ZooKeeper的应用场景(分布式锁、分布式队列)
7 分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要通过一些互斥手段来防止彼此之间的干扰,以保证一致性,在这种情况下,就需要使用分布式锁了。
在平时的实际项目开发中,我们往往很少会去在意分布式锁,而是依赖于关系型数据库固有的排他性来实现不同进程之间的互斥。这确实是一种非常简便且被广泛使用的分布式锁实现方式。然而有一个不争的事实是,目前绝大多数大型分布式系统的性能瓶颈都集中在数据库操作上。因此,如果上层业务再给数据库添加一些额外的锁,例如行锁、表锁甚至是繁重的事务处理,那么是不是会让数据库更加不堪重负呢?下面我们来看看使用ZooKeeper如何实现分布式锁,这里主要讲解排他锁和共享锁两类分布式锁。
排他锁
排他锁(Exclusive Locks,简称X锁),又称为写锁或独占锁,是一种基本的锁类型。
如果事务T1对数据对象O1加上了排他锁,那么在整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能再对这个数据对象进行任何类型的操作——直到T1释放了排他锁。
从上面讲解的排他锁的基本概念中,我们可以看到,排他锁的核心是如何保证当前有且仅有一个事务获得锁,并且锁被释放后,所有正在等待获取锁的事务都能够被通知到。
下面我们就来看看如何借助ZooKeeper实现排他锁。
定义锁
在通常的Java开发编程中,有两种常见的方式可以用来定义锁,分别是synchronized机制和JDK5提供的ReentrantLock。然而,在ZooKeeper中,没有类似于这样的API可以直接使用,而是通过ZooKeeper上的数据节点来表示一个锁,例如/exclusive_lock/lock节点就可以被定义为一个锁,如下图所示。
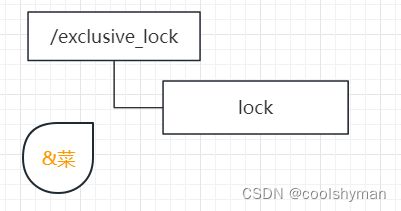
获取锁
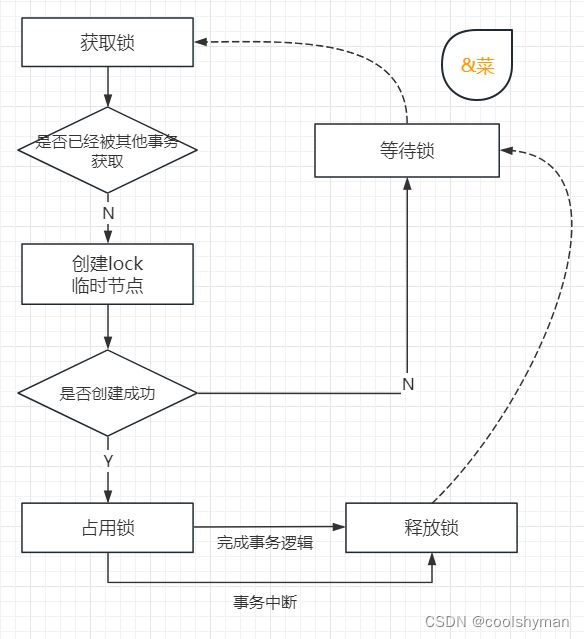
在需要获取排他锁时,所有的客户端都会试图通过调用create()接口,在/exclusive_lock 节点下创建临时子节点/exclusive_lock/lock。在前面几节中我们也介绍了,ZooKeeper会保证在所有的客户端中,最终只有一个客户端能够创建成功,那么就可以认为该客户端获取了锁。同时,所有没有获取到锁的客户端就需要到/exclusive_lock节点上注册一个子节点变更的Watcher监听,以便实时监听到lock节点的变更情况。
释放锁
在“定义锁”部分,我们已经提到,/exclusive_lock/lock是一个临时节点,因此在以下两种情况下,都有可能释放锁。
(1)当前获取锁的客户端机器发生宕机,那么ZooKeeper上的这个临时节点就会被移除。
(2)正常执行完业务逻辑后,客户端就会主动将自己创建的临时节点删除。
无论在什么情况下移除了lock 节点,ZooKeeper都会通知所有在/exclusive_lock节点上注册了子节点变更Watcher监听的客户端。这些客户端在接收到通知后,再次重新发起分布式锁获取,即重复“获取锁”过程。整个排他锁的获取和释放流程,可以用下图来表示。
共享锁
共享锁(Shared Locks,简称S锁),又称为读锁,同样是一种基本的锁类型。如果事务T1对数据对象O1,加上了共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁一直到该数据对象上的所有共享锁都被释放。
共享锁和排他锁最根本的区别在于,加上排他锁后,数据对象只对一个事务可见,而加上共享锁后,数据对所有事务都可见。下面我们就来看看如何借助ZooKeeper来实现共享锁。
定义锁
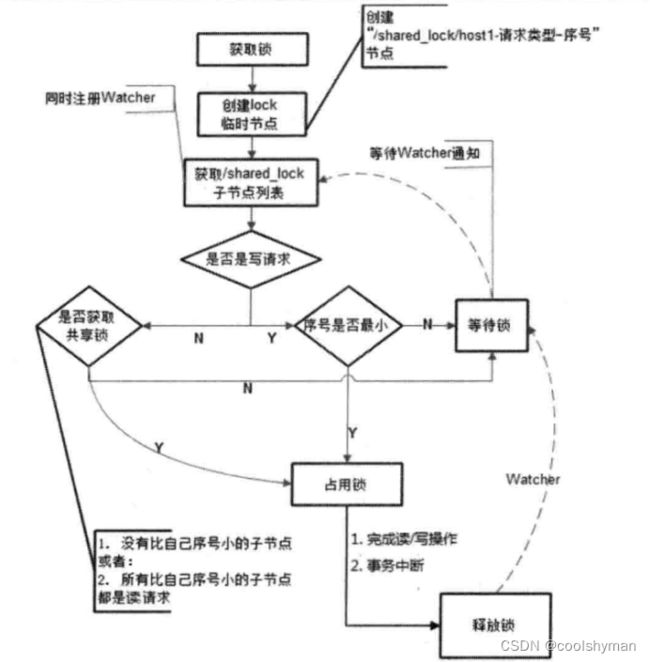
和排他锁一样,同样是通过ZooKeeper上的数据节点来表示一个锁,是一个类似于“/shared_lock/[Hostname]-请求类型-序号”的临时顺序节点,例如/shared_lock/192.168.0.1-0000000001,那么,这个节点就代表了一个共享锁。
获取锁
在需要获取共享锁时,所有客户端都会到/shared_lock这个节点下面创建一个临时顺序节点,如果当前是读请求,那么就创建例如/shared_lock/192. 168.0.1-0000000001的节点;如果是写请求,那么就创建例如/shared_lock/192.168.0. I-W-000000001的节点。
判断读写顺序
根据共享锁的定义,不同的事务都可以同时对同一个数据对象进行读取操作,而更新操作必须在当前没有任何事务进行读写操作的情况下进行。基于这个原则,我们来看看如何通过ZooKeeper的节点来确定分布式读写顺序,大致可以分为如下4个步骤。
(1)创建完节点后,获取/shared_lock节点下的所有子节点,并对该节点注册子节点变更的Watcher监听。
(2)确定自己的节点序号在所有子节点中的顺序。
(3)对于读请求:
如果没有比自己序号小的子节点,或是所有比自己序号小的子节点都是读请求,那么表明自己已经成功获取到了共享锁,同时开始执行读取逻辑。
如果比自己序号小的子节点中有写请求,那么就需要进入等待。
对于写请求:
如果自己不是序号最小的子节点,那么就需要进入等待。
(4)接收到Watcher通知后,重复步骤1。
释放锁
释放锁的逻辑和排他锁是一致的,这里不再赘述。整个共享锁的获取和释放流程,可以用下图来表示。
羊群效应
上面讲解的这个共享锁实现,大体上能够满足一般的分布式集群竞争锁的需求,并且性能都还可以一这里说的一般场景是指集群规模不是特别大,一般是在10台机器以内。
但是如果机器规模扩大之后,会有什么问题呢?我们着重来看上面“判断读写顺序”程的步骤3,结合下图给出的实例,看看实际运行中的情况。
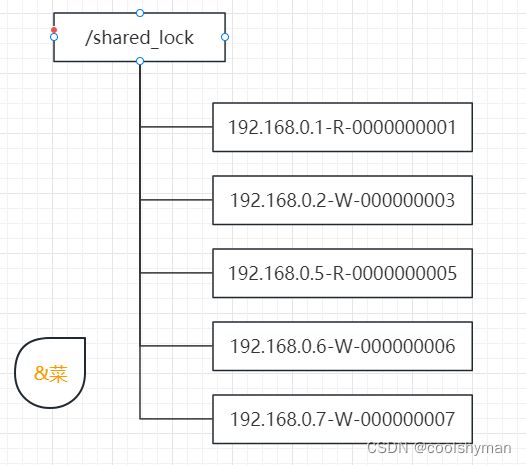
针对上图中的实际情况,我们看看会发生什么事情。
(1)192.168.0.1这台机器首先进行读操作,完成读操作后将节点/192.168.0.1-R-0000000001删除。
(2)余下的4台机器均收到了这个节点被移除的通知,然后重新从/shared_lock节点上获取一份新的子节点列表。
(3)每个机器判断自己的读写顺序。其中192.168.0.2这台机器检测到自己已经是序号最小的机器了,于是开始进行写操作,而余下的其他机器发现没有轮到自己进行读取或更新操作,于是继续等待。
(4)继续....
上面这个过程就是共享锁在实际运行中最主要的步骤了,我们着重看下上面步骤3中提
到的:“而余下的其他机器发现没有轮到自己进行读取或更新操作,于是继续等待。”很
明显,我们看到,192.168.0.1 这个客户端在移除自己的共享锁后,ZooKeeper 发送了子
节点变更Watcher通知给所有机器,然而这个通知除了给192.168.0.2这台机器产生实际
影响外,对于余下的其他所有机器都没有任何作用。
相信读者也已经意识到了,在这整个分布式锁的竞争过程中,大量的“Watcher通知”和“子节点列表获取”两个操作重复运行,并且绝大多数的运行结果都是判断出自己并非是序号最小的节点,从而继续等待下一次通知——这个看起来显然不怎么科学。客户端无端地接收到过多和自己并不相关的事件通知,如果在集群规模比较大的情况下,不仅会对ZooKeeper服务器造成巨大的性能影响和网络冲击,更为严重的是,如果同一时间有多个节点对应的客户端完成事务或是事务中断引起节点消失,ZooKeeper服务器就会在短时间内向其余客户端发送大量的事件通知一这就是所谓的羊群效应。
上面这个ZooKeeper分布式共享锁实现中出现羊群效应的根源在于,没有找准客户端真正的关注点。我们再来回顾一下上面的分布式锁竞争过程,它的核心逻辑在于:判断自己是否是所有子节点中序号最小的。于是,很容易可以联想到,每个节点对应的客户端只需要关注比自己序号小的那个相关节点的变更情况就可以了一而不需要关注全局的子列表变更情况。
改进后的分布式锁实现
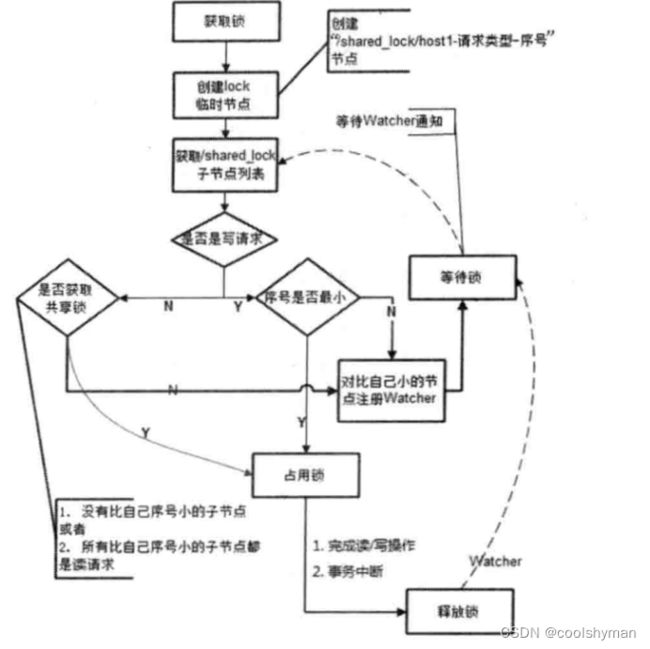
现在我们来看看如何改进上面的分布式锁实现。首先,我们需要肯定的一点是,上面提到的共享锁实现,从整体思路上来说完全正确。这里主要的改动在于:每个锁竞争者,只需要关注/shared.lock节点下序号比自己小的那个节点是否存在即可,具体实现如下。
(1)客户端调用create()方法创建一个类似于“/shared_ lock/[Hostname]请求类型-序号”的临时顺序节点。
(2)客户端调用getChildren()接口来获取所有已经创建的子节点列表,注意,这里不注册任何Watcher。
(3)如果无法获取共享锁,那么就调用exist()来对比自己小的那个节点注册Watcher。
注意,这里“比自己小的节点”只是一个笼统的说法,具体对于读请求和写请求不一样。
读请求:向比自己序号小的最后一个写请求节点注册Watcher监听。
写请求:向比自己序号小的最后一个节点注册Watcher 监听。
(4)等待Watcher通知,继续进入步骤2。
改进后的分布式锁流程如下图所示。
8 分布式队列
