redis-数据类型及样例
一.string 类型数据的基本操作
1.添加/修改数据
set key value
2.获取数据
get key
3.删除数据
del key
4.添加/修改多个数据
mset key1 value1 key2 value2
5.获取多个数据
mget key1 key2
二.list类型的基本操作
- 数据存储需求:存储多个数据,并对数据进入存储的顺序进行区分
- 需要的存储结构:一个存储空间保存多个数据,且通过数据可以体现进入顺序
- list类型:保存多个数据,底层是用双向链表的存储结构实现的。
1.lpush/rpush key value1 [value2] …… :添加数据
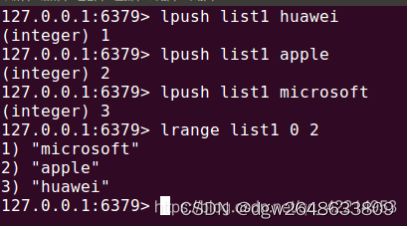
可以看出我们先从左边放入一个huawei,再从左边放入一个apple,然后继续向左边放入一个microsoft,因此打印的顺序是从左到右,即:microsoft,apple,huawei.
可以自行测试rpush和rpush、lpush的联合使用。
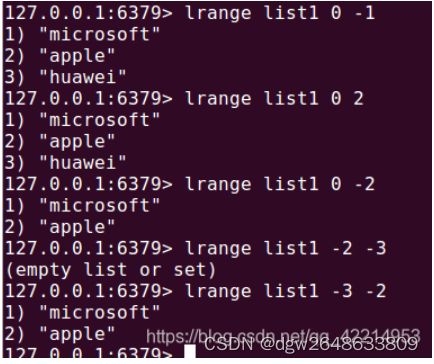
2.lrange key start stop :获取范围数据
我们可以金桔list里面的索引来获取数据,其中第一个数据的下标为0,和数组的编号方式一样,但是不同的是,在list中最后一个元素的索引为-1,倒数第二个元素的编号为-2,因此在list中每个元素有两个索引,从左到右从0开始编号,从右往左从-1开始编号。测试如下图:
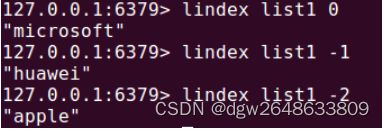
3.lindex key index:获取index索引位置上的值
4.llen key:获取list中值的个数
![]()
5 lpop/rpop key:获取并移除数据
list中最牛X的操作就是lpush/rpush配合lpop/rpop 来使用。

三.set类型的基本操作
与List相比,Set集合中的元素不允许重复,一个集合中最多可以对应2^32-1(4294967295)个元素。
1. 基本命令
对我们来说,常用的Set命令有如下几种

