selenium+webdriver实现自动化登陆并评论csdn下载过的资源
1,安装selenium
很简单,控制台pip install selenium即可
2,下载geckodriver放在python scripts目录中
3,测试是否可以正常运行
from selenium import wendriver
browser=webdriver.Firefox()
browser.get('https:/www.csdn.net')
time.sleep(3)
browser.close()
输入以上测试代码看看时候可以正常打开firefox浏览器,如果可以正常运行,说明环境搭建已经OK了
4,编程思路分析
本文实现的是自动化登陆csnd并且自动化评论自己曾经下载过的资源(评论貌似会有积分赠送,如果自己曾经下载过很多资源的话,手工评论还是很考验耐心的。你懂的,程序员就应当当个“懒人”哈哈哈!)本文目的不在此,在于练习selenium+webdriver。熟练掌握这个工具能带来许多乐趣,看懂是一回事,自己做过一次才知道。废话少说,分析一下程序实现的思路。
思路很简单,不要自己吓自己,一步步来!
1,肯定要先登陆,这里有一个点难了我很久,特此记录一下,打开登陆页面默认的不是输入用户名和密码的界面,得先点击一下账号登陆才会涨到输入用户名密码的界面,不过这个只是js实现的一个效果而已,然后自己并不是很懂selenium的js应用(还要去学习一下selenium的execute_script()),这里我在网上查了好久,最后在stackoverflow上看到一个解决的办法(链接:Selenium and Python can't click href="javascript:void(0);" with .click() - Stack Overflow)还是得多看看这些外国得网站啊,上面的一般英文写的都很简单,一看就懂啥意思

点击账号登陆之后:

转到登陆窗口之后,那就很简单了,直接
browser.find_element_by_xpath('xxxx').send_keys('username')
browser.find_element_by_xpath('xxxx').send_keys('password')
browser.find_element_by_xpath('xxxx').click()#点击登陆按钮
这就大功告成了!!!
分析下载页面链接规律:https://download.csdn.net/my/downloads/2,发现只有后面的数字发生变化,这就很简单了
直接取最后一页链接的最后一位就可以知道一共有多少页了,说干就干:
#获取总的页数
lastpage=browser.find_element_by_link_text("尾页").get_attribute('href')
#print (lastpage)
totlapage=int(lastpage[len(lastpage)-2:])
2,提取每一页中的评论地址
可以看到如果没有评论的话会显示“立即评论”这四个字,我们通过find_elements_by_link_text("立即评论")(注意这里使用 的是find_elements_by_link_text,和find_element_by_link_text()是有很大的区别的,不多说,看多了个s你就懂是什么意思了吧,哈哈)
urlc=browser.find_elements_by_link_text("立即评价")
3,最后依次打开地址去评论

需要我们输入的地方有两个,最后再点击发表评论,即可以完成评论
4,效果图
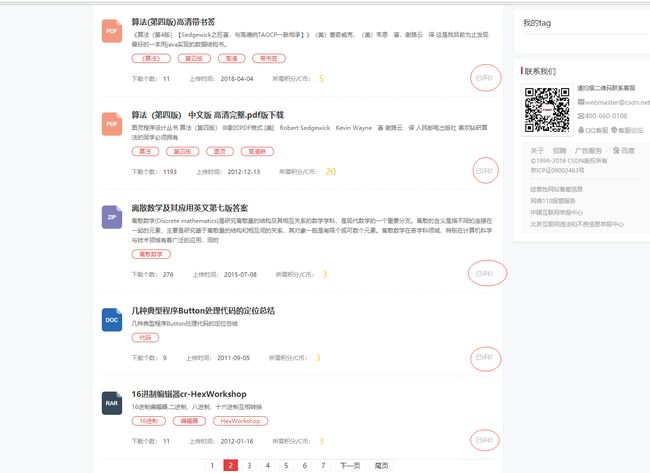
5,总结
程序很简单,没有做考虑很很复杂的情况,没有做太多的异常处理,本文仅仅是实现了简单的自动登陆到自动评价,评价内容和评价的星级是写死的,后期可以加以完善。虽然看起来很简单的一个小程序,但是却足足花了我一个下午的时间才写出来,编码的能力还是有待提高。另外,简单的东西要自己动手做做看,不然都不知道自己有多菜,。眼高手低,永远也是成不了高手的(自己也是一个菜鸟,哈哈,写这个博客就是为了提醒自己有多菜……^_^,毕)
6,附程序代码(仅供参考)
#coding:utf-8
'''
Created on 20184月26号
@author: phny
'''
from selenium import webdriver
import time
#browser=webdriver.Chrome()#用google会报错,暂时不知道为什么
browser=webdriver.Firefox()
browser.get('https://passport.csdn.net/account/login')
#转到用户名密码登陆,这里是个难点,卡了我好久,后来在stackoverflow上看到这样的解决方案,试了一下,果然灵
aElements = browser.find_elements_by_tag_name("a")
for name in aElements:
if(name.get_attribute("href") is not None and "javascript:void" in name.get_attribute("href")):
print("IM IN HUR")
name.click()
break
time.sleep(0.5)
browser.find_element_by_id('username').send_keys('your_username')
#time.sleep(0.5)
browser.find_element_by_id('password').send_keys('your_password')
#time.sleep(0.5)
browser.find_element_by_class_name('logging').click()
print("logging success!")
time.sleep(2)
#print (browser.page_source)
#转到的下载页面
browser.get('https://download.csdn.net/my/downloads')
#获取我下载过的内容的评价链接
time.sleep(0.5)
#获取总的页数
lastpage=browser.find_element_by_link_text("尾页").get_attribute('href')
#print (lastpage)
totlapage=int(lastpage[len(lastpage)-2:])
for i in range(2,totlapage+1):
#构造下载链接
url1='https://download.csdn.net/my/downloads/'+str(i)
#打开每一页
browser.get(url1)
time.sleep(0.5)
#获取评论链接
urlc=browser.find_elements_by_link_text("立即评价")
for comment_link_per_page in urlc:
#转到评论链接
try:
print (comment_link_per_page.get_attribute('href'))
commurl=comment_link_per_page.get_attribute('href')
#打开新的标签页
browser.execute_script("window.open()")
print (browser.window_handles)
#切换到新的标签页中
browser.switch_to_window(browser.window_handles[1])
#打开评论链接
browser.get(commurl)
time.sleep(0.5)
#给出几颗星,这里默认给出的是五颗星(xpath定位比css定位好使,有时候css定位不行但是xpath定位却可以,神奇)
browser.find_element_by_xpath("/html/body/div[5]/div[2]/div[1]/div[2]/div[2]/form/div/div[1]/ul/li[2]/i[5]").click()
#输入评论内容
browser.find_element_by_id('cc_body').send_keys("机器人评论!!!")
time.sleep(0.5)
#点击发表评论
browser.find_element_by_xpath('/html/body/div[5]/div[2]/div[1]/div[2]/div[2]/form/div/div[3]/button').click()
time.sleep(0.5)
#关闭打开的标签页
browser.execute_script("window.close()")
#返回原来的tab标签页中
browser.switch_to_window(browser.window_handles[0])
except:
browser.execute_script("window.close()")