浏览器渲染原理 - 输入url 回车后发生了什么
目录
- 渲染时间点
- 渲染流水线
-
- 1,解析(parse)HTML
-
- 1.1,DOM树
- 1.2,CSSOM树
- 1.3,解析时遇到 css 是怎么做的
- 1.4,解析时遇到 js 是怎么做的
- 2,样式计算 Recalculate style
- 3,布局 layout
- 4,分层 layer
- 5,绘制 paint
- 6,分块 tiling
- 7,光栅化 raster
- 8,画 draw
- 常见面试题
-
- 什么是 reflow
- 什么是 repaint
- 为什么 transform 效率高
在上一篇文章中,介绍了 浏览器的事件循环,其中提到了浏览器的进程模型。那浏览器是如何渲染页面的呢?
渲染时间点
浏览器会通过网络进程中的线程来通信,获取到 html 数据后生成渲染任务,发送给消息队列。
渲染主线程会执行渲染任务。整个渲染流程:把 html 字符串解析为像素点信息,再交给 GPU来渲染后在页面中展示。
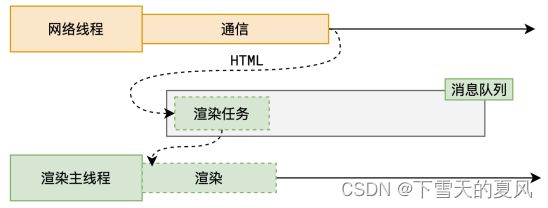
渲染流水线
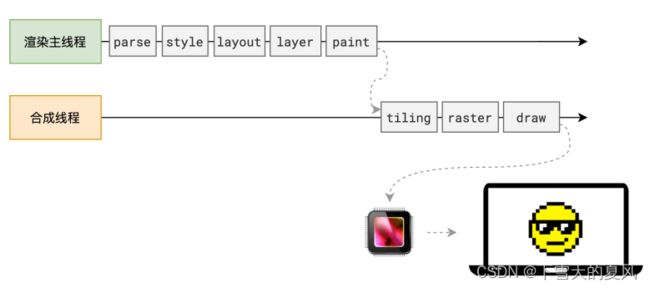
每个阶段都有明确的输入输出,上个阶段的输出会成为下个阶段的输入。形成一套完整的流水线。
1,解析(parse)HTML
会将 html 字符串解析为 2个树。因为字符串不好操作,对象更容易处理。
1.1,DOM树
也就是 document 对象。可以在控制台通过console.dir(document) 展示对象结构。
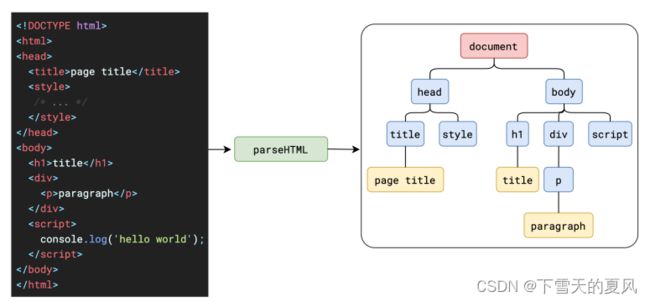
1.2,CSSOM树
包括: