深度学习-4-二维目标检测-YOLOv5源码解读
一、版本说明
YOLOv5存在不同的更新版本,我下载运行的是master和5.0版本。
可以从github上下载不同版本的链接:https://github.com/ultralytics/yolov5/tags
GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite

二、项目目录结构
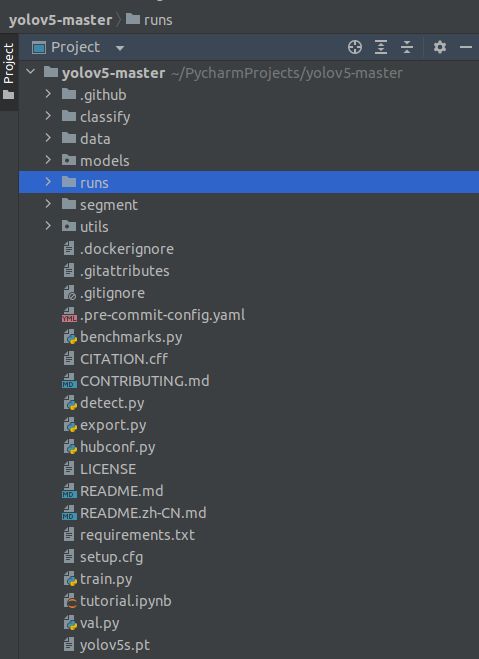
1.整体目录
将源码文件包下载,用pycharm打开,并配置好环境,整体目录如下。
2.data文件夹
主要是存放一些超参数的配置文件(如.yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称,还有一些官方提供测试的图片。YOLOv5有大约30个超参数用于各种训练设置。更好的初始猜测会产生更好的最终结果,因此在训练正确初始化这些值很重要。


3.models文件夹
模型文件,里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别是s、m、l、x。它们的检测速度分别是从快到慢,但精确度是从低到高。
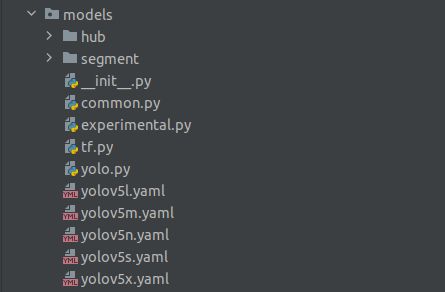
hub文件夹存放yolov5各版本目标检测网络模型配置文件

4.runs文件夹
使我们运行时的输出文件,每一次运行就会生成一个exp文件夹

5.utils文件夹
存放的是工具类的函数,里面有loss函数、metrics函数、plots函数等
6.其他一级目录文件

三、detect.py文件
1.Run函数
1.判断source传入数据
①is_file: 判断输入图片格式是否在设定格式中(dataset.py)
②webcam:false
2. Directories,新建保存结果文件夹
3. Load model,加载模型①device:选择设备,摄像头、GPU、CPU等
②model:(weight,coco.yaml)显示后端框架(pytorch、TorchScri等)
DetectMultiBackend(common.py)
③加载模型数据
④imgsz保证图片尺寸为32的倍数,不是则自动计算出32倍数尺寸
4. Dataloader,加载待预测图片
dataset=LoadImages(datasets.py) 初始化
5. Run inference,输入模型推理产生推理结果画出识别框:
初始化:
Warmup:传入一张空图片到GPU预热
遍历dataset(LoadImages):
im: 图片numpy转pytroch支持的格式
Inference: 预测NMS: 非极大值过滤
Process:
6. Print results,打印输出结果
四、yolov5s.yaml-神经网络结构
这个文件其实只是指导我们搭建模型的配置文件的说明书,供我们参考此文件配置自己的模型文件。 先如图了解yolov5网络结构:
1.backbone
# 0-P1/2 第一层
from:-1表示该输入从上一层传过来,【-1,6】表示从11和6层传过来
number:表示模块结构数量,若number>1,则数量=number*depth_multiple
module:模块结构(Conv、C3等),卷积层结构,定义于(common.py)
args: 传入参数,需要联系到common各网络层模型类别确定各参数含义
P1: 第一层
/2: 步长为2,图片长宽尺寸分别除以2(图片分辨率要求长宽为32倍数的原因)
# 1-P2/4 第二层:依次往下逐层叠加
2.head
nn.Upsample: 上采样层
Concat: 综合各层传出特征的网络层
Detect: 推理检测层
3.神经网络层的叠加
一共有24层神经网络层,那么这24层是怎么相互叠加的呢,是简单的逐层叠加吗?
实际上的网络结构是这样的:(网上多处的网络结构解析backbone都是从上往下叠加的,这里从B站up取经得到的从下往上的神经网络结构)
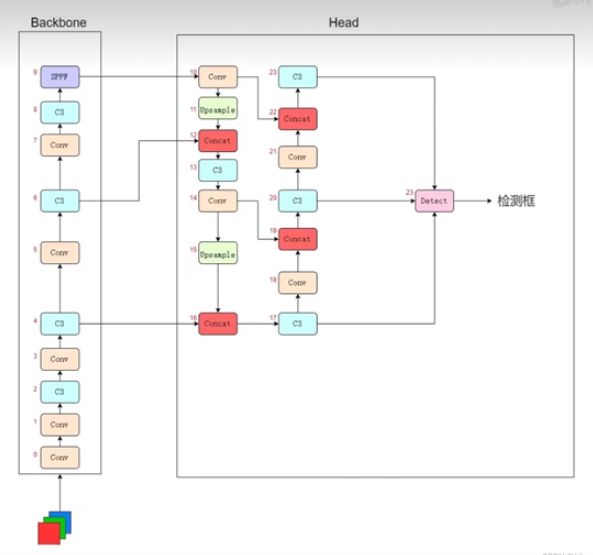
这个图表示的是,往神经网络中传入一个RGB三通道的图片,经过Backbone10层网络后,进入Head进行上采样,综合特征处理等,最终有3个C3网络层输出到Detect层。
这3个C3层从上到下就是我们说的高层特征层、中层特征层、低层特征层。这些特征层区别在于低层检测小目标,中层检测中型目标,高层检测大目标,综合起来预测目标。
4.参数
nc: 目标类别数
Anchors: 三层对应不同的特征层级
[10,13, 16,30, 33,23] 低层3个anchor,10×13,16×30,33×23
[30,61, 62,45, 59,119] 中层3个anchor
depth_multiple: 模型深度倍数,创建模型时number* depth_multiple
width_multiple: 通道倍数,每层通道参数* width_multiple=传出通道数,深度宽度参数相乘不为整向下取整
depth_multiple,width_multiple决定模型复杂程度,值越大越复杂准确率越高,耗时长
对于各种模型文件的准确率:n 1.创建yolov5模型 2.搭建网络结构 3.定义模型# YOLOv5 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
五、yolo.py-神经网络实现