Python爬虫实战(02)—— 爬取诗词名句三国演义
目录
前言
一、准备工作
二、爬取步骤
1. 引入库
2. 发送请求拿到页面
3.定位到章节URL
4.拼接URL拿到章节内容
5.存储各章节内容
完整代码
前言
这次爬虫任务是从诗词名句上爬取《三国演义》整本小说的内容,每一章的内容都给它下载下来。我们使用的是 BeautifulSoup 这个模块。
一、准备工作
首先我们要安装 lxml 和 bs4,并不是安装BeautifulSoup
(1)在命令行输入安装命令: pip install selenium,默认安装最新版本
pip install lxml
pip install bs4(2)采用pycharm自带方式安装
file -> settings-> Project: setest -> Project Interpreter
点击左上的"+" 号,在搜索框内输入selenium -> Install Package
诗词名句网:《三国演义》全集在线阅读_史书典籍_诗词名句网
二、爬取步骤
1. 引入库
需要从bs4中导出BeautifulSoup模块: from bs4 import BeautifulSoup
引入os库是为了创建路径,将爬取到的三国演义各个章节的内容保存在一个文件夹里
import requests
from bs4 import BeautifulSoup
import lxml
import os2. 发送请求拿到页面
注意页面的编码类型为 utf-8
加入请求头headers,当对方平台设置了UA权限的时候,我们通过工具去发起请求的时候,就会提示各种错误。当我们添加了一个User-Agent请求头,再去执行请求的时候,就可以得到正确的结果了。设置请求头的方法参考:https://blog.csdn.net/ysblogs/article/details/88530124
url1 ='https://www.shicimingju.com/book/sanguoyanyi.html'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
# 发送请求拿到页面
resp = requests.get(url=url1,headers=headers)
resp.encoding='utf-8'
page_text = resp.text
resp.close()3.定位到章节URL
在诗词名句网页面,右键->检查,定位到章节的标题:

而我们点进去第一章的页面,查看URL, 发现后半截对上了:
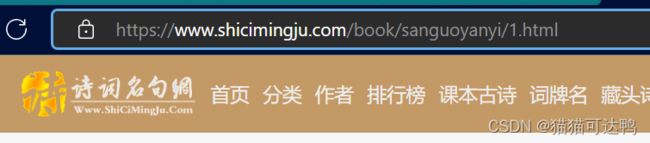
所以,要获取完整的URL,要将前面的部分拼接上。
URL的后半部分在 " .book-mulu>ul>li " 标签下,">"代表逐级查找,即查找book-mulu标签下的 ul 标签,再查找 ul 下的 li 标签,存入list
这里使用的是 lxml 的HTML解析器,需要导入lxml 库
soup1 = BeautifulSoup(page_text,'lxml')
book_menu_list = soup1.select('.book-mulu>ul>li')4.拼接URL拿到章节内容
遍历 book_menu_list 列表将URL拼接完整,对a标签使用string方法,拿到的文本就是章节标题
BeautifulSoup中使用标签名来获取结点的文本内容的方法:
soup.标签.text
soup.标签.string
soup.标签.get_text()
for li in book_menu_list:
content_url = 'https://www.shicimingju.com'+li.a['href']
title = li.a.string
resp1 = requests.get(url=content_url,headers=headers)
resp1.encoding='utf-8'
page_content = resp1.text
resp1.close()
soup2 = BeautifulSoup(page_content,'lxml')
content = soup2.find('div',class_="chapter_content").text5.存储各章节内容
下面的操作在for循环中进行,需要导入os库,以便于创建路径
文本内容的写入用 ' w '( write 的缩写),记得编码形式为 utf-8
用 with open()方法内容写入完毕后,是会自动关闭的,不需要我们 fp.close()
我这里是不同章节存到不同的txt文件中,用抓取到的章节名称 title 做文件名
if not os.path.exists(path):
os.mkdir(path)
with open (path+'./'+title+'.txt','w',encoding='utf-8')as fp:
fp.write(title+r'/n'+content+r'/n')
print(title+'下载完毕!')完整代码:
import requests
from bs4 import BeautifulSoup
import lxml
import os
url1='https://www.shicimingju.com/book/sanguoyanyi.html'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
resp = requests.get(url=url1,headers=headers)
resp.encoding='utf-8'
page_text = resp.text
resp.close()
path='诗词名句网三国演义'
soup1 = BeautifulSoup(page_text,'lxml')
# 定位章节的后半段URL
book_menu_list = soup1.select('.book-mulu>ul>li')
for li in book_menu_list:
content_url = 'https://www.shicimingju.com'+li.a['href']
# string方法提取标签中的文本
title = li.a.string
resp1 = requests.get(url=content_url,headers=headers)
resp1.encoding='utf-8'
page_content = resp1.text
resp1.close()
soup2 = BeautifulSoup(page_content,'lxml')
content = soup2.find('div',class_="chapter_content").text
# 如果路径不存在,创建存储路径
if not os.path.exists(path):
os.mkdir(path)
with open (path+'./'+title+'.txt','w',encoding='utf-8')as fp:
fp.write(title+r'/n'+content+r'/n')
print(title+'下载完毕!')
文章到这里就结束了,感谢您的阅读~