《Revisiting Pre-trained Models for Chinese Natural Language Processing》(MacBERT)阅读记录
《Revisiting Pre-trained Models for Chinese Natural Language Processin》
to appear at Findings of EMNLP 2020
链接:https://arxiv.org/abs/2004.13922
EMNLP,是自然语言处理经验方法会议(Conference on Empirical Methods in Natural Language Processing),是由国际语言学会(ACL)下属的SIGDAT小组主办的自然语言处理领域的顶级国际会议,也是自然语言算法的A类会议。
郭达森 https://zhuanlan.zhihu.com/p/296324423
摘要
BERT在很多NLP任务中都表现出了惊人的提升效果,很多BERT变体的提出,更进一步地提升了预训练模型的性能。
本文主要针对中文预训练模型,检验在非英语语言中的有效性。
提出了MacBERT,在多个方面提升了RoBERTa。采用MLM as correction(Mac)的策略。
在8个NLP任务上进行了实验,重新审视之前的一些预训练模型和本文提出的MacBERT。实验结果表明,MacBERT在很多NLP任务上能够达到SOTA。
结论
在本篇文章中:
- 重新审视了中文预训练模型,查看这些模型能否推广到除英语外的其它不同语言当中。
- 提出新模型MacBERT,使用MLM任务作为语言纠错方式,缓解预训练和微调阶段的差异。
- 在中文NLP任务上进行了广泛实验,MacBERT在很多任务上,效果都有提升。
- 消融实验显示:应该关注MLM任务,而非NSP任务及其变体。
未来工作
研究一种有效的方法来确定掩码的比率,而非启发式方法,以进一步提高预训练语言模型的性能。
启发式算法一段很好的解释
Dr.h https://www.zhihu.com/question/27666809/answer/826889734
介绍
BERT(Bidirectional Encoder Representaitions from Transformers)非常流行,且在最近的NLP研究中证明是有效的。其利用了大规模的未标记训练数据,生成了丰富的上下文表示。
机器阅读理解基线中(SQuAD (Rajpurkar et al., 2018), CoQA (Reddy et al., 2019), QuAC (Choi et al., 2018), NaturalQuestions (Kwiatkowski et al.,2019), RACE (Lai et al.,2017)),性能最高的模型仍是基于BERT和BERT变体的 (Dai et al., 2019; Zhang et al., 2019; Ran et al., 2019)。
预训练语言模型已成为自然语言处理新的基础组件。
从BERT开始,社区在优化预处理语言模型方面取得了巨大而快速的进步。例如:
ERNIE (Sun et al., 2019a), XLNet (Y ang et al., 2019), RoBERTa (Liu et al., 2019), SpanBERT (Joshi et al., 2019), AL-BERT (Lan et al., 2019), ELECTRA (Clark et al., 2020)
然而,训练基于Transformer的预训练语言模型,不像过去训练单词嵌入或其它传统NN一样容易。如:训练BERT-Large模型,含有24层Transformer和3.3亿个参数,想要瘦脸需要高内存计算设备,比如TPU(贵)。
虽然很多预训练语言模型已发布,但很少有人致力于在其他语言上构建强大的预训练语言模型。
这篇论文,会重新审视现有的流行预训练语言模型,将其调整为中文,构建中文预训练语言模型,看模型能否在英语以外的语言被很好地推广。
提出了新的预训练语言模型MacBERT,将原来的MLM任务替换为MLM as Correction(Mac)任务,减少了预训练和微调阶段的差异。
在八个流行的中文自然语言处理数据集上进行了广泛的实验,从句子级到文档级,如机器阅读理解、文本分类等。
结果表明,与其它预训练语言模型相比,MacBERT在大多数任务中可以获得更显著的提升。
本文贡献:
- 进行大量实证研究,通过仔细分析重新审视中文预训练模型在各任务中的表现。
