入多路复用器,一个4bit的位置信息就能确定走哪一根线,比如0010,那就是走2号线,行和列都一样的原理,那么一个8bit的行列信息就能控制1616矩阵的某一块门锁了。这个矩阵中的门锁其实对应的是地址。所以这个矩阵就只需要16+16+1+1=34,节省了不是一点点。
上述门锁放大,可以看出,只有当门锁的行和列都通的时候,这个门锁才可能会生效,比如这时候让可以读取,和行列得到与门再与,那个二极管才会通DATAOUT的线才会有门锁出来的结果,这样才能读取到数据。
RAM
-
随机存取存储器(英语:Random Access Memory,缩写:RAM),也叫主存,是与CPU直接交换数据的内部存储器。
-
它可以随时读写(刷新时除外),而且速度很快,通常作为操作系统或其他正在运行中的程序的临时数据存储介质。
-
RAM工作时可以随时从任何一个指定的地址写入(存入)或读出(取出)信息。它与ROM的最大区别是数据的易失性,即一旦断电所存储的数据将随之丢失。RAM在计算机和数字系统中用来暂时存储程序、数据和中间结果。
256bit的内存,由一个8bit的地址线,其实地址线就看出内存的大小了,28=256,然后一根数据线,一根允许写入线,一根允许读取线。非常简单,不过一个这样的内存也没什么用,它只能在指定的位置存1bit信息。
我们再把内存并列8个,地址线统一管理,比如00100101的地址,8个内存都是去同一个地址门锁,都是第2行第5列的地址。然后我们对8个内存的数据线进行并列管理,确定了位阶,这时候再输入一个数,就能是8bit的数了,比如输入01010001,其实就是分别将0,1,0,1,0,0,0,1分别存入了同一地址下的第1,2,3,4,5,6,7,8块内存当中,当然这要允许写入线打开,然后读取的时候,只要地址是原先的地址,读取的就是原先的数值。
我们进一步将它抽象,这就是我们的RAM,随机存取存储器。由8bit的地址,可存取8bit宽(8位值)的数据,然后一根读取,一根写入线来控制。如果我们想扩大位宽,的话,增加的是并列的内存块。如果我们想增加地址量的话,增加的是门锁矩阵数量。

这是我们常见的内存条RAM,小小的空间能存800万位。
7.中央处理器CPU
分析CPU如何操作指令
如图所示:
RAM中分为ADDRESS和DATA
| ADDRESS | DATA | |
|---|---|---|
| 0 | LOAD_A | 14 |
| 1 | LOAD_B | 15 |
| 2 | ADD | B A |
| 3 | STORE_A | 13 |
CPU取码阶段
CPU解码阶段
现在我们开始模拟跑我们的CPU,准备一个RAM,还记得一个8位宽的RAM 起码会留出一组8根的数据线,一组地址线,然后写入线和读取线。再来ABCD四个寄存器,其实一个8bit的寄存器正好上面有介绍,由8个并排的门锁构成,8根输入线,8根输出线,1根允许写入线控制,当然我们这里的寄存器,还会多一根允许读取线,另外8根输入线也是抽象成1根,这些线怎么连的,我们现在不关心。好,我们现在开始运行,先从指令地址寄存器开始,我们从地址00000000开始,该地址会索引到RAM的Address0号位置(其实它有16*16=256个地址位),先获取到地址0地址的DATA为00101110,至于这一串是什么含义其实是设计CUP的时候规定好的,我们将指令4|4划分,前4位是操作指令,后四位是操作地址。获取到这一串的DATA再去到指令寄存器,再由指令寄存器去做指令判断。
这里我们之间单的列举了最基本的四中指令,0010 加载到A寄存器,0001加载到B寄存器,0100存储A寄存器的值,1000,将寄存器的值相加。
我们来看第一条指令。00101110,前四位0010,表示加载到A寄存器的指令,加载谁呢?加载地址为1110的数据,1110的部分就会与RAM的地址线联通,经过多路复用器打开指定地址的门锁,即14号地址。0010的部分,会经过指令检查逻辑来判断。
当指令是0010时,该逻辑门群才会输出1,当该逻辑们群路径通了的时候就说明指令是0010。
已经经过逻辑门群逻辑判断知道是0010,是 LAOD-A,所以这个逻辑门群的线或打开RAM的允许读取线,这个线是连读取线而不是写入线,是因为我们在设计CPU的时候已经规定了0010是加载,所以0010要连读取线,以及连接寄存器A的允许写入线。读取的是哪个地址的DATA是由后半部分的4位1110的地址来确定的,因为后半部分1110连接的是地址线,多用复路器会只打开RAM地址为14的门锁,然后RAM的数据OUTPUT就是该地址的数据,即RAM的DATA与ABCD的输入线相连,但是只有A的允许写入线是打开的,所以,RAM的14号地址的数据00000011被寄存到了寄存器A。如此,各个操作指令的执行逻辑流程就通顺了。其它的指令也是同样的逻辑,只不过经过的逻辑门群判断后的连线有所区别。
既然如此,我们知道了里面的控制原理,把控制单元包成一个整体好了,又进一步抽象了。
CPU执行阶段
接下来,指令由控制单元进行解码,检查是否load A指令的电路可以打开RAM的允许读取线,把地址14传过去。
-
用检查是否load A指令的电路启用寄存器A的允许写入线。
-
CPU可编程,可被软件控制;
-
底层的命令
- 如ADD、SUB、HALT(停止)、JUMP
- JUMP在底层实现方式是把指令后4位代表的值的内存地址的值,覆盖掉指令地址寄存器里面的值。
8.指令和程序
- 程序 = 指令的集合
- 通过增加寻址到位宽或是可变长的地址来扩展指令集
我们给RAM做好几条简单的指令,从addres0开始,LOADA-14,加载14号地址的数据到寄存器A,就是11;下一步LOADB-15加载15号地址数据到寄存器B;下一条SUDB A,寄存器A减去B值存入寄存器A;接下来做条件跳转,当ALU的FLAGS负号标记符为真,则跳转到5,否则不动,往下执行JUMP2,跳转到2,可以发现又继续相减,接着又判断是否为负,直到为负值,跳转到5,ADDBA,把B的值加到A,存入A,然后STROEA 13,存储A寄存器的值到地址13,最终结束HALT。这一系列指令其实是计算11/5的余数的程序。CPU就这样 运转起来了。
9.高级CPU设计
缓存
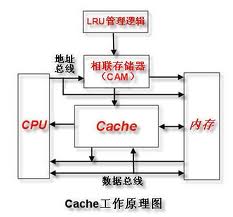
-
缓存是指可以进行高速数据交换的存储器,它先于内存与CPU交换数据,因此速率很快。
-
L1 Cache(一级缓存)是CPU第一层高速缓存。内置的L1高速缓存的容量和结构对CPU的性能影响较大,不过高速缓冲存储器均由静态RAM组成,结构较复杂,在CPU管芯面积不能太大的情况下,L1级高速缓存的容量不可能做得太大。一般L1缓存的容量通常在32—256KB。
-
L2 Cache(二级缓存)是CPU的第二层高速缓存,分内部和外部两种芯片。内部的芯片二级缓存运行速率与主频相同,而外部的二级缓存则只有主频的一半。L2高速缓存容量也会影响CPU的性能,原则是越大越好,普通台式机CPU的L2缓存一般为128KB到2MB或者更高,笔记本、服务器和工作站上用CPU的L2高速缓存最高可达1MB-3MB。由于高速缓存的速度越高价格也越贵,故有的计算机系统中设置了两级或多级高速缓存。紧靠内存的一级高速缓存的速度最高,而容量最小,二级高速缓存的容量稍大,速度也稍低。
-
缓存的工作原理是当CPU要读取一个数据时,首先从CPU缓存中查找,找到就立即读取并送给CPU处理;没有找到,就从速率相对较慢的内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。正是这样的读取机制使CPU读取缓存的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在CPU缓存中,只有大约10%需要从内存读取。这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先缓存后内存。
流水线周期
不采用流水线技术的时,指令的执行方式及其执行周期:

如果按照这种流程,则全部执行完毕了,才能执行下一条,这会产生大量的闲置时间。
使用流水线操作,可大大节省了闲置时间。
- 发展:同时执行多条执行 多个ALU -> 多核 -> 多个cpu -> 超级计算机
10.早期的编程方式
- 最早的编程:纺织机,一张串孔卡片表示不同的图案,可编程纺织机可以根据穿孔卡片来进行纺织。
- 用插线板来存储程序,不同的插线方式表示不同的程序
- 用内存来存储程序,计算机读取打孔卡片上的程序并存进程序。内存比插线板更加易用,体积小,复用性强。
- 用开关来存储程序。不同的开关组合表示不同的指令。
- 早期的编程(1980之前)是一件非常专业的事情,而且很繁琐
11.编程语言发展史
伪代码
指令演进
指令由开始的00101000诸如此类的二进制原始表达方式,改进成了 用简单语言代替指令,要便于记忆和理解很多,在原二进制式的指令中,想要从一个地址跳转到另一个地址,检索地址编码很不方便,用标签的方式就很好地解决的了跳转位置的问题,而且即便是动态的添加了数据指令,原先的地址发生了变化,但我们要鉴别的位置是标签,就不会受到地址变化的影响。
编译器
- 编译器就是将二进制到抽象语言反过来的过程,从高级语言转换成机器码,cpu可直接识别运行。
- 编译器就是将“一种语言(通常为高级语言)”翻译为“另一种语言(通常为低级语言)”的程序。一个现代编译器的主要工作流程:源代码 (source code) → 预处理器 (preprocessor) → 编译器 (compiler) → 目标代码 (object code) → 链接器 (Linker) → 可执行程序 (executables)
- 工作方法
- 首先编译器进行语法分析,也就是要把那些字符串分离出来。
- 然后进行语义分析,就是把各个由语法分析分析出的语法单元的意义搞清楚。
- 最后生成的是目标文件,也称为obj文件。
- 再经过链接器的链接就可以生成最后的EXE文件。
- 有些时候需要把多个文件产生的目标文件进行链接,产生最后的代码。这一过程称为交叉链接。
编程语言
- Unix系统与C语言的结合
- 再次抽象:有了编程语言,我们不用管寄存器或内存位置,简单的申明变量,编译器会帮你把这条语句转化成需要的所有的指令。
12.编程语言-语句和函数
- if语句
- while循环
- 函数
- 函数调用函数
13.算法入门
- 归并排序
- 冒泡排序
- 选择排序
- 插入排序
- 快速排序
14.数据结构
复杂度
时间复杂度
空间复杂度
数组
- 存储在连续空间内,故每个数据的内存地址都可通过下标访问目标数据。
- 添加和删除数据比较耗时间
- 访问数据时间复杂度:O(1)
链表
- 链表分类
- 单向链表
- 双向链表
- 循环链表
- 数据一般分散存储在内存中,因分散存储,故如果想要访问数据,只能从第1个数据开始,顺着指针的指向一一往下访问。
- 添加和删除比较快
- 访问的时间复杂度是O(n)
栈
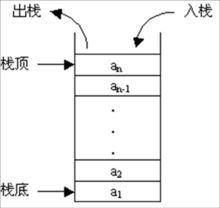
- 线性表
- 先进后出,或者说是后进先出,即FILO
- 限定仅在表尾进行插入和删除操作的线性表
- 栈底固定,而栈顶浮动
- 栈中元素个数为零时称为空栈。插入一般称为进栈(PUSH),删除则称为退栈(POP)。栈也称为先进后出表
- 相关术语
- 栈顶
- 栈低
- 入栈:从栈顶放入元素的操作
- 出栈: 取出元素
堆
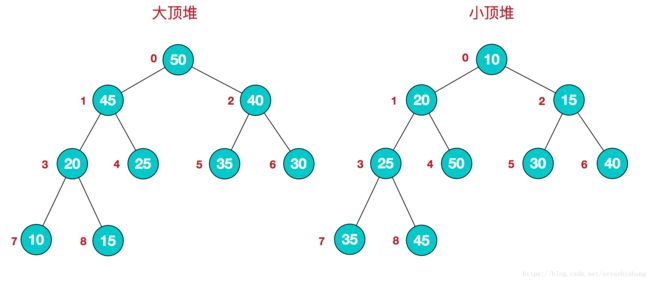
- 堆总是满足下列性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。
- 将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
队列
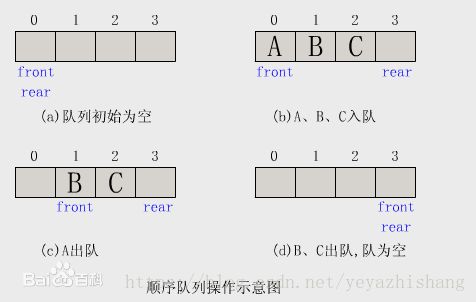
- 线性表
- 先进先出,即FIFO
- 队列可以在一端添加元素,在另一端取出元素
- 相关术语
- 从一端放入元素的操作称为入队,取出元素为出队。
哈希表
- 散列表就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里,这种存储空间可以充分利用数组的查找优势来查找元素,所以查找的速度很快。
- jdk8以后的数组结构:
- 数组+链表的结构
- 需要考虑哈希冲突问题
二叉树
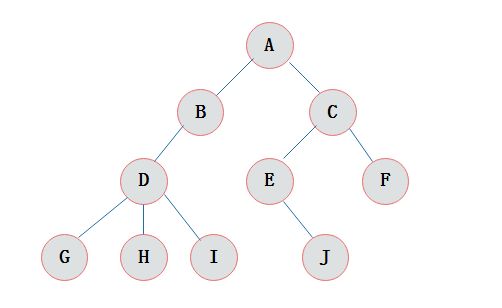
- 常见的二叉树有:完全二叉树、满二叉树、平衡二叉树、红黑树
- B+树:通常用于数据库和操作系统的文件系统中。包含根节点、内部节点和叶子节点。
图
-
图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
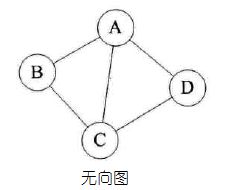
15.阿兰·图灵
图灵机
指一个抽象的机器,它有一条无限长的纸带,纸带分成了一个一个的小方格,每个方格有不同的颜色。有一个机器头在纸带上移来移去。机器头有一组内部状态,还有一些固定的程序。在每个时刻,机器头都要从当前纸带上读入一个方格信息,然后结合自己的内部状态查找程序表,根据程序输出信息到纸带方格上,并转换自己的内部状态,然后进行移动。
停机问题
图灵机,一个计算是否会执行出结果停机,还无法确定,“给定图灵机描述和输入纸带,是否有算法可以确定,机器会永远算下去还是到某一点会停机?图灵机用巧妙的逻辑矛盾,证明了停机问题无法解决。
我们假象一台图灵机,给它输入纸带和规则,输出Yes表示会停机,输出No表示不会停机,这台图灵机起名为H,我们再用H设计一台新机器,如果 H 说程序会"停机”,那么新机器会永远运行(即不会停机),如果 H 的结果为 No,代表不会停机,实质上是一台和 H 输出相反的机器,我们还需要在机器前面加一个分离器,让机器只接收一个输入。如果把 新机器 的描述,作为本身的输入会怎样,如果说H输出Yes表示会停机,则新机器会无限循环,不停机,如果说H输出No表示不会停机,则新机器就会停机。这自相矛盾的结果,所以证明停机问题无法解决。
图灵身上的标签
- 计算机科学之父
- 提出“图灵测试”概念
- 人工智能思想
科学巨星的陨落
16.软件工程
- 对象化
17.集成电路&摩尔定律
光刻
计算机硬件的提升经历了几个阶段,从真空管到晶体管到集成电路,光刻机就是在此环境下诞生。
其实整个光刻的过程就是不断地贴层,溶蚀,清洗,贴层,溶蚀,清洗,最终制作出集成晶体管。它有时导电,有时不导电 \N 我们可以控制导电时机。
这个过程怎么发生的呢?从最下层开始,晶圆(硅材料),氧化层,光刻胶,光掩模, 光掩模的镂空是设计电路,露出的部分,经过光照,能直接照射到光刻胶,光刻胶溶解,置入特定的洗液,这部分溶解的光刻胶就去掉了。然后再用能溶解氧化层的物质溶解一次,露出的氧化层也被干掉,注意这些溶液只会对特定的层起作用,不会腐蚀其它层的材料。同样的过程,溶蚀晶圆,给溶蚀掉的部分掺杂,比如磷渗透进暴露出的硅,改变电学性质,让这部分具有半导性。
将层融掉后再重复上面的过程,用新的光掩模,这次图案不同在掺杂区域上方开一个缺口。然后用另一种气体掺杂 把一部分硅转成另一种形式。
将特定的区域溶解露出准备好的区域。
盖上一层金属层,一个晶体管的三个区域就成型,不导电,半导电,导电。每个区域的掺杂方式不同,这叫双极型晶体管。
我们可以把光掩膜聚焦到极小的区域,制作出非常精细的细节。
18.操作系统
-
operating system,简称OS。
-
它也是个软件程序,有操作硬件的特殊权限,可以运行和管理其他程序。
-
操作系统一般是开机第一个启动的程序,其他所有程序由操作系统来启动。
-
操作系统提供API来抽象硬件,叫设备驱动程序,程序员可用标准化机制,和输入输出硬件I/O交互。如程序员调用print,操作系统就会处理输到纸上的具体细节。
-
第一个超级计算机,Altas,开发人员机器处理数据很快,想最大限度利用它。所以用的操作系统可批处理,能自动加载程序,还能在单个CPU上同时运行几个程序。
-
虚拟内存
- CPU可多任务处理,每个程序都会占用内存,切到另一个不能丢数据,那么,如何处理?
- 给每个程序分配专属内存块。
- 真正的内存可能会分配到内存数十个地方,列表可能存在一堆不连续的内存块里。
- 为隐藏这种复杂性,操作系统会把内存地址进行虚拟化。可假定内存总是从地址0开始。但实际,被操作系统隐藏和抽象。
- 操作系统会自动处理虚拟内存和物理内存之间的映射。
- 虚拟内存的这种机制,使得程序的内存大小可以灵活增减,即动态内存分配。
- 给程序分配专用的内存范围,同时运行多个程序,更灵活,隔离起来会更好。如果一个程序出错,只会捣乱自己的内存,不会影响到其他的程序,这就叫内存保护。其中隔离病毒也可以。
- 补充知识
- 虚拟内存别称虚拟存储器(Virtual Memory)。电脑中所运行的程序均需经由内存执行,若执行的程序占用内存很大或很多,则会导致内存消耗殆尽。为解决该问题,Windows中运用了虚拟内存技术,即匀出一部分硬盘空间来充当内存使用。
- 当内存耗尽时,电脑就会自动调用硬盘来充当内存,以缓解内存的紧张。若计算机运行程序或操作所需的随机存储器(RAM)不足时,则 Windows 会用虚拟存储器进行补偿。它将计算机的RAM和硬盘上的临时空间组合。当RAM运行速率缓慢时,它便将数据从RAM移动到称为“分页文件”的空间中。将数据移入分页文件可释放RAM,以便完成工作。 一般而言,计算机的RAM容量越大,程序运行得越快。若计算机的速率由于RAM可用空间匮乏而减缓,则可尝试通过增加虚拟内存来进行补偿。但是,计算机从RAM读取数据的速率要比从硬盘读取数据的速率快,因而扩增RAM容量(可加内存条)是最佳选择。 [2]
-
发展:多任务,多用户
-
分时操作系统
- 分时操作系统是使一台计算机采用时间片轮转的方式同时为几个、几十个甚至几百个用户服务的一种操作系统。
- 把计算机与许多终端用户连接起来,分时操作系统将系统处理机时间与内存空间按一定的时间间隔,轮流地切换给各终端用户的程序使用。由于时间间隔很短,每个用户的感觉就像他独占计算机一样。分时操作系统的特点是可有效增加资源的使用率。例如UNIX系统就采用剥夺式动态优先的CPU调度,有力地支持分时操作。
- 时间片:是把计算机的系统资源(尤其是 CPU时间)进行时间上的分割,每个时间段称为一个时间片,每个用户依次轮流使用时间片。
- 分时技术:把处理机的运行时间分为很短的时间片,按时间片轮流把处理机分给各联机作业使用。
- 分时操作系统典型的例子就是Unix和Linux的操作系统。其可以同时连接多个终端并且每隔一段时间重新扫描进程,重新分配进程的优先级,动态分配系统资源。
-
Unix系统
-
核心功能:如内存管理,多任务和输入/输出处理,叫内核。
-
一堆有用的工具:但它不是内核的一部分(如程序和运行库)
-
1969年,Bell实验室的Ken Thompson用汇编语言写出了一组内核程序,一些内核工具程序以及一个小的文件系统。这个系统是UNIX的原型,被称为Unics(当时尚未有UNIX)。这个文件系统有两个重要概念:
所有程序或系统装置都是文件
不管构建编辑器还是附属文件,所写的程序只有一个目的:有效完成目标
-
19.内存&储存介质
存储介质
存储介质用于记录信息。以下内容包含拓展内容:
打孔卡和打孔纸带


1725年法国人Basile Bouchon发明了打孔卡(穿孔卡),他用在纸上打孔的形式来存储图案,用于控制纺织机进行图案织造。
1801年Joseph Marie Jacquard将打孔卡顺序捆绑在一起应用于提花织机,这是打孔纸带(Punched Tape)的雏形。
1846年Alexander Bain使用打孔纸带发送电报。
1890年,Herman Hollerith发明了打孔卡制表机,用于收集并统计人口普查数据,标志着半自动化数据处理系统时代的开始。这种机器不仅统计速度更快,而且能够以新的方式理解信息,很快便应用到了各个行业。
1896年,Herman Hollerith成立了制表机公司,这家公司就是后来大名鼎鼎的IBM的前身。打孔卡和纸带直到80年代还在使用,持续了两个多世纪。
延迟线存储器 顺序存取

拿一个管子装满液体,如水银,管子一端放扬声器,另一端放麦克风,扬声器发出脉冲时会产生压力波,压力波需要时间传播到另一端的麦克风,麦克风将压力波转换回电信号。
这个延迟线****存储器的原理,就是通过用压力波的传播延迟来存储数据。
有压力波代表 1,没有代表 0。通过内部电路连接麦克风和扬声器,再通过放大器来弥补信号衰弱,从而实现一个存储数据的循环。
有压力波代表 1,没有代表 0。通过内部电路连接麦克风和扬声器,再通过放大器来弥补信号衰弱,从而实现一个存储数据的循环。
磁芯存储器

录音磁带,可以存储模拟信号。
原理就是:磁力线是随音频电流的变化而变化的,所以每段磁带在移动过程中被磁化的程度也随音频信号电流的强弱而变化,这样就能把声音记录的磁带上。磁带用于计算机中则是从1951年开始。
给磁芯绕上电线,并施加电流,可以将磁化在一个方向,如果关掉电流,磁芯保持磁化;如果沿相反方向施加电流,磁化的方向(极性)会翻转,这样就可以用来区别存储 1 和 0。
通过把磁芯排列成网格,由电线来负责遴选行和列,也由电线贯穿每个磁芯, 用于读写一位(bit)。

磁带
磁带是纤薄柔软的一长条磁性带子卷在轴上,磁带可以在「磁带驱动器」内前后移动,里面有一个"写头"绕了电线,电流通过产生磁场,导致磁带的一小部分被磁化,电流方向决定了极性,代表 1 和 0。

由于磁带是循序存取的装置,尤为适合传统的存储和备份以及顺序读写大量资料的使用场景。但因为速度较慢,且体积较大等缺点,现在主要仅用作商业备份等用途。
比较便宜,但磁盘是连续的,必须倒带或者快进到达特定位置。
磁鼓内存(Drum memory),硬盘驱动器(HDD)的前身