2.插入操作

3. 查询操作

4. 删除操作

四.zset类型的基本操作
1.常用命令
2.示例
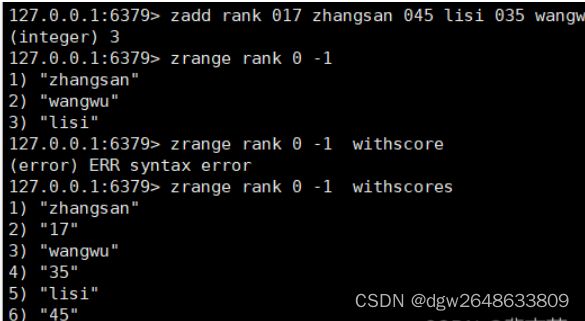
zadd ...
将一个或多个member元素及其score值加入到有序集key当中。
![]()
zrange
返回有序集key中,下标在
0到-1就是返回全部的元素,从小到大排列。
加上withsorces 可以附带着分数返回
zrangebyscore key min max [withscores] [limit offset count]
返回有序集 key 中,所有score值介于min和max 之间(包括等于min或max )的成员。有序集成员按score值递增(从小到大)次序排列。
zrevrangebyscore key max min [withscores] [limit offset count]
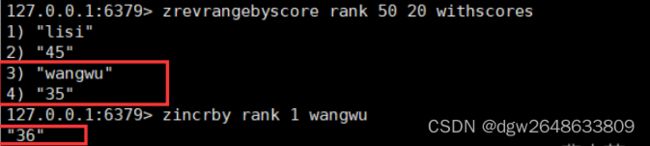
同上,改为从大到小排列。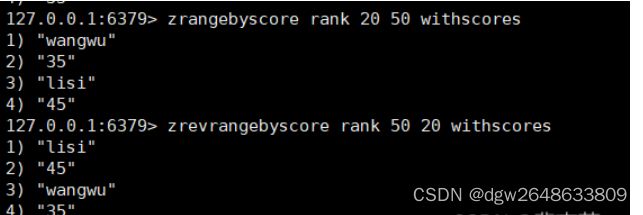
zincrby
为元素的score加上增量
zrem
删除该集合下,指定值的元素v
zcount
统计该集合,分数区间内的元素个数。
zrank
返回该值在集合中的排名,从0开始。
五.hash类型的基本操作
1、往redis库中插入一条hash类型的数据
redis> hset key field value
举例:
redis 127.0.0.1:6379> hset user001:zhangsan iphone 6
(integer) 1
redis 127.0.0.1:6379> hset user001:zhangsan xiaomi 7
(integer) 1
redis 127.0.0.1:6379> hset user001:zhangsan meizu 8
(integer) 1
在redis库中就形成了这样一条数据: 2、从redis库中获取一条hash类型数据的value
取出一条hash类型数据中所有field-value对
redis 127.0.0.1:6379> hgetall user001:zhangsan
1) "iphone"
2) "6"
3) "xiaomi"
4) "7"
5) "meizu"
6) "8"
取出hash数据中所有fields
redis 127.0.0.1:6379> hkeys user001:zhangsan
1) "iphone"
2) "xiaomi"
3) "meizu"
取出hash数据中所有的value
redis 127.0.0.1:6379> hvals user001:zhangsan
1) "6"
2) "7"
3) "8"
取出hash数据中一个指定field的值
redis 127.0.0.1:6379> hget user001:zhangsan xiaomi
"7"
为hash数据中指定的一个field的值进行增减
redis 127.0.0.1:6379> hincrby user001:zhangsan xiaomi 1
(integer) 8
从hash数据中删除一个字段field及其值
redis 127.0.0.1:6379> hgetall user001:zhangsan
1) "iphone"
2) "6"
3) "xiaomi"
4) "7"
5) "meizu"
6) "8"
redis 127.0.0.1:6379> hdel user001:zhangsan iphone
(integer) 1
redis 127.0.0.1:6379> hgetall user001:zhangsan
1) "xiaomi"
2) "7"
3) "meizu"
4) "8"
应用场景:购物车案例
public class BuyCartServiceImpl {
private Jedis jedis = null;
@Before
public void init(){
jedis = new Jedis("192.168.2.70",6379);
}
// 添加商品到购物车
@Test
public void testAddItemToCart(){
jedis.hset("cart:user02", "小米沙发", "1");
jedis.hset("cart:user02", "苹果手机", "2");
jedis.hset("cart:user02", "格力空调", "4");
jedis.close();
}
// 遍历购物车信息
@Test
public void testGetCartInfo(){
Map cart = jedis.hgetAll("cart:user02");
Set> entrySet = cart.entrySet();
for(Entry ent :entrySet){
System.out.println(ent.getKey()+ ":" + ent.getValue());
}
jedis.close();
}
// 更改购物车
@Test
public void editCart(){
//给蜡烛商品项的数量加1
jedis.hincrBy("cart:user02", "小米沙发", 1);
jedis.close();
}
// 从购物车中删除商品项
@Test
public void delItemFromCart(){
jedis.hdel("cart:user02", "苹果手机");
jedis.close();
}
}
从上面可见,用redis做购物车简直太方便了。 六.bitmaps类型的基本操作
1.bitmap概念
1:BitMap,即位图,其实也就是 byte 数组,用二进制表示,只有 0 和 1 两个数字。
2:bitmap并不是一种数据结构,实际上它就是字符串,但是可以对字符串的位进行操作。
3:bitmap有自己的一套命令。可以把bitmap想象成一个以bit为单位的数组,数组的每个单元存储0和1,数组的下标叫做偏移量。
2.设置name = "@"
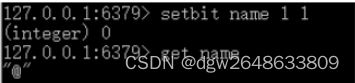
3.设置name='A'
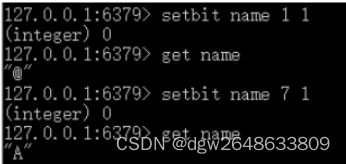
4.设置name='A@'
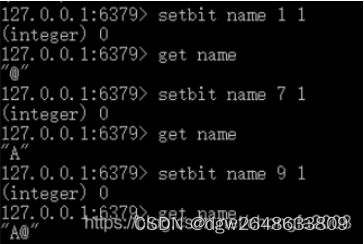
七.hyperloglog类型的基本操作
1、hyperloglog 简介
Redis 中 hyperloglog 数据类型是 2.8.9 版本引入的,是一种概率数据结构,用来估算数据的基数。基数就是指一个集合中不同值的数目,比如 a, b, c, d 的基数就是 4,a, b, c, d, a 的基数还是 4。虽然 a 出现了两次,但是只会被计算一次。
hyperloglog 通常用来统计一个集合中不重复的元素个数。一个很常见的例子就是统计某个文章的 UV(Unique Visitor,独立访客,一般可以理解为客户端 IP)。精确的计算数据集的基数需要消耗大量的内存来存储数据集。在遍历数据集时,判断当前遍历值是否已经存在唯一方法就是将这个值与已经遍历过的值进行一一对比。当数据集的数量越来越大,内存消耗就无法忽视,甚至成了问题的关键。
使用 Redis 统计集合的基数一般有三种方法,分别是使用 Redis 的 hashmap,bitmap 和 hyperloglog。前两个数据结构在集合的数量级增长时,所消耗的内存会大大增加,但是 hyperloglog 则不会。
2.hyperloglog 结构
1、hllhdr 定义
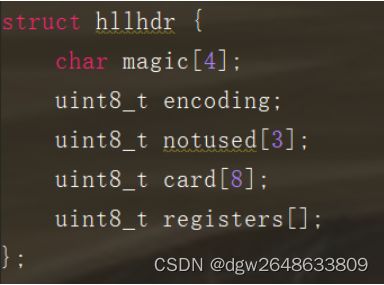
八.gepspatial类型的基本操作
1.geoadd 添加地理位置
# 规则:两级无法直接添加,我们一般会下载城市数据,直接通过java程序一次性导入!
# 有效的经度从-180度到180度。
# 有效的纬度从-85.05112878度到85.05112878度。
# 当坐标位置超出上述指定范围时,该命令将会返回一个错误,如:
127.0.0.1:6379> geoadd china:city 39.90 116.40 beijin
(error) ERR invalid longitude,latitude pair 39.900000,116.400000
# 参数 key 值()
127.0.0.1:6379> geoadd china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqi 114.05 22.52 shengzhen
(integer) 2
127.0.0.1:6379> geoadd china:city 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 2
2.geopos 获得当前坐标值
127.0.0.1:6379> GEOPOS china:city beijing # 获取指定的城市的经度和纬度!
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
127.0.0.1:6379> GEOPOS china:city beijing chongqi
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
3.geodist 返回两地之间的距离
127.0.0.1:6379> GEODIST china:city beijing shanghai km # 查看上海到北京的直线距离
"1067.3788"
127.0.0.1:6379> GEODIST china:city beijing chongqi km # 查看重庆到北京的直线距离
"1464.0708"
4.georadius 以给定的经纬度为中心, 找出某一半径内的元素
127.0.0.1:6379> GEORADIUS china:city 110 30 1000 km # 以110,30 这个经纬度为中心,寻找方圆1000km内的城市
1) "chongqi"
2) "xian"
3) "shengzhen"
4) "hangzhou"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withdist # 显示到中间距离的位置
1) 1) "chongqi"
2) "341.9374"
2) 1) "xian"
2) "483.8340"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withcoord # 显示他人的定位信息
1) 1) "chongqi"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) 1) "108.96000176668167114"
2) "34.25999964418929977"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withdist withcoord count 1 # 筛选出指定数量的结果!
1) 1) "chongqi"
2) "341.9374"
3) 1) "106.49999767541885376"
2) "29.52999957900659211"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km withdist withcoord count 2
1) 1) "chongqi"
2) "341.9374"
3) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) "483.8340"
3) 1) "108.96000176668167114"
2) "34.25999964418929977"
5.georadiusbymember 找出位于指定元素周围的其他元素
127.0.0.1:6379> GEORADIUSBYMEMBER china:city beijing 1000 km
1) "beijing"
2) "xian"
127.0.0.1:6379> GEORADIUSBYMEMBER china:city shanghai 400 km
1) "hangzhou"
2) "shanghai"
6.geohash 返回元素的 Geohash
127.0.0.1:6379> geohash china:city beijing chongqi
1) "wx4fbxxfke0"
2) "wm5xzrybty0"
7.Geospatial 的其他操作 -查看,删除
127.0.0.1:6379> ZRANGE china:city 0 -1 # 查看地图中全部的元素
1) "chongqi"
2) "xian"
3) "shengzhen"
4) "hangzhou"
5) "shanghai"
6) "beijing"
127.0.0.1:6379> zrem china:city beijing # 移除指定元素!
(integer) 1
127.0.0.1:6379> ZRANGE china:city 0 -1
1) "chongqi"
2) "xian"
3) "shengzhen"
4) "hangzhou"
5) "shanghai"