Java学习笔记——I/O流
文章目录
- I/O流
-
- I/O流简介(分类与体系结构)
- File类
-
- 构造File类对象
- File类对象可以执行的操作
- IO详解
-
- 节点(文件)流
-
- 节点(文件)流(字符读入读出)
- 节点(文件)流(字节读入读出)
- 缓冲流
- 小结
I/O流
I/O流简介(分类与体系结构)
I/O流是java中负责文件输入输出的模块,用于处理设备之间的数据传输,例如读/写文件,网络通信等。通常,我们在java中写程序时,是站在内存的角度,硬盘中的各种程序读入内存的过程是input,从内存中写入硬盘的过程是output。
java的IO流中有各种各样的流,根据不同规则可以分成不同的流,具体如下
- 按操作数据单位分:
- 字节流(8bit):多用于非文本类数据.jpg,.mp3等
- 字符流(16bit):多用于文本类数据.txt等
- 按数据流的流向不同:输入流,输出流
- 按流的角色的不同:
- 节点流:直接作用于文件的流
- 处理流:作用于已存在流的基础上的附加流
各种流的示意图
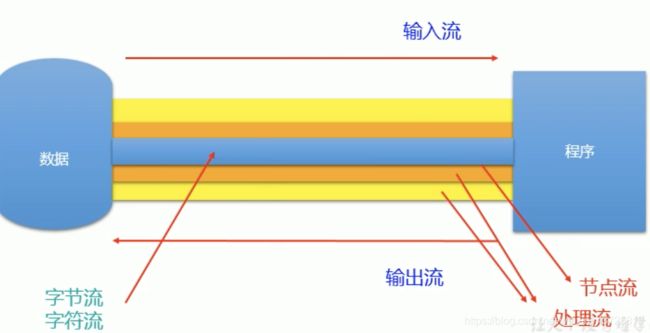
同时考虑操作数据单位和数据流的流向,可以得到如下表格
| 抽象基类 | 字节流 | 字符流 |
|---|---|---|
| 输入流 | InputStream | Reader |
| 输出流 | OutputStream | Write |
上述表格的四个类也是I/O流中最常用的四种类型,下民表格中是java中所有的输入输出流(都是四个抽象基类的子类)
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 祖字符输出流 |
|---|---|---|---|---|
| 抽象基类(重要) | InputStream |
OutpuStream |
Reader |
Writer |
| 访问文件(重要) | FileInputStream |
FileOutStream |
FileReader |
FileWriter |
| 访问数组 | ByteArrayInputStream |
ByteArrayOutputStream |
CharArrayReader |
CharArrayWriter |
| 访问管道 | PipedInputStream |
PipedOutputStream |
PipedReader |
PipedWriter |
| 访问字符串 | StringReader |
StringWriter |
||
| 缓冲流(重要) | BufferedInputStream |
BufferedOutputStream |
BufferedReader |
BufferedWriter |
| 转换流(重要) | InputStreamReader |
OutputStreamWriter |
||
| 对象流(重要) | ObjectInputStream |
ObjectOutputStream |
||
FileterInputStream |
FilterOutputStream |
FilterReader |
FilterWriter |
|
| 打印流 | PrintWriter |
|||
| 推回输入流 | PushbackInputStream |
PushbackReader |
||
| 特殊流 | DataInputStream |
DataOutputStream |
注意:除了访问文件的四个是节点流外,其他都是处理流。其中有五类是相对重要的类型。
在讲解IO流之前,不得不提的一个类是File文件类。
File类
构造File类对象
在java中,万事万物皆对象。对于电脑上的任意一个文件或文件夹,java都可以将其封装称为一个对象,以供响应的IO流使用。这里进行封装的类就是File类。
那该如何将本地文件封装称为File类对象呢?答:java中提供了如下三种方法:
方法一:使用路径名File(String pathname)
File file1 = new File("hello.txt");//相对于当前module下的路径
File file2 = new File("D:\\myJavaCode\\hello.jpg"); //绝对路径
方法二:使用父目录+子目录的格式File(String parent, String child)
File file3 = new File("D:\\myJavaCode","hello") //寻找 D盘 下的 myJavaCode 目录下的 hello 目录
方法三:使用文件+文件名的格式File(File parent, String child)
File file4 = new File(file3,"hello.txt"); // 寻找 file3 对应目录下的 hello.txt文件
由此可见,封装的关键在于获取正确的路径名,定位到目标文件。三种封装方法的区别仅仅是获取文件路径方式的不同。
File类对象可以执行的操作
当获取类FIle类对象后,就相当于将该文件放入了JVM内存中。于是就可以通过File提供的方法,获取关于该对象的基本信息。
获取文件基本信息的方法:
