基于Yolov5与LabelMe训练自己数据的图像分割完整流程
基于Yolov5与LabelMe训练自己数据的实例分割完整流程
-
- 1. Yolov5配置
- 2. 创建labelme虚拟环境
- 4. 接下来开始使用labelme绘制分割数据集
-
- 4.1 json to txt
- 4.2 划分数据集(可分可不分)
- 5. 训练
1. Yolov5配置
参照这边文章:
https://blog.csdn.net/ruotianxia/article/details/132262747?spm=1001.2014.3001.5502
yolov5 各模型的百度网盘链接:
链接:https://pan.baidu.com/s/1ryXteXqMXCDy4V9dWqCmzw 提取码:ca3x
2. 创建labelme虚拟环境
conda create -n labelme python=3.9
# 激活labelme 环境,后续的安装都在里面进行
conda activate labelme
# 下载label代码
git clone https://github.com/wkentaro/labelme.git
cd labelme
conda install -c conda-forge pyside2 # 这条一定要安装
pip install .
pip install pyinstaller
pyinstaller labelme.spec
# 编译完成后,再cmd中输入
labelme
即可打卡
# 不从源码安装的话,直接按照官网上给的提示安装就行,不用这么麻烦
# 安装完成
如果有些因为网络差下不下来,可以一个一个的安装
# 网络不好的情况下,安装会出现中断,将中断处的依赖库单独使用清华镜像下载,然后再继续执行上一句
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple PyQt5-Qt5
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple networkx
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple PyWavelets
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnxruntime
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit_image
4. 接下来开始使用labelme绘制分割数据集
操作比较简单,这里就不多说了,其保存的是json格式,需要转换成yolo需要的txt.

4.1 json to txt
https://blog.csdn.net/m0_51530640/article/details/129975257 参考文章
# -*- coding: utf-8 -*-
import json
import os
import argparse
from tqdm import tqdm
def convert_label_json(json_dir, save_dir, classes):
json_paths = os.listdir(json_dir)
classes = classes.split(',')
for json_path in tqdm(json_paths):
# for json_path in json_paths:
path = os.path.join(json_dir, json_path)
with open(path, 'r') as load_f:
json_dict = json.load(load_f)
h, w = json_dict['imageHeight'], json_dict['imageWidth']
# save txt path
txt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))
txt_file = open(txt_path, 'w')
for shape_dict in json_dict['shapes']:
label = shape_dict['label']
label_index = classes.index(label)
points = shape_dict['points']
points_nor_list = []
for point in points:
points_nor_list.append(point[0] / w)
points_nor_list.append(point[1] / h)
points_nor_list = list(map(lambda x: str(x), points_nor_list))
points_nor_str = ' '.join(points_nor_list)
label_str = str(label_index) + ' ' + points_nor_str + '\n'
txt_file.writelines(label_str)
if __name__ == "__main__":
"""
python json2txt_nomalize.py --json-dir my_datasets/color_rings/jsons --save-dir my_datasets/color_rings/txts --classes "cat,dogs"
"""
classes_name = 'scratch,dirty' # 中间不能带空格
parser = argparse.ArgumentParser(description='json convert to txt params')
parser.add_argument('--json-dir', type=str, default='voc_dataset/seg_labels_json', help='json path dir')
parser.add_argument('--save-dir', type=str, default='voc_dataset/seg_labels_txt', help='txt save dir')
parser.add_argument('--classes', type=str, default=classes_name, help='classes')
args = parser.parse_args()
json_dir = args.json_dir
save_dir = args.save_dir
classes = args.classes
convert_label_json(json_dir, save_dir, classes)
4.2 划分数据集(可分可不分)
https://blog.csdn.net/m0_51530640/article/details/129975257 参考文章
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
import argparse
# 检查文件夹是否存在
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def main(image_dir, txt_dir, save_dir):
# 创建文件夹
mkdir(save_dir)
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
img_train_path = os.path.join(images_dir, 'train')
img_test_path = os.path.join(images_dir, 'test')
img_val_path = os.path.join(images_dir, 'val')
label_train_path = os.path.join(labels_dir, 'train')
label_test_path = os.path.join(labels_dir, 'test')
label_val_path = os.path.join(labels_dir, 'val')
mkdir(images_dir);
mkdir(labels_dir);
mkdir(img_train_path);
mkdir(img_test_path);
mkdir(img_val_path);
mkdir(label_train_path);
mkdir(label_test_path);
mkdir(label_val_path);
# 数据集划分比例,训练集75%,验证集15%,测试集15%,按需修改
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
total_txt = os.listdir(txt_dir)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_dir, name + '.bmp')
srcLabel = os.path.join(txt_dir, name + '.txt')
if i in train:
dst_train_Image = os.path.join(img_train_path, name + '.bmp')
dst_train_Label = os.path.join(label_train_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = os.path.join(img_val_path, name + '.bmp')
dst_val_Label = os.path.join(label_val_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = os.path.join(img_test_path, name + '.bmp')
dst_test_Label = os.path.join(label_test_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
"""
python split_datasets.py --image-dir my_datasets/color_rings/imgs --txt-dir my_datasets/color_rings/txts --save-dir my_datasets/color_rings/train_data
"""
parser = argparse.ArgumentParser(description='split datasets to train,val,test params')
parser.add_argument('--image-dir', type=str, default='voc_dataset/seg_images', help='image path dir')
parser.add_argument('--txt-dir', type=str, default='voc_dataset/seg_labels_txt', help='txt path dir')
parser.add_argument('--save-dir', default='voc_dataset/split', type=str, help='save dir')
args = parser.parse_args()
image_dir = args.image_dir
txt_dir = args.txt_dir
save_dir = args.save_dir
main(image_dir, txt_dir, save_dir)
5. 训练
训练可以直接运行segment中的train,需要修改下文件的路径,根据自己的需要进行修改。
注意需要再train.py的目录下放置一个detection 训练模型。
如果没有分割好的数据集,代码会自动下载coco128-seg。可以先熟悉下各文件的分布和训练流程。
my-yolov5x-seg.yaml 修改类别数量
my-coco128-seg.yaml 修改数据路径,类别名称
hyp.scratch-low.yaml 修改训练参数
parser.add_argument('--weights', type=str, default=ROOT / 'weights/best.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default=ROOT / 'models/segment/my-yolov5x-seg.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/my-coco128-seg.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
配置好后,直接运行trainpy就可以了。预测的话在predict中,同样修改下文件路径就可以预测图片的结果。
predict.py 需要修改的内容如下:

预测时可以修改以下两个参数,一个是置信度阈值,一个是iou阈值:
parser.add_argument('--conf-thres', type=float, default=0.006, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.1, help='NMS IoU threshold')
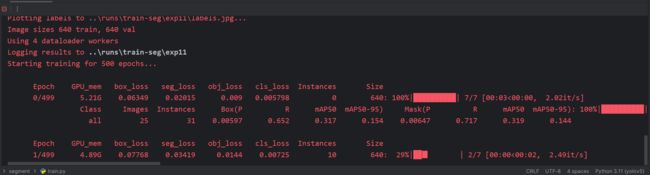
下面的是coco128训练出的结果: