语义分割之PSP-Net原理以及代码讲解
CVPR 2017 (IEEE Conference on Computer Vision and Pattern Recognition)
论文地址:Pyramid Scene Parsing Network
github地址:https://github.com/Lextal/pspnet-pytorch
PSP-Net可以说是语义分割当中比较经典的一个了,不仅有着较好的多类分割精度,同时实时性也ok(backbone在resnet18时在p100上可以跑到40ms左右,不算慢,当然现在很多优秀的语义分割算法都能做的比它好),整个网络结构相对也很简单,所以目前语义分割方向paper很喜欢在对比实验上加个pspnet。
一样的,下面简单介绍一下PSP-Net相关原理和代码结构。
作者主要贡献:提出了PSP_Module
在pspnet之前FCN这一条基于编码器-解码器的图像分割/语义分割本质其实是输入图像,然后通过CNN提取featuremap,再然后进行上采样到图像尺寸进行像素点级别的分类,这个也就是所谓的语义分割。FCN后一串的算法其实也就是在几个跳连接和特征融合层面做文章,比较经典的就是Unet,sppnet这些。因为是在像素点层面,所以这些算法其实并没有考虑上下文之间的关系,比如下图,
在水面上的大很可能是“boat”,而不是“car”。虽然“boat和“car”很像。FCN缺乏依据上下文推断的能力。
Confusion Categories: 许多标签之间存在关联,可以通过标签之间的关系弥补。下图第二行,把摩天大厦的一部分识别为建筑物,这应该只是其中一个,而不是二者。这可以通过类别之间的关系弥补。
Inconspicuous Classes:模型可能会忽略小的东西,而大的东西可能会超过FCN接收范围,从而导致不连续的预测。如下图第三行,枕头与被子材质一致,被识别成到一起了。为了提高不显眼东西的分割效果,应该注重小面积物体。
总结这些情况,许多问题出在FCN不能有效的处理场景之间的关系和全局信息。本论文提出了能够获取全局场景的深度网络PSPNet,能够融合合适的全局特征

简单介绍一下PSP-Net的网络结构:
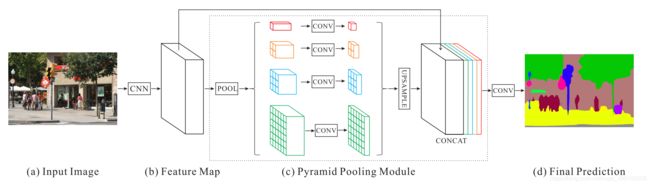
如图所示,PSPnet本质还是基于编码器解码器结构的一个网络,只不过相比于pspnet之前的一些语义分割算法,pspnet在下采样后的Featuremap后接了一个pyramid parsing module,通过这个模块上采样和级联层形成最终的特征表示,同时携带局部和全局上下文信息(then a pyramid parsing module is applied to harvest different sub-region representations, followed by upsampling and concatenation layers to form the final feature representation, which carries both local and global context information )
最后同样对上采样后的特征图进行像素点分类完成了整个分割过程。
由于相当多的博客在pyramid parsing module实现过程这里都是一笔带过,而这块又是整个pspnet最精髓的地方,本文这里重点根据代码来讲解一下pyramid parsing module的实现过程(基于pytorch),同时会从源头对整个pspnet实现过程伴随代码做讲解:
以下是PSPModule代码,下面对整个过程进行分析:
class PSPModule(nn.Module):
def __init__(self, features, out_features=1024, sizes=(1, 2, 3, 6)):
super().__init__()
self.stages = []
self.stages = nn.ModuleList([self._make_stage(features, size) for size in sizes])
self.bottleneck = nn.Conv2d(features * (len(sizes) + 1), out_features, kernel_size=1)
self.relu = nn.ReLU()
def _make_stage(self, features, size):
prior = nn.AdaptiveAvgPool2d(output_size=(size, size))
conv = nn.Conv2d(features, features, kernel_size=1, bias=False)
return nn.Sequential(prior, conv)
def forward(self, feats):
h, w = feats.size(2), feats.size(3)
priors = [F.upsample(input=stage(feats), size=(h, w), mode='bilinear') for stage in self.stages] + [feats]
bottle = self.bottleneck(torch.cat(priors, 1))
return self.relu(bottle)
priors = [F.upsample(input=stage(feats), size=(h, w), mode='bilinear') for stage in self.stages] + [feats]从网络结构可以很容易的看出在backbone提取feature之后,接入的就是pyramid pooling module模块,feature进入后通过这个列表解析进行pyramid pooling,具体的pooling用的是自适应平均池化(AdaptiveAvgPool2d),没用maxpooling的原因应该还是这个时候网络已经比较深了,包含的语义信息较多,注意这里用的二次线性插值做的上采样,上采样之后直接与原feature相加,完了cat之后进入bottleneck(其实就是个卷积层做特征融合)
self.bottleneck = nn.Conv2d(features * (len(sizes) + 1), out_features, kernel_size=1)pyramid parsing module出来之后就是上采样到图片分辨率然后做一个像素点类别预测,这里依然用的二次插值,没有用反卷积做解码器,每一次上采样都做了一次CBR。
class PSPUpsample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.PReLU()
)
def forward(self, x):
h, w = 2 * x.size(2), 2 * x.size(3)
p = F.upsample(input=x, size=(h, w), mode='bilinear')
return self.conv(p)对于最后的输出这里pspnet其实并不是和一般的分割网络以往输出W*H*class_number,然后简单用BCE对每个像素做一个分类,pspnet输出两个部分,一部分用来算分割loss,一部分用来算分类loss,最后加权求和。
class PSPNet(nn.Module):
def __init__(self, n_classes=18, sizes=(1, 2, 3, 6), psp_size=2048, deep_features_size=1024, backend='resnet34',
pretrained=True):
super().__init__()
self.feats = getattr(extractors, backend)(pretrained)
self.psp = PSPModule(psp_size, 1024, sizes)
self.drop_1 = nn.Dropout2d(p=0.3)
self.up_1 = PSPUpsample(1024, 256)
self.up_2 = PSPUpsample(256, 64)
self.up_3 = PSPUpsample(64, 64)
self.drop_2 = nn.Dropout2d(p=0.15)
self.final = nn.Sequential(
nn.Conv2d(64, n_classes, kernel_size=1),
nn.LogSoftmax()
)
self.classifier = nn.Sequential(
nn.Linear(deep_features_size, 256),
nn.ReLU(),
nn.Linear(256, n_classes)
)
def forward(self, x):
f, class_f = self.feats(x)
p = self.psp(f)
p = self.drop_1(p)
p = self.up_1(p)
p = self.drop_2(p)
p = self.up_2(p)
p = self.drop_2(p)
p = self.up_3(p)
p = self.drop_2(p)
auxiliary = F.adaptive_max_pool2d(input=class_f, output_size=(1, 1)).view(-1, class_f.size(1))
return self.final(p), self.classifier(auxiliary),如上段代码所示,最后self.final(p)用于算分割loss,而self.classifier(auxiliary)是backbone最后跟了一个FC-relu-FC,resize到class_number然后算分类精度。
损失函数:
pspnet采用了两种损失函数,分别是分类损失函数和分割损失函数,损失函数很简单,代码如下:
seg_criterion = nn.NLLLoss2d(weight=class_weights)
cls_criterion = nn.BCEWithLogitsLoss(weight=class_weights)
以上就是pspnet一个网络结构介绍,核心亮点是构造一个类似FPN的结构提取更多的语义信息,pyramid pooling这一个方法在后面被各种语义分割网络例如Fastscnn用到,虽然实时性可能是个缺点,但是分割精度在当时确实做到了一个很高的水平。