- 提出一个新的预训练语言模型MacBERT,通过用相似的词对选中词进行掩码,缓解预训练和微调阶段的差距,证明对下游任务有效。
- 为进一步加快中文NLP未来研究,创建并向社区发布了中文预训练语言模型系列。
相关工作

阐述具有代表性的预训练语言模型。
BERT
Bidirectional Encoder Representations from Transformers (Devlin et al.,2019) (根据Transformer的双向编码器表示)
旨在通过在所有Transformer层中联合调节左右上下文,预训练深度双向表示。
两个预训练任务:MLM(随机对输入中的一些token进行掩码,仅根据上下文预测原始单词)、NSP(预测句子B是否是A的下一句话)
后来,进一步提出了全词掩码(whole word masking ,wwm),用于优化MLM任务中的原始掩码策略。每次都屏蔽掉一个完整单词所对应的所有token,而非随机选择WordPiece的token进行掩码。迫使模型在预训练任务中恢复整个单词,而非恢复WordPiece,增强挑战性。但这一策略只会影响预训练过程中的掩码策略,不会给下游任务带来额外负担。
ERINE
Enhanced Representation through kNowldge IntEgration (Sun et al., 2019a) (通过知识整合增强表示性)
优化BERT的掩码过程,包括entity-level masking 和 phrase-level masking (实体级别和短语级别)
实体级mask会mask掉命名实体(命名实体通常由几个单词组成),而非在输入中随机选择单词。
短语级mask是mask掉连续的单词,类似N-gram mask策略。
XLNET
Yang et al. (2019) 认为,现有的基于自动编码的预训练语言模型,如BERT,存在预训练和微调阶段的差异,因为掩码符号[MASK]在微调阶段不会出现。
为了缓解这个问题,提出了基于Transformer-XL (Dai et al., 2019)的XLNet。
通过两种方式进行修改:
- 第一种方法是最大化输入因子分解顺序的所有排列的期望可能性,称之为排列语言模型Permutation Language Model (PLM)。
- 将自编码语言模型更改为一个自回归语言模型(类似于之前的统计语言模型)
RoBERTa
Robustly Optimized BERT Pretraining Approach (Liu et al., 2019) (健壮优化bert预训练方法)
采用BERT原始架构,但做了更加精确的修改。
对BERT中的各种成分进行了仔细比较,包括掩码策略、训练步骤等。
在深入评估后,得出结论:
- 在更多数据上,用更大的batch和更长的序列训练更长时间。
- 移除NSP任务,使用动态掩码。
ALBERT
A Lite BERT (Lan et al., 2019)(简化BERT)
主要解决了BERT需要更高内存假设和训练速度慢的问题。
介绍了两种参数缩减技术:
- 分解嵌入参数:将嵌入矩阵分解为两个小矩阵。
- 跨层数据共享:在ALBERT每一层间共享Transformer的权值,极大减少参数。
提出sentence-order prediction(SOP) 句子顺序预测任务,替代之前的NSP任务。
ELECTRA
Efficiently Learning an Encoder that Classifiers Token Replacements Accurately (Clark
et al., 2020) 有效学习可精确替换分类器Token的编码器
采用了一种新的生成器-鉴别器(generator-discriminator)框架,类似于GAN (Goodfellow
et al., 2014)
生成器通常是一个小的MLM,学习去预测被mask token的原始词。
鉴别器经过训练,鉴别输入token是否被替换。为了实现有效训练,鉴别器只需要预测一个二进制标签表示“替换”,不像MLM的方式,去预测确切的被掩码的词汇。
微调阶段,只使用鉴别器。
中文预训练语言模型
之前的大多数结论在英语环境下正确,但想知道这些技巧是否在其他语言中适用。
本节:现有的预训练语言模型如何适应中文、MacBERT。
注意:这些模型都源自BERT,而没有改变输入性质,所以在微调阶段不需要修改,替换灵活。
BERT-wwm & RoBERTa-wwm
原始BERT中,WordPiece tokenizer (Wu et al., 2016)将文本且分为多个小的片段,
whole word masking(wwm)减轻了只mask某词一部分(word piece)的缺点,让模型更加易于预测。
使用繁体中文词汇分割(CWS)工具将文本分割为多个词,然后采用全词掩码而非单字掩码。实现过程中严格遵循全词掩码,且并没有改变其它组件,如掩码比率等。
使用LTP (Che et al., 2010)进行中文分词,以识别词的边界。
wwm只会影响预训练阶段,掩码token的选择。BERT输入仍然使用 WordPiece tokenizer来分割文本,等同于原始bert。
类似地,wwm也能应用于RoBERTa,其中,不采用NSP任务。
MacBERT
利用了以前的模型,只做了一些简单的改动,但对微调任务有显著提升——MacBERT(MLM
as correction BERT),预训练任务与BERT相同,但做了一些修改。
对于MLM任务,做了如下修改:
- 使用了WWM和N-Gram掩码策略选择候选token进行掩码。
- 词级unigram到4-gram的比例是40%,30%,20%,10%
- 在微调阶段,使用相似词做mask,而非用标记[MASK]。
- 使用基于word2vec相似度计算的Synonyms toolkit (Wang and Hu, 2017)获取相似词
- 如果一个N-gram被选做掩码,将单独寻找相似词。
- 对15%的输入词进行Mask,其中80%被替换为相似词,10%替换为随机词,剩下10%不做替换。
对于NSP-like任务,使用了自ALBERT(Lan et al., 2019)引入的sentence-order prediction(SOP)任务,其中,负样本是通过改变两个连续句子的原始顺序而产生的。
实验设置
预训练语言模型设置
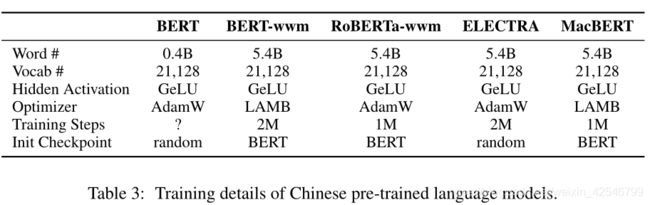
数据集:Wikipedia dump,同时使用简体中文、繁体中文
脚本:WikiExtractor.py (Devlin et al. (2019) )
生成1307个提取文件。
对原始文本进行数据清洗后(如移除HTML标签)、分离文档后,获得了大约0.4B的词汇。
由于中文维基百科数据相对较小,故除了维基百科外,还使用了额外的扩展数据,训练这些预训练过的语言模型(ext标签)
内部收集的扩展数据包括百科全书、新闻、问答网,有5.4个单词,是中文维基百科的10倍以上。
为了识别汉语词的边界,使用LTP (Che et al., 2010)进行汉语分词。我们使用官方的create pre-training data.py将原始输入文本转换为pre-training样本。
为了更好从现有预训练模型中获取知识,没有从头开始训练base级别模型,而是使用了Chinese BERT-base,继承其词汇表和权重。
然而,对于large级别模型,从头开始训练,但是仍然使用了base级别的词汇表。
训练BERT系列:
Devlin et al. (2019):先在最大长度128 tokens训练,然后在最大长度512 tokens训练。但是这会造成对长序列任务,如阅读理解任务,适应不足。
故对于RoBERTa和MacBERT,在整个预训练过程中直接使用最大长度512。
batch size<1024时,采用带有权重衰减优化的原始的ADAM进行优化,并且使用LAMB优化器在更大的batch中获取更好的可扩展性。
预训练在单个谷歌Cloud TPU5v3-8(相当于一个TPU)或TPU Pod v3-32(相当于4个TPU)上进行的,具体取决于模型的大小。
对于MacBERT-large:
- 训练2M步
- batch size:512
- 初始学习率:1e-4
微调任务设置
任务包含从句子级到文档级的广泛文本长度范围。


为公平比较,对于每个数据集,采用相同的超参数,并且只对每个任务的初始学习率从1e-5调整到5e-5。初始学习率是根据原始中文BERT调整的,如果针对具体任务调整,效果会更好。
通过选择最佳的平均开发集性能来确定最佳的初始学习率。
报告最大值和平均值来评估峰值和平均性能。
对于除ELECTRA之外的所有模型,对每个任务使用相同的初始学习率设置,如表2所示。
对于ELECTRA模型,我们按照Clark等人(2020)的建议,对base-level模型使用1e-4的通用初始学习率,对large-level模型使用5e-5的通用初始学习率。
如ERNIE、ERNIE 2.0、NEZHA的中文预训练模型,预训练数据有所不同,故只比较BERT (Devlin et al., 2019), BERT-wwm, BERT-wwm-ext, RoBERTawwm-ext, RoBERTa-wwm-ext-large, ELECTRA,以及MacBERT
除了Chinese BERT之外,都自己做了训练。在TensorFlow框架下完成了实验,并使用BERT的微调脚本做了轻微改动,以适应中文。
结果
机器阅读理解(Machine Reading Comprehension, MRC)
具有代表性的文档级建模任务,根据给定的文章回答问题。
测试数据集:CMRC 2018, DRCD,CJRC (介绍见论文)



使用额外的与训练数据会让结果有进一步改善。
MacBERT算法在所有阅读理解数据集上都有显著的改进
尽管DRCD是一个繁体中文数据集,使用额外的大规模简体中文进行训练也可以产生很大的积极效果。因为二者有很多相同字符。强大的预训练语言模型,只需要少量的繁体中文数据,也可以带来改进,而无需将繁体中文转换为简体中文。
单句分类(Single Sentence Classification)
数据集:ChnSentiCorp、THUCNews
ChnSentiCorp 评估情感分类,文本被分为积极或消极标签。
THUCNews 包含不同类型新闻的数据集,文本很长。
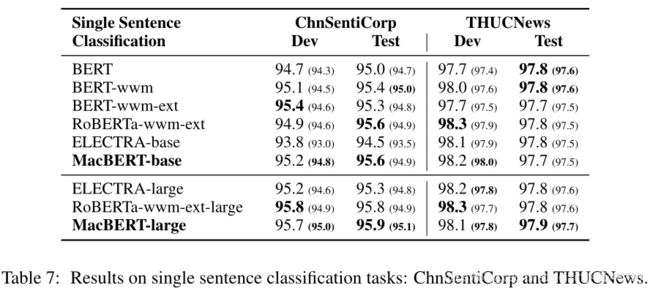
MacBERT可以对基线进行适度的提升,因为这些数据集已经达到了非常高的精度。
句子对分类(Sentence Pair Classification)
数据: XNLI data (Chinese portion), Large-scale Chinese Question Matching Corpus (LCQMC), and BQ Corpus
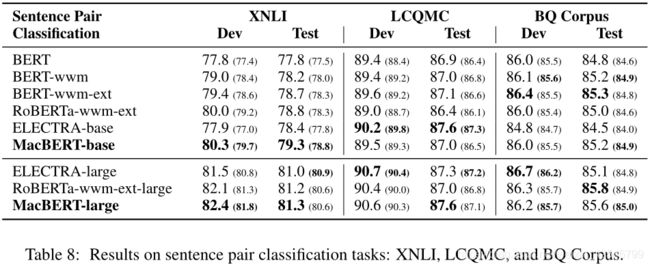
输入两个序列,预测二者关系
MacBERT的表现优于其他模型,但提升是中等的,在平均分数上有轻微的提升,但峰值性能不如RoBERTa-wwm-ext-large。
怀疑这些任务对输入的细微差异的敏感度低于阅读理解任务。因为句子对的分类只需要对整个输入产生统一的表示,因此提升中等。
讨论
MacBERT的有效性

总体平均分数是通过对每个任务的测试分数进行平均得到的(EM和F1指标在总体平均之前进行平均)。
从总体上看,删除MacBERT中的任何组件都会导致平均性能的下降,这表明所有的修改都有助于整体的改进。
最有效的修改是N-gram掩码和相似词替换,这是对MLM任务的修改。
- N-gram在文本分类任务中更加有效
- 相似词替换在阅读理解任务中更加有效
两种任务结合可以相互弥补。
NSP任务没有MLM任务重要,故设计一个更好地MLM任务来充分发挥文本建模的能力是非常重要的。
比较了NSP和SOD:
- SOP比NSP效果好,但不够显著。
- SOP任务需要识别两个句子的正确顺序,而不是使用随机句子,机器更容易识别。去除SOP任务会导致阅读理解任务相对于文本分类任务有明显的下降,这表明有必要设计一个类似nsp的任务来学习两个部分。(NSP主要提供这种文章连贯性上的知识)
MLM任务的调查研究
MLM依赖的两个方面:
- 选择要被屏蔽的tokens
- 替换所选tokens
替换将如何影响预训练语言模型的性能:
遵循原始掩码比率,输入句15%mask,其中10%不变,90%分为四类
- MacBERT:80%替换为相似词,10%替换为随机词
- Random Replace:90%替换为随机词
- Partial Mask:原始BERT实现,80%替换为[MASK],10%替换为随机词
- All Mask: 90%被替换为[MASK]
绘制从1M到2M的步骤,以显示比前1M步骤更稳定的结果。

大部分使用[MASK]进行掩码(即部分掩码和全部掩码)的预训练模型性能较差,说明预训练和微调的差异是影响整体性能的实际问题。
如果不留下10%作为原始token(identity project),也会有下降,这说明用[MASK] token掩码的健壮性较差,容易受到负样本训练中identity project缺失的影响。
90%替换为随机词,对[mask]依赖的屏蔽策略形成了改进。
依赖[MASK] token的原始掩码方法(微调任务中没有出现过这个token),会导致差异和更差的性能。
故使用相似词掩码,而非随机词掩码,防止破坏语境。
传统的N-gram语言模型是基于自然句而不是经过操纵的影响句。如果使用相似词,句子流畅性会更好,更加自然。
减小差异后,MacBERT获得了最好的性能,验证了假设。