正则表达式中文字符匹配
准备工作
在线UTF-8编码汉字互转,大概只用x后面的四位就可以
搜了很多资料,看到很多老教程讲的方法,程序跑不了,就自己来试试了
1、匹配所有中文字符
'[\u4e00-\u9fa5]' 
2、匹配书名号及内容
'\u300A(.*)\u300B' 
书名号等中文标点符号,也需要查它对应的UTF-8编码
3、匹配特定文字
比如我们要匹配“作者:”,就把它复制到在线UTF-8编码汉字互转的应用里

得到x后面的4位才是有用的,大小写好像没什么要求,如下:
'\u4f5c\u8005\uff1a'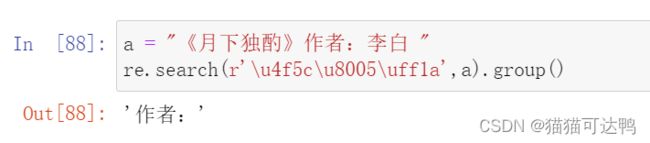
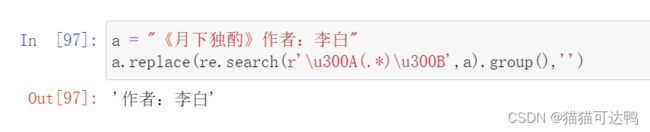
4、匹配除特定内容以外的部分
没找到什么好的正则方法,直接replace掉了,或者用group的方法?大家有什么好方法的话可以评论留言!比如这里匹配书名号以外的内容:
可以延伸到很多应用场景,括号中括号大括号,不是中文字符的等等
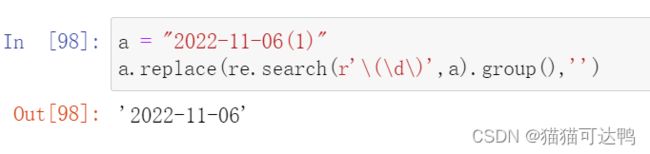
比如这里匹配()以外的内容: