MYSQL基本命令和操作
作者 : D. Star.
专栏 : JAVA
今日提问 : 你好,我的朋友,在你的人生途中,会面临很多选择,不管选什么样的结果,我们都多少会有些后悔。如果是你,你会选择爱你的,还是懂你的?

MYSQL
- 一、数据库分类(了解):
-
- 1. 关系型数据库:
- 2. 非关系型数据库:
- 二、数据库中的基本概念:
-
- 1. 数据库:
- 2. 数据表:
- 3. 列、行:
- 4. 主键:
- 5. 外键:
- 三、对于数据==库==的基本操作:
-
- 1. 创建数据库(create)
- 2. 删除数据库 (drop)
- 3. 查看所有的数据库(已有)(show):
- 四、对于数据==表==的基本操作:
-
- 1. 增(create)
- 2. 删 (drop)
- 3. 查看表名(show/desc)
- 4. 改(alter)
-
- 4.1. 删除列
- 4.2. 增加列
- 五、对数据表数据的基本操作:
-
- 1. ==首先==要对该数据表的数据库进行==选中==操作(use)
- 2. 增(insert)
- 3. 删(delete)
- 4. 查(select)
- 5. 改(update)
- 六、字符集
- 七、对表数据的进阶操作
-
- 1. as的使用方法
- 2. distinct的使用方法
- 3. order by 的使用方法
- 4. where 的使用方法
-
- 4.1. like 模糊匹配
- 4.2. between ... and ...
- 4.3. and / or
- 4.4. in ( ... )
- 4.5. <==> 的使用方法
- 5. limit 的使用方法
- 5.1. group by(where和having)
- 八、数据库约束
-
- 1. not null
- 2. unique
- 3. default
- 4. primary key
- 5. foreign key
- 九、聚合函数
-
- 1. count(...)
- 2. sum(...)
- 3. avg(...)
- 十、 联合查询
-
- 1. 多表查询
- 2. 内外连接
-
- 2.1. 内连接(用的最多)
- 2.2. 左外连接
- 2.3. 右外连接
- 3. 自连接
- 4. 子查询
- 5. 合并查询
-
- 5.1. union
- 6. 索引
-
- 6.1. 查看索引
- 6.2. 创建索引
- 6.3. 删除索引
一、数据库分类(了解):
1. 关系型数据库:
Oracle(最好),Mysql(最广泛–免费),SQL Server(好用不火),SQLite(轻量级)
2. 非关系型数据库:
MongoDB,Redis,HBase
二、数据库中的基本概念:
1. 数据库:
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
2. 数据表:
表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
3. 列、行:
一列(数据元素) :包含了相同的数据。
一行(元组/记录):是一组相关的数据。
4. 主键:
主键是唯一的。一个数据表中只能包含一个主键。
5. 外键:
外键用于关联两个表。
三、对于数据库的基本操作:
1. 创建数据库(create)
create database 表名(列名 类型,…);
例如:创建一个名为student的数据库
//eg:创建一个名为student的数据库
create database student;
2. 删除数据库 (drop)
drop database 表名;
例如:删除一个名为student的数据库
//eg:删除一个名为student的数据库
drop database student;
3. 查看所有的数据库(已有)(show):
show databases;
show databases;//显示所有数据库
四、对于数据表的基本操作:
1. 增(create)
create table 表名(列名 类型,…);
例如:创建一个名为stu的数据表(id,姓名,成绩);
//eg:创建一个名为student的数据表(id,姓名,成绩)
create table student(id int,name varchar(20),grade decimal(3,1));
2. 删 (drop)
drop table 表名;
例如:删除一个名为student的数据表;
//eg:删除一个名为student的数据表
drop table stu;
3. 查看表名(show/desc)
show tables;
desc 【表名】;
例如:展示stu数据库里的所有表名:
//eg:展示stu数据库里的所有表名:
show tables;
例如:查看books表的结构
desc books;
4. 改(alter)
4.1. 删除列
alter table 【表名】 drop【列名】;
例如:删除student表中的grade列
//eg:删除student表中的grade列
alter table student drop grade;
4.2. 增加列
alter table 【表名】 add【列名】 【类型】;
例如:增加student表中的grade列
//eg:增加student表中的grade列
alter table student add grade decimal(3,1);
- 修改列的名字
alter table【表名】 change【列名】【新名】 ;
例如:将student表中的grade改为成绩
//eg:将student表中的grade改为成绩
alter table student change grade '成绩';
- 创建索引
alter table 【表名】 add index 索引名(列名);
例如:创建student表中的名字为索引
//eg:创建student表中的名字为索引
alter table student add index index_name(name);
- 删除索引
alter table 【表名】 drop index 索引名(列名);
例如:删除student表中的名字为索引
//eg:删除student表中的名字为索引
alter table student drop index index_name(name);
- 修改表名
alter table 【表名】 rename 【新表名】;
例如:将student表的表名改成students
//eg:将student表的表名改成students
alter table student rename students;
五、对数据表数据的基本操作:
1. 首先要对该数据表的数据库进行选中操作(use)
(否则无法进行该数据库的操作)
use 数据库名;
例如:假设这里的数据库名位stu;
//eg:假设这里的数据库名位stu;
use stu;
2. 增(insert)
- 直接增加一条/多条记录 。
insert into 【表名】 values(…);
insert into 【表名】 values(…),(…),(…);
例如:在students表中插入(1,‘王五’,85.5);
注 : varchar类型可以是单引号/双引号
//eg:在students表中插入(1,'王五',85.5);
//法一:
insert into students values(1,'王五',85.5);
insert into students values(1,"王五",85.5);
//法二:
insert into students(name,id,grade) values('王五',1,85.5);
- 插入特定数据(select挑选出来的)。
insert into stutends(name,grade) (select name,grade from students where id = 1);
例如:将students表中id为1的(姓名,成绩)插入到students表中新的(姓名成绩)
eg:将students表中id为1的(姓名,成绩)插入到students表中新的(姓名成绩)
insert into stutends(name,grade) (select name,grade from students where id = 1);
3. 删(delete)
- 删除表中的一条或者多条记录。
delete from 【表名】 where 【条件】;
delete from 【表名】;
//(删除的是符合该条件的一条条记录)
//eg:删除成绩为0的记录
delete from students where grade = 0;
//(删除全部数据)
delete from students;
4. 查(select)
- 查询全部列。
select * from 【表名】 where 【条件】;
例如:查询students中成绩大于50的全部学生信息
//eg:查询students中成绩大于50的全部学生信息
select * from students where grade>50;
- 查询个别列。
select 【列名】 from 【表名】where 【条件】;
例如:查询students中成绩大于50的学生姓名
//eg:查询students中成绩大于50的学生姓名
select name from students where grade>50;
5. 改(update)
- 根据筛选条件,将原字段改为新内容。
update 【表名】set 【字段名】=【新内容】 where 【条件】;
例如:将students表中序号为1的学生的成绩改为97;
//eg:将students表中序号为1的学生的成绩改为97;
update students set grade = 97 where id = 1;
六、字符集
提问:一个汉字在JAVA(utf8)中占几个字节?
答:3bit/字。
七、对表数据的进阶操作
(提前)结论:所有的查询条件产生的只是一个结果集,不会影响内存里的数据
1. as的使用方法
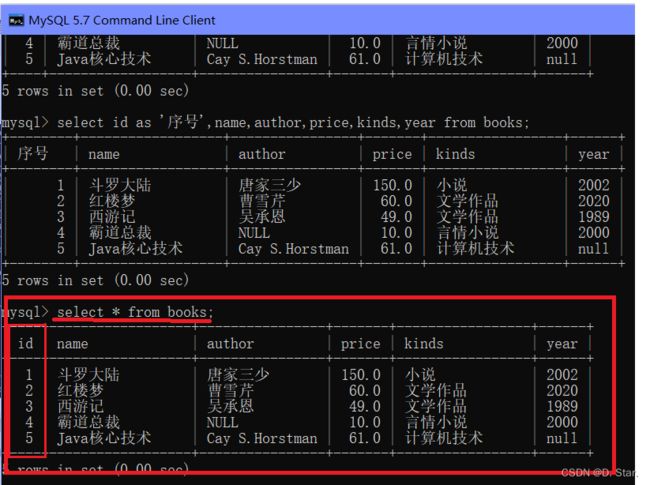
含义 : 重命名(表面的,不影响内存里的数据)[下面有证明图片]
注意:只针对一个字段重命名
公式①:select 【字段 as 【重命名】,…】 from 【表名】
公式② select 【… , 字段】 as 【重命名】 from 【表名】
例如:将books中的id显示为序号
//eg:将books中的id显示为序号
//法一:
select id as '序号',name,author,price,kinds,year from books;
//法二:
select name,author,price,kinds,year,id as '序号' from books;
图片展示

验证: 内存里的数据没变(即id没变)
2. distinct的使用方法
含义 : 去重(将字段中重复的部分去掉)
并且只能放在字段前面
例如 : 显示books中的year(去重)
//eg : 显示books中的year(去重)
select distinct year from books;
图示:
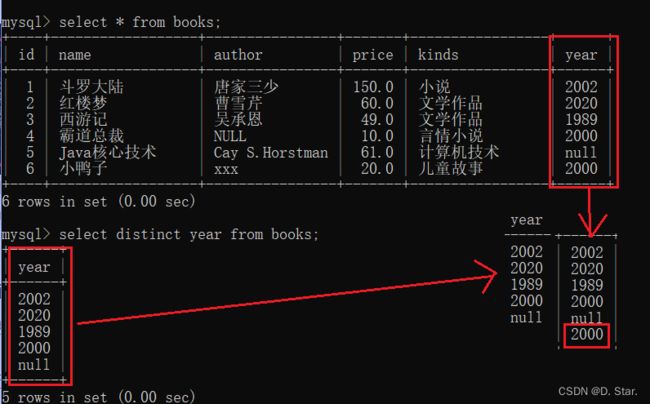
如果distinct后面接了很多的字段,那就将这些字段作为一组字段,并且显示不重复的组字段.
3. order by 的使用方法
根据特定条件/字段排序
默认是升序[asc]
也可以在后面加上desc(降序)
注意!!!可识别别名
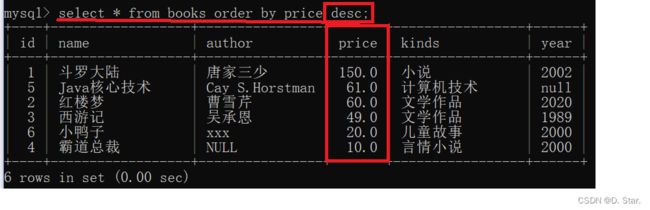
例如 : 在books表中,按照price的高低排序
//eg: 在books表中,按照price的高低排序
select * from books order by price;
[默认升序]

[降序]
4. where 的使用方法
4.1. like 模糊匹配
% : 代表0个字符或者N个字符
格式: like ‘%xxx’
_ : 代表一个字符
格式: like ‘_xxx’
注意: like前面可以加not 表示否定.
注意: like 后面一定要加 ’ ’ 或者 " " ;
例如:在books表中,找到唐xxx的author名
4.2. between … and …
表示的是一个范围区间,前闭后闭
between前面可以加not
例如: 在books表中,找出价格在[50,500]之间的书
//eg: 在books表中,找出价格在[50,500]之间的书
select * from books where price between 50 and 500;

4.3. and / or
作为条件: 且,或
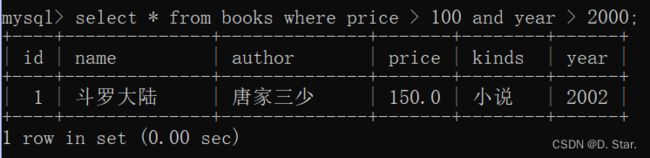
例如: 在books表中,找出价格大于100并且(可换成或者)在2000以后发行的书
//eg:在books表中,找出价格大于100并且在2000以后发行的书
select * from books where price > 100 and year > 2000;
4.4. in ( … )
作为数值挑选项
例如: 在books表中,找出价格是50或者500之间的书
//eg:在books表中,找出价格是50或者500之间的书
select * from books where price in(50,500);

4.5. <==> 的使用方法
<==> : 严格比较两个NULL值是否相等
例如: 找出books表中,author为NULL的信息;
select * from books where author <=> null;

5. limit 的使用方法
limit + 数字 : 分页查询(默认从下表为0的数据开始展示)
offset + 数字 : 声明从哪一条开始查询(默认从0开始)
例如: 显示books表中的3条数据;
//eg:显示books表中的3条数据;
select * from books limit 3;

例如: 显示books表中的3条数据并从第二条数据开始(即下表为1的数据);
//eg:显示books表中的3条数据并从第二条数据开始(即下表为1的数据);
select * from books limit 3 offset 1;

5.1. group by(where和having)
作用 : 分组,将列值相同的分到一组
注意 : 分组后 , 取(显示)的是第一行数据
例如:显示出一班和二班的总成绩是多少?
select class,sum(score) from student group by class;

分组前筛选用where
例如 : 通过班级分组显示分数>60的数据
select * from student where score>60 group by class;
注意!!!where无法识别select 到 from 之间的别名,但是可以识别from后的

分组后筛选用having
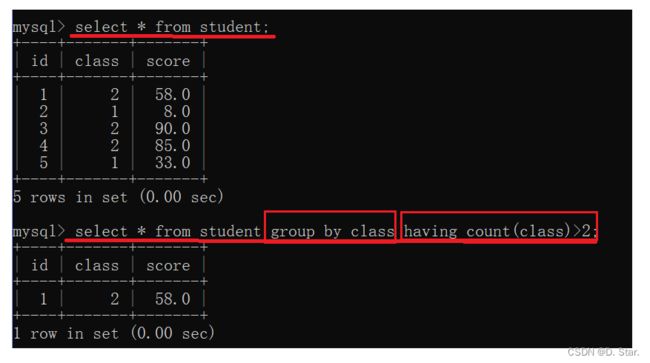
例如 : 通过班级分组显示班级出现超过2次的数据.
select * from student group by class having count(class)>2;
注意!!!having前后最好字段一致
八、数据库约束
目的: 为了提高效率和准确性
适用于在创建表的时候进行添加约束条件
1. not null
意思: 不为空
数据库含义: 必填
例如: 创建一个book表,设置其中的书名(name)字段为不为空
create table book(
id int,
name varchar(20) not null,
author varchar(20));
在已创建好的表中添加 not null约束条件
alter table 表名 modify 字段 类型
例如:alter table student modify age int not null;
在已创建好的表中删除 not null约束条件
alter table 表名 modify 字段 类型
例如:alter table student modify age int null;
2. unique
意思: 唯一的
数据库含义: 唯一的,不可重复
例如: 创建一个book表,设置其中的id字段为唯一
create table book(
id int unique,
name varchar(20) ,
author varchar(20) );
在已创建好的表中添加unique约束条件
alter table 表名 add unique(字段) ;
在已创建好的表中删除unique约束条件
alter table 表名 drop index 字段;
3. default
意思: 默认
数据库含义: 如果表中未填写,系统将会把默认值填入
例如: 创建一个book表,设置其中的作者字段为默认"未知"
create table book(
id int,
name varchar(20) ,
author varchar(20) default "未知");
在已创建好的表中修改default约束
alter table 【表名】alter 【字段】set default ‘xxx’ ;
在已创建好的表中删除default约束
alter table 【表名】alter 【字段】drop default ;
4. primary key
意思: 主码
数据库含义: 唯一标识关系
是not null 和 unique 的总和
create table student(
sid int not null primary key,
gid int not null ,
name varchar(20),
age int,
grade int);
在已创建好的表中修改 primary key约束
alter table 表名 add primary key(字段);
在已创建好的表中删除 primary key约束
alter table 表名 dop primary key;
5. foreign key
意思: 外码
数据库含义: 唯一标识关系
create table student(
sid int not null primary key,
gid int not null foreign key references 表名(字段),
name varchar(20),
age int,
grade int);
在已创建好的表中修改 foreign key约束
alter able 表名1 add foreign key(字段) references 表名2(字段名);
在已创建好的表中删除 foreign key约束
alter table 表名 drop foreign key 外键名;
注意!!!查看外键名: show create table 表名 ;

九、聚合函数
1. count(…)
计算()出现的次数
例如:计算student表中,班级2的同学有几个
//eg::计算student表中,班级2的同学有几个
select class, count(class) from student group by class;

2. sum(…)
求和
例如: 求各班同学的总成绩
//例如: 求各班同学的总成绩
select class,sum(score) as sum from student group by class;

3. avg(…)
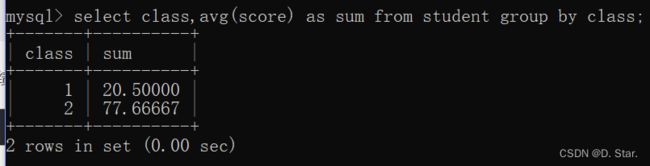
求平均数
例如 : 求各班同学成绩的平均分
//例如 : 求各班同学成绩的平均分
select class,avg(score) as sum from student group by class;
十、 联合查询
两表或者多表联合查询
1. 多表查询
//格式1:(两/多表连接',')
select 列名 from 表名1,表名2 where (将表1的字段与表2的相连接)
//格式2:(两表连接join)
select 列名 from 表名1 join 表2 on (字段连接)
//格式3:(多表连接join)
select 列名 from 表名1 join 表2 on (字段连接) join 表3 on 条件
2. 内外连接
2.1. 内连接(用的最多)
只显示共有部分
公式 : 就是上面的两表连接操作
select 列名 from 表名1 join 表2 on (字段连接)

2.2. 左外连接
以左侧表为主,左侧表的内容全部显示,如果右侧没有对应的,补null
格式 : select 列名 from 表名1 left join 表2 on (字段连接)

2.3. 右外连接
以右侧表为主,右侧表的内容全部显示,如果左侧没有对应的,补null
格式 : select 列名 from 表名1 right join 表2 on (字段连接)

3. 自连接
同一张表
例如:查询同一张表里同时选修了课程1和课程2的学生信息
select * from stu_class as s1,stu_class as s2 where s1.id = s2.id and s1.class = s2.class ;
4. 子查询
//格式:
select * from 表1 where id = (select id from 表2 where 条件);
5. 合并查询
5.1. union
可用于多个表的查询结果合并
注意 : union all 不会自动去重
== union 会自动去重==
//格式:
select * from 表 where 条件 union select * from 表 where 条件;
6. 索引
目的: 提高查找速度
消耗 : 需要额外的空间代价来保存索引数据, 若数据过于庞大,存在危险
6.1. 查看索引
show index from 表名;
6.2. 创建索引
create index 索引名 on 表名(列名);
若后建索引存在危险,最好是建表时就设计好表的结构
做法 : 加上主键或者unique,这些都是自带索引的约束条件
6.3. 删除索引
drop index 索引名 on 表名;
注意 : 所有的删除都存在风险
感谢家人的阅读,若有不准确的地方 欢迎在评论区指正!