业界有不少分布式队列产品,不过绝大多数都是类似于ActiveMQ、Metamorphosis、Kafka和HornetQ等的消息中间件(或称为消息队列)。在本文中,我们主要介绍基于ZooKeeper实现的分布式队列。分布式队列,简单地讲分为两大类,一种是常规的先入先出队列,另一种则是要等到队列元素集聚之后才统一安排执行的Barrier模型。
FIFO:先入先出
FIFO (First Input First Output,先入先出)的算法思想,以其简单明了的特点,广泛应用于计算机科学的各个方面。而FIFO队列也是一种非常典型且应用广泛的按序执行的队列模型:先进入队列的请求操作先完成后,才会开始处理后面的请求。
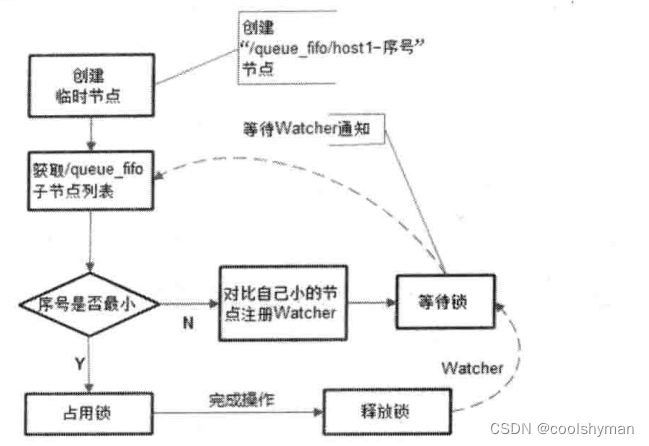
使用ZooKeeper实现FIFO队列,和前面共享锁的实现非常类似。FIFO 队列就类似于一个全写的共享锁模型,大体的设计思路其实非常简单:所有客户端都会到/queue_fifo这个节点下面创建一个临时顺序节点,例如/queue. fifo/192. 168.0.1-0000000001。
创建完节点之后,根据如下4个步骤来确定执行顺序。
(1)通过调用getChildren()接口来获取/queue_fifo节点下的所有子节点,即获取队列中所有的元素。
(2)确定自己的节点序号在所有子节点中的顺序。
(3)如果自己不是序号最小的子节点,那么就需要进入等待,同时向比自己序号小的最后一个节点注册Watcher监听。
(4)接收到Watcher通知后,重复步骤1。
整个FIFO队列的工作流程,可以用下图来表示。
Barrier:分布式屏障
Barrier原意是指障碍物、屏障,而在分布式系统中,特指系统之间的一个协调条件,规定了一个队列的元素必须都集聚后才能统一进行安排, 否则一直等待。这往往出现在那些大规模分布式并行计算的应用场景上:最终的合并计算需要基于很多并行计算的子结果来进行。这些队列其实是在FIFO 队列的基础上进行了增强,大致的设计思想如下:开始时,/queue_barrier节点是一个已经存在的默认节点,并且将其节点的数据内容赋值为一个数字n来代表Barrier 值,例如n=10表示只有当/queue_barrier节点下的子节点个数达到10后,才会打开Barrier。之后,所有的客户端都会到/queue_barrier节点下创建一个临时节点,例如/queue_barrier/192.168.0.1。
创建完节点之后,根据如下5个步骤来确定执行顺序。
(1)通过调用getData()接口获取/queue_barrier节点的数据内容:10。
(2)通过调用getChildren()接口获取/queue_barrier节点下的所有子节点,即获取队列中的所有元素,同时注册对子节点列表变更的Watcher监听。
(3)统计子节点的个数。
(4)如果子节点个数还不足10个,那么就需要进入等待。
(5)接收到Watcher通知后,重复步骤2。