它包含一个大型金属圆柱体,外表面涂有铁磁记录材料。在磁芯存储器出现之前广泛用于计算机内存。同时也用于做二级存储,被认为是硬盘驱动器(HDD)的前身。与硬盘驱动器一样,磁鼓也有磁头,但不是寻找数据,磁鼓上有许多静态磁头,只需等待正确的磁扇旋转就位即可。Tauschek的原始磁鼓存储器的容量约为500,000比特(62.5千字节)。
磁盘
工作时磁头悬浮在高速转动的盘片上方,而不与盘片直接接触,这便是现代硬盘的原型。
硬盘的好处是薄,可以叠在一起,提供更多表面积来存数据。
只读式光盘存储器(CD-ROM)
(动态随机存取存储器)DRAM
至今,DRAM仍是最常用的随机存取器(RAM),作为个人电脑和工作站中内存(即主存储器)。DRAM内存能够问世,主要是基于半导体晶体管和集成电路技术。
软盘(Floppy Disk)
从 1971年直到 20世纪 90年代的近三十年内,软盘一直被用于存储和交换数据。
闪存(Flash)
数字音频磁带 DAT(Digital Audio Tape)
数字多用途光盘 DVD(Floppy Disk)
USB闪存驱动器(俗称U盘)
SD卡 (Secure Digital Memory Card)安全数码卡
专业术语
寻道时间
平均寻道时间是指MO磁光盘机在接收到系统指令后,磁头从开始移动到移动到数据所在磁道所需要的平均时间,它是指计算机在发出一个寻址命令,到相应目标数据被找到所需时间,单位为毫秒(ms)。
指磁头移动到数据所在磁道需要的时间。在不同的磁头调度算法中,有不同的寻道时间
20.文件与文件系统
-
文件在底层是一长串二进制。
-
储存是没有文件的概念,只是存储大量位。所以为存多文件,需一个特殊文件,记录其他文件的位置,这个特殊文件有很多名字,这里泛称目录文件。
-
该文件常存在最开头,方便查找。
-
目录文件,存所有其他文件的名字、创建时间、类型、修改时间、大小等。
-
为防止几个文件覆盖后面的,故:
- 把空间划分成一块块:这样有一些预留空间,目录文件要记录文件在哪个块里(Blocks)。
- 拆分文件:存在多个块里,如果文件太大,会找一个不用的块来用。所以目录文件记录的不是只一个块。
只要分配块,文件可轻松增大、缩小。
-
虚拟内存是它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。目前,大多数操作系统都使用了虚拟内存,如Windows家族的“虚拟内存”;Linux的“交换空间”等。
-
如果想删掉某条文件,只需删除目录文件的那条记录,让一块空间变成可用的。之后在某个时候,那些块会被新数据覆盖,但在此之前数据还在原处。所以计算机可恢复数据。
-
碎片:
- 举例a.txt,增加文本的数据,操作系统为其分配了一个新块,那数据会在3个块里,隔开了,顺序也是乱的。这就叫碎片。
- 碎片是增/删文件导致的,不可避免。
- 在磁盘,碎片是坏事,如先读块1,然后快进到块5,然后回转到块3。
- 大文件可能会在多个块里,打开速度慢?可碎片整理。即把数据来回移动,排列成正确的顺序。
-
分层文件系统
- 目前文件是由一个个文件夹和文件组成的。
- 目录文件不仅指向文件,还要指向目录。那么,就需要额外元数据来区分文件和目录。
- 目录文件在最顶层,根目录,所有文件和文件夹都在根目录下。
- 如移动文件,不用移动任何数据块,只需改两个目录文件,一个是删原目录文件的记录,一个是加新目录文件的记录。
- 补充:元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。元数据算是一种电子式目录,为了达到编制目录的目的,必须在描述并收藏数据的内容或特色,进而达成协助数据检索的目的
21.压缩
-
同数据内容压缩
- 一份文件中,会有些数据是重复出现的,比如连续出现7个黄色,我们不用写7次(255,255,0)黄色,我们只需要写一遍黄色,然后在前面写上重复的次数7,就能准确的表示这段数据,数据大小也被压缩了。当然我们有些情况是没有重复的,为了避免计算机检索时不能区分哪些是重复的哪些是不重复的,我们在所有的色块前面都加上重复次数,不重复就是。
-
字典压缩
- 我们将色块两两划分,分为不同的色块类型,然后汇总不同色块的个数,记录他们的频次,比如WY黄白2次,YY黄黄4次······
- 将所有的不同色块组合都列出来,分别是YY4,WY2,BY1,WW1,我们在这些组合中挑选频次最少的两种,将他们合为一个根下的分支,然后这个合并后的节点与剩下的组合,再取两个频次最小的合为一个节点下的分支,如此往复,直至完全合并。就如图中左侧那样,我们给所有分支左侧的数值为0,右侧为1,所以会有YY的代码code为0,WY代码为10,BY代码为110,WW代码为11。请注意这些所有的色块组合的代码都是不重复,而且没有相同的前缀。
- 这时候再把色块用代码表示即10110000111100,总共才14bit,可惜的是这还不算完,我们需要加上字典色块代码的信息,不然这一列数据就是没有意义的一段数据。
- 加上字典信息后,总共是30个字节,比48字节好了很多,如果数据量再增加的话,后面的压缩效率会将字典的边界成本摊薄。
22.命令行界面
- 发展初期:计算机,用齿轮,旋钮,插线板,开关控制的方式会更加难以接受和操作。
- 如输入 pwd:打印工作目录,hostname:计算机在网络中的名称,ls:列出目录中的内容
23.屏幕&2D图形显示
-
阴极射线管:CRT 矢量模式
- 原理:将电子发射到有磷光体涂层的屏幕上,当电子撞击涂层时会发光几分之一秒,由于电子是带电粒子,路径可以用磁场控制。屏幕内用板子或线圈把电子引导到想要的位置,上下左右都可。
- 这样控制,有两种方法绘制图形:
- 引导电子束描绘出形状,这叫矢量扫描。因为发光只持续一会儿,如果重复得足够快,可以得到清晰的图像。
- 按固定路径,一行行来。从上到下,从左到右,不断重复。只在特定的点打开电子束,以此绘制图形。这叫光栅扫描。用这种方法,可以用很多小线段绘制图形甚至文字。
-
液晶显示器 LCD
- 随着技术的发展,终于可以在屏幕上显示清晰的点,叫像素。液晶显示器,简称LCD。
- LCD也用光栅扫描,每秒更新多次像素里红绿蓝的颜色。
- 计算机刚开始发展时不存像素值这一说,并不是因为无法实现,而是存符号,因为占用的内存太大。
-
字符生成器:
- 为了省用内存,但没办法绘制任何形状。
- 从内存读取字符,转换成光栅图像,这样才能显示在屏幕上。
-
画板
24.冷战和消费主义
- 美国和前苏联军事和科技竞赛,导致美国往计算机领域投入大量资源,使得催生了很多技术。
- 政府出资金,比如冷战期间美国投入的钱推动了计算机的早期发展。
- 消费者推动计算机商业发展
25.个人计算机革命
- 催生出个微型计算机
- 单芯片CPU:强大+体积小+便宜
- 集成电路的进步,也提供了低成本固态存储器,可以用于ROM和RAM,可把整个计算机做到一个电路板上
- 便宜可靠的存储介质,如磁带和软盘
- 低成本的显示器
26.图形用户界面
- 鼠标
- GUI程序:事件驱动编程
- 用户界面:代码与事件相连,每次点按钮时,都触发代码。
27.3D图形
28.计算机网络
发展历史
在公司内部方便信息交换,比起把纸卡或磁带送到另一栋里更快可靠,这是球鞋网络。能共享资源,他们这部分网络之间是内部链接,构成早期的局域网。
在局域网的计算机是怎么沟通的呢,他们通过光纤,传递2进制信号,头部信息会包含要去往的MAC地址,每一台计算机的MAC地址都是唯一的,所以在同一网络下的计算机接收到信号的时候,解析头部信息,看看这个接收方的MAC地址,是否是自己就能鉴别是否要接受该条信息。这很方便,但随着同一网络下的计算机越来越多,要发送信息的计算机和接受信息的计算机也越来越多,同一时间段很可能会有同时发送信号的情况,于是有了下面的网关。
将一片计算机之间交互频次多的划分到一个区域,每一片区域之间用交换器连接,当在自己区域的信息传播就不需要打开switch,这时即便是另一片区域的计算机也在发送同区域的信息,也不会受到影响,除非他们要跨区域沟通。
当然这不能解决所有问题,在网络通讯中还有非常重要的指数退避机制,就是说当几台计算机想要发送信号时,检查网路中是否已经有信号在占用,如果有的话,就等待一段时间再发送,比如等1秒,再发,这时候再次检测是否网络被占用,如果是那就再等一段时间,2秒钟,2秒之后再检测网络是否占用,如果占用就等4秒,如此指数级的等待时间发送,能极大程度避免网络冲突。这里面起始的1秒钟并不是固定的,它是随机数值,如如果大家的起始时间都是1秒,那依旧会冲突。
路由器
现实中的网络连接不是点对点的,这样的连通成本会灰常高,而是采用节点连接的形式,从一个城市去往另一个城市,可能要经过好几段网络路径和节点。当然发送的时候信息里面是包含要去往的目标的信息的,然后到达一个节点(路由器)会根据目标分配路径较短,较不拥挤的路径到达。
一条信息的内容特别大的时候,不便于一次性发送数据,会把数据拆分成若干分包,这些分包打上标签,去往同一目的地,在目的地网络协议会把这些分包组装起来,再解析。
早期的网络系统,其实网络并不神秘,他们就是连接计算机的管道,这些管道可能会断掉,那和管道那一头的计算机就断联了,但是管道这头的计算机还是能相互沟通的。
29.互联网
网络连接
LAN:Local Area Network,局域网
计算机先连接到局域网。
WIFI路由器会连着所有的设备,组成局域网。
WAN:Wide Area Network,广域网
局域网再连接到广域网。WAN的路由器一半属于互联网服务提供商,简称ISP。
如Comcast,AT&T和Verzion。
广域网里,先连接到一个区域性路由器,这路由器可能覆盖一个街区,
然后连接到一个更大的WAN,可能覆盖整个城市。
可能再跳几次,但最终会到达互联网主干。
互联网主干由一群超大型、带宽超高路由器组成。
传输数据
如获取YouTube这个视频,数据包要先到互联网主干,沿着主干到达有对应视频文件的YouTube服务器。
数据包从你的计算机跳到YouTube服务器,可能要跳个10次。
举例,从本机电脑跳转到百度,用traceroute命令
traceroute www.baidu.com
traceroute: Warning: www.baidu.com has multiple addresses; using 14.215.177.38
traceroute to www.a.shifen.com (14.215.177.38), 64 hops max, 52 byte packets
1 171.11.56.1 (171.11.56.1) 2.996 ms 2.658 ms 2.933 ms
2 * * *
3 211.95.4.153 (211.95.4.153) 38.653 ms 3.760 ms 3.479 ms
4 139.226.210.109 (139.226.210.109) 4.518 ms 4.461 ms
139.226.213.233 (139.226.213.233) 29.087 ms
5 139.226.225.137 (139.226.225.137) 5.915 ms
139.226.210.61 (139.226.210.61) 8.987 ms
139.226.225.137 (139.226.225.137) 4.781 ms
6 219.158.6.214 (219.158.6.214) 30.717 ms 33.009 ms 31.772 ms
7 * 219.158.24.18 (219.158.24.18) 42.654 ms 40.014 ms
8 * * *
9 202.97.95.101 (202.97.95.101) 59.009 ms * *
10 113.96.5.134 (113.96.5.134) 32.778 ms * *
11 86.96.135.219.broad.fs.gd.dynamic.163data.com.cn (219.135.96.86) 62.037 ms
113.96.4.205 (113.96.4.205) 33.260 ms
86.96.135.219.broad.fs.gd.dynamic.163data.com.cn (219.135.96.86) 33.472 ms
12 14.29.121.186 (14.29.121.186) 34.641 ms
86.96.135.219.broad.fs.gd.dynamic.163data.com.cn (219.135.96.86) 33.889 ms
14.29.121.178 (14.29.121.178) 35.248 ms
13 14.215.32.110 (14.215.32.110) 34.939 ms * *
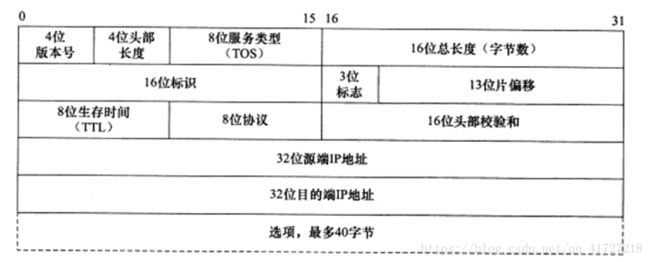
IP协议-互联网协议
如果数据很大,数据会被拆成多个小数据包,而不是整个文件发过来。
数据包要在互联网上传输,要符合互联网协议的标准,简称IP。
IP属于底层协议,数据包的头部只有目标地址,头部存关于数据的数据,也叫元数据。
在此层并不知道要交给哪个程序。
UDP协议-用户数据报协议
UDP头部位于数据前面,头部包含有用的信息。如端口号,每个想访问网络的程序都要向操作系统申请一个端口号。
当一个数据包到达时,接收方的操作系统会读UDP头部,读里面的端口号,然后转到对应的程序中。
IP负责把数据包送到正确的计算机,UDP负责把数据包送到正确的程序。
UDP不提供数据修复或数据重发的机制。
接收方知道数据损坏后,一般只是扔掉。而且UDP无法得知数据包是否到达。
使用场景如视频通话。不适用:文本传输。
校验和-Checksum
头部里面还有校验和,用于检查数据是否正确,检查方式是把数据求和来对比,将收到的数据加在一起,与头部校验和比对,一致的话说明正常,不一致那数据有问题。UDP不提供数据修复重复机制。
TCP协议-传输控制协议
三次握手:
我要给你发数据了你准备好(1),好呢,我准备好了(2),行,我知道你准备好了(3)。······开始发数据。
四次挥手:
客户端发送一个FIN段,并包含一个希望接收者看到的自己当前的序列号K. 同时还包含一个ACK表示确认对方最近一次发过来的数据。(1) , 服务端将K值加1作为ACK序号值,表明收到了上一个包。这时上层的应用程序会被告知另一端发起了关闭操作,通常这将引起应用程序发起自己的关闭操作。(2),服务端发起自己的FIN段,ACK=K+1, Seq=L (3),客户端确认。ACK=L+1(4)。
DNS-域名系统
由于IP地址具有不方便记忆并且不能显示地址组织的名称和性质等缺点,人们设计出了域名,我们只需要记住要访问的网页的域名即可,网络会把我们访问的域名通过DNS查表,得到 域名对应的IP地址,然后访问真实的IP。
OSI-开发式系统互联通信参考模型
物理层(光纤电脑),数据链路层(二进制电信号光信号),网络层(IP协议),传输层(UDP,TCP),会话层。
30.万维网
早期探索
早期搜索引擎怎么去展示你想要的网页呢,通过存储在字典里面的关键字,比如我搜索猫,那存储在猫这个字典里面的网址就会被返回,那谁在前谁在后,看这个网站里面猫这个词出现的次数,很明显这里有很大的缺陷,有许多垃圾网址,将猫这个词无限拷贝,充满了网页内容,那它被,猫这个字典关联的名次就会极大靠前,但其实它根本没什么价值。只是一串无阅读意义的猫合集。谷歌之所以能够搜索引擎成功就避免了这种方式,采用关联性存储,指向性存储等等方式。
HTML
超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。可以使用 HTML 来建立自己的 WEB 站点,HTML 运行在浏览器上,由浏览器来解析。
万维网的由来
万维网和互联网是两回事,互联网是传递数据的管道,各种程序都会用,其中传输最多数据的程序是万维网。万维网的最基本单位是单个页面,页面内容有去往其它页面的链接,叫超链接,这些超链接就形成巨大的互联网络。
31.计算机安全
身份校验
身份,能访问什么
权限校验
不能向上读表示,你在低权限位置不能读取高权限的内容,这样能防止非核心人员窃取到机密,不能向下写表示,你在高权限位置不能在低权限的区间写内容,这样能防止核心人员的核心内容被泄露到低权限区域。
32.黑客&攻击
攻击
在一个页面输入用户名和密码,服务器会将该内容拿去数据库比对,如果被黑客攻击,会将用户名栏输入“用户名”DROP TABLE users; 如果服务器没有做保护,会在执行完用户名校验后清空数据表。
sql注入问题。
缓冲区溢出,在登录界面要输入用户名和密码,在幕后,系统用缓冲区存输入的值,假设缓冲区大小是10,前后有其它数据,如果超过10个限制,数据会覆盖数据。可能导致系统崩溃。还可以在is_admin的值改成true,这样就能绕过登录,劫持整个系统。可以在缓冲区后,留一些不用的空间,跟踪里面的值,看书否变化。
33.加密
数字签名
- 数字签名,简单来说就是通过提供 可鉴别 的 数字信息 验证 自身身份 的一种方式。
- 一套 数字签名 通常定义两种 互补 的运算,一个用于 签名,另一个用于 验证。分别由 发送者 持有能够 代表自己身份 的 私钥 (私钥不可泄露),由 接受者 持有与私钥对应的 公钥 ,能够在 接受 到来自发送者信息时用于 验证 其身份。
加密与解密术语
- 加密:数据加密 的基本过程,就是对原来为 明文 的文件或数据按 某种算法 进行处理,使其成为 不可读 的一段代码,通常称为 “密文”。通过这样的途径,来达到 保护数据 不被 非法人窃取、阅读的目的。
- 解密:加密 的 逆过程 为 解密,即将该 编码信息 转化为其 原来数据 的过程。
- 对称加密和非对称加密
- 其中对称加密算法的加密与解密 密钥相同,非对称加密算法的加密密钥与解密 密钥不同,此外,还有一类 不需要密钥 的 散列算法。
- 常见的 对称加密 算法主要有
DES、3DES、AES等, - 常见的 非对称算法 主要有
RSA、DSA等, - 散列算法 主要有
SHA-1、MD5等。 - 对称加密算法 是应用较早的加密算法,又称为 共享密钥加密算法。在 对称加密算法 中,使用的密钥只有一个,发送 和 接收 双方都使用这个密钥对数据进行 加密 和 解密。这就要求加密和解密方事先都必须知道加密的密钥。
- 非对称加密算法,又称为 公开密钥加密算法。它需要两个密钥,一个称为 公开密钥 (
public key),即 公钥,另一个称为 私有密钥 (private key),即 私钥。因为 加密 和 解密 使用的是两个不同的密钥,所以这种算法称为 非对称加密算法。
DES
- DES全称为Data Encryption Standard
- DES算法把64位的明文输入块变为64位的密文输出块,它所使用的密钥也是64位(实际用到了56位,第8、16、24、32、40、48、56、64位是校验位, 使得每个密钥都有奇数个1)
- 是基于
DES的 对称算法,对 一块数据 用 三个不同的密钥 进行 三次加密,强度更高。
AES
- 高级加密标准(Advanced Encryption Standard,AES)
- AES 加密算法是密码学中的 高级加密标准,该加密算法采用 对称分组密码体制,密钥长度的最少支持为 128 位、 192 位、256 位,分组长度 128 位,算法应易于各种硬件和软件实现。这种加密算法是美国联邦政府采用的 区块加密标准。
- AES 本身就是为了取代 DES 的,AES 具有更好的 安全性、效率 和 灵活性。
RSA算法
-
RSA 加密算法是目前最有影响力的 公钥加密算法,并且被普遍认为是目前 最优秀的公钥方案 之一。RSA 是第一个能同时用于 加密 和 数字签名 的算法,它能够 抵抗 到目前为止已知的 所有密码攻击,已被 ISO 推荐为公钥数据加密标准。
-
RSA 加密算法 基于一个十分简单的数论事实:将两个大 素数 相乘十分容易,但想要对其乘积进行 因式分解 却极其困难,因此可以将 乘积 公开作为 加密密钥。
MD5
MD5用的是 哈希函数,它的典型应用是对一段信息产生 信息摘要,以 防止被篡改。严格来说,MD5不是一种 加密算法 而是 摘要算法。无论是多长的输入,MD5都会输出长度为128bits的一个串 (通常用16进制 表示为32个字符)。
SHA1算法
- SHA1 是和 MD5 一样流行的 消息摘要算法,然而 SHA1 比 MD5 的 安全性更强。对于长度小于 2 ^ 64 位的消息,SHA1 会产生一个 160 位的 消息摘要。基于 MD5、SHA1 的信息摘要特性以及 不可逆 (一般而言),可以被应用在检查 文件完整性 以及 数字签名 等场景。
对称加密算法比较
| 名称 | 密钥名称 | 运行速度 | 安全性 | 资源消耗 |
|---|---|---|---|---|
| DES | 56位 | 较快 | 低 | 中 |
| 3DES | 112位或168位 | 慢 | 中 | 高 |
| AES | 128、192、256位 | 快 | 高 | 低 |
非对称加密算法比较
| 名称 | 成熟度 | 安全性 | 运算速度 | 资源消耗 |
|---|---|---|---|---|
| RSA | 高 | 高 | 中 | 中 |
| ECC | 高 | 高 | 慢 | 高 |
34.机器学习&人工智能
- 分类器:做分类的算法。
- 特征用来帮助分类的值。
- 需要不断训练
- 对于比较难以区分的,可以加上新条件,即决策边界。
- 最大化正确分类+最小化错误分类。
- 决策树
- 需要选择什么特征来分类。
- 每个特征用什么值。
- 决策树和支持向量机这样的技术发源自统计学。
- 深度学习
35.计算机视觉
- 图像是像素网格,每个像素的颜色通过三个基色定义:红,绿,蓝。通过组合三种颜色的强度可以得到任何颜色,也叫RGB值。
- 颜色跟踪算法是一个个像素搜索。
- 物体的边缘,是多个像素组成的。为识别这些特征,算法要一块块像素来处理,
36.自然语言处理:NLP
-
名词,代词,冠词,动词,形容词,副词,介词,连词,感叹词。
-
使用短语结构规则用于计算机,句子可以由一个名词短语和一个动词短语组成,可以给一门语言指定出一堆规则,用这些规则,可以做出分析树。如何采集声音,信号来自麦克风内部隔膜震动的频率,横轴是时间,竖轴是隔膜移动的幅度。我们换一种图谱,横轴还是时间,竖轴是不同频率的振幅,颜色越亮,那个频率的声音越大
37.机器人
- 机械爪
- 人工智能
- 无人驾驶
- 类人机器人
38.计算机心理学
- 计算机只是工具,要了解人类心理学,做出更好的计算机。
- 设计程序时要考虑易用度。
- 直观功能:如让菜单选项好找好记。
- 让计算机有一定的情商,能根据用户的状态做出合适的反应。
- 计算模型
39.教育科技
- 拓展学习渠道
- MOOC
- 智能辅导系统
- 虚拟现实和增强现实
40.奇点,天网,计算机的未来
-
人工智能是否会超越人类的智力?大讨论
-
智能科技的失控性发展叫奇点。
-
计算机的发展对人类的影响:巨大的挑战,如对岗位的取代。
-
新技术:穿戴式设备、3D打印、加密货币等等
参考文章
https://blog.csdn.net/weixin_44186849/article/details/115394367
百度百科等内容