【数据结构】KMP算法的详解以及使用JAVA来实现
目录
简单介绍KMP算法
KMP算法与BF算法的不同
Next数组
JAVA代码实现KMP算法
Next数组的优化——NextVal数组
简单介绍KMP算法
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。
KMP算法与BF算法的不同
KMP算法与BF算法的最大不同之处就在于当子串与主串匹配失败以后
主串的 i 指针不会回退
并且子串也不会回退到0下标的位置,而是返回到另一个下标的位置再重新开始进行匹配
我们举一个例子

假设有这么一个例子,当我们的主串 i 指向2下标的时候子串开始匹配
那么当我们的 j 走到3下标的时候发现匹配失败了
那么这个时候我们的 j 就需要回退到 0 下标但是我们的主串 i 并不用回退
因为之前的匹配的结果都是以失败结束的,所以就算我们回退了那么结果都还是失败的
所以主串的回退是没有必要的,当我们的主串和子串的结果匹配失败以后我们就让 i 前进一位
同时我们说到 j 也不会回退到0下标而是回退到我们特定的位置

以这两个串做例子,此时我们的匹配明显是失败了的
那么按照KMP算法我们的 i 首先是不会回退的,那么子串首先回退到 2 下标的位置
但我们发现 2 下标位置与i还是不匹配这个时候会回退到我们0下标位置
重新开始进行匹配了
那么我们的问题就是怎么知道子串每次回退的特定位置在哪里?
这个时候就要引出我们的Next数组了
Next数组
关于Next数组的意义就在于子串中每个元素回退的位置在哪里
也就是用 Next[j] = k 来表示不同的 j 来对应一个 K 值
这个 K 就是你将来 每一个下标要回退的位置在哪里
那么我们K的取值规则是这样的
找到匹配成功部分的两个相等的真子串(不包含本身)
一个以下标 0 字符开始,另一个以 j-1 下标字符结尾,
K的取值就是子串的长度
我们取0下标的K值为-1,取1下标的K值为0
举个例子
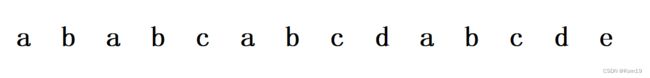
假设有这么一个字符串,我们要找到每一个下标所对应的K值
那么根据规则我们前面两个下标的K值已经知道了
那么我们从第三个下标开始取我们的K值
根据规则一个以下标 0 字符开始,另一个以 j-1 下标字符结尾
也就是说找到以a开始b结束的字符串,那么没有找到也就是说这样的字符串长度为0
那么第三个下标的K值为0
我们看第四个下标,寻找以a开始以a结束的字符串,结果是存在的
那么K的取值就是字符串的长度K=1
以此类推我们最终得到的结果如下

当我们了解了Next数组的基本实现逻辑之后
我们可以推到出 Next[i+1]的值是多少
 也就是图片上的这种情况,那么我们其实是可以推导出 Next[ i + 1 ]的值是多少的
也就是图片上的这种情况,那么我们其实是可以推导出 Next[ i + 1 ]的值是多少的
首先我假设Next[i] = K成立 ,那么p[0]---p[K-1]的长度与p[ x ]----p[ i - 1 ]是相同的
我们就可以推到出这个x是 x = i - k 的
所以是p[0]---p[K-1] 的长度与p[ i- k ]----p[ i - 1 ]是相同的
这个时候我们假设一个条件 p[ i ] == p[ k ]
那么我们带入进去,那么这时候p[0]---p[K] 的长度与p[ i- k ]----p[ i ]的长度是相同的
由于我们p[0]---p[K-1] 的长度与p[ i- k ]----p[ i - 1 ]是相同的的条件是Next[i] = K成立
那么这个时候p[0]---p[K] 的长度与p[ i- k ]----p[ i ]的长度是相同的也就能推出Next[i+1] = K+1
所以我们最终得出结论
在条件 p[ i ] == p[ k ]成立的情况下,我们通过推到可以得出Next[i+1] = K+1
那么在 p[i] != p[k] 成立的情况下又是怎么样的?
如果p[i] != p[k]那么我们的K指针就需要回退到当前元素所对应的Next数组中对应的K值处
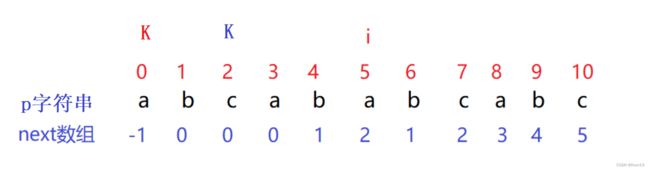
一直到我们K指针所指向的下标的元素与i指针指的下标相同为止
这个时候我们再让Next[i+1] = k+1
通过这种方式我们就实现了如何用代码来填充我们的Next数组的逻辑
JAVA代码实现KMP算法
public class KMP {
public static int KMP(String Str,String Sub,int pos){
if (Str == null || Sub == null){
return -1;
}
if (pos >= Str.length() || pos < 0){
return -1;
}
int i = pos;
int j = 0;
int[] next = new int[Sub.length()];
getNext(next,Sub);
while(i < Str.length() && j < Sub.length()){
if (j == -1 || Str.charAt(i) == Sub.charAt(j)){
i++;
j++;
}else {
j = next[j];
}
}
if (j >= Sub.length()){
return i-j;
}else {
return -1;
}
}
public static void getNext(int[] next,String sub){
next[0] = -1;
next[1] = 0;
int i = 2;
int k = 0;
//由于我们设定好了next数组前两位的值
//所以我们使用我们上面所讲到的逻辑就可以很好的完成我们的填充
while(i < next.length){
if (k ==- 1 || sub.charAt(k) == sub.charAt(i-1)){
next[i] = k+1;
i++;
k++;
}else {
k = next[k];
}
}
}
}Next数组的优化——NextVal数组
我们举一个例子

那么为什么nextVal数组会是这样的呢?
我们nextVal数组的意义就在于当我们的匹配失败了以后,回退的位置不能一步到位而是要经过繁琐的步骤以后才能到达我们最终的位置
所以我们就设计出来了nextVal数组来帮助我们解决这个问题
具体的规则就是首先求出next数组,然后逐一分析,如果当前回退位置下标的字符与当前字符是一样的那么就写回退位置下标的nextVal数组的值,如果不一样那么就写当前字符所对应的next数组里面的值
比如next数组值为0的a字符,在next数组中如果他进行回退那么回退后的下标就是a,所以他的nextVal所对应的值就是-1
在这个字符串中由于b回退后的下标是下标7,那么此时b字符与a字符并不相同,所以在nextVal数组b这个字符的值就是b本身在next数组中所对应的值 7