public String getAbsolutePath():获取绝对路径public String:获取路径public String:获取名称public String:获取上层文件目录路径,若无返回nullpublic long length():获取文件长度(字节数)public long lastModified():获取最后一次修改的时间
public String[] list():获取指定目录下所有文件或文件目录的名称数组public File[] listFiles():获取指定目录下所有文件或文件目录的File数组
判断性的方法:
-
public boolean renameTo(File dest):把文件重命名为指定的文件路径-
以
file1.renameTo(file2)为例,要求file1存在而file2不存在File file1 = new File("hello.txt"); File file2 = new File("D:\\io\\hi.txt"); boolean renameTo = file1.renameTo(file2); System.out.println(renameTo);// 只有当file2不是硬盘中存在的文件时才能返回ture
-
-
public boolean isDirectory():判断是否是文件目录 -
public boolean isFile():判断是否是文件 -
public boolean exists():判断是否存在 -
public boolean canRead():判断是否可读 -
public boolean canWrite():判断是否可写 -
public boolean isHidden():判断是否隐藏
创建于删除功能的方法(硬盘中)
public boolean createNerFile():创建文件。存在则不创建,返回false。public boolean mkdir():创建文件目录,如果目录存在就不创建,返回falsepublic boolean mkdirs():创建文件目录。如果上层文件目录不存在,一并创建public boolean delete():删除文件或文件夹,不走回收站。如果删除文件夹,要求文件夹中没有文件或文件目录
IO详解
节点(文件)流
节点(文件)流(字符读入读出)
节点(文件)流使用字符读入读出主要是针对于文本类型的数据
数据读入
读文件操作
public static void main(String[] args) {
FileReader reader = null;
try {
// 1.获取文件类对象
File file = new File("JDBC1/src/main/java/hello.txt");
// 2.提供FileReader对象,用于数据读入
reader = new FileReader(file);
// 3.读取数据
int i;
while((i=reader.read())!=-1){ //返回读入的一个字符,如果达到文件末尾,返回-1
System.out.print((char) i); //hello
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4.流资源关闭
try {
if(reader!+null)
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// txt 中内容为 hello
上述代码有几个注意要点:
- Read()方法:返回读入的自负,如果达到文件末尾,返回-1
- 异常处理,为了保证流资源一定关闭操作,需要使用try-catch-finally
- 读入的文件一定要存在,否则就会报错
使用带buffer的读文件操作
try之外的代码没有改动,只有try{}之内的diamanté稍有变化
try {
File file = new File("JDBC1/src/main/java/hello.txt");
reader = new FileReader(file);
char[] cbuf = new char[5];
int len;
while((len=reader.read(cbuf)!=-1){ //返回读入的一个祖父,如果达到文件末尾,返回-1
for(int i = 0;i<len;i++) //读入几个,遍历几个
System.out.print((char) i); //hello
}
上述方法相当于构建了一个大小为5个字符的缓冲区,每次从文件中读入5个字节。
这里最重要的地方就是第6行读入数据的大小,由于使用buffer后,新读入的内容如果无法占满buffer,就会出现一部分保留上一次读入的数据的情况。因此,应当设计为——读入几个,遍历几个。
数据写出
写入写出操作流程相似,只需要修改修改try{}内部代码即可
try {
//1.提供一个File类对象,指明写出到的文件
File file = new File("JDBC1/src/main/java/hello1.txt");
//2.提供一个FiletWriter对象,用于数据的写出
writer = new FileWriter(file,true);//可以追加原有文件
//3.写出的操作
writer.write("hello!!");
}
说明:
- 输出操作,对应的File可以不存在,如果不存在,在输出过程中,会自动创建该文件。
- 如果存在:
- 如果流使用的构造器是
FileWriter(file,false)/FileWriter(file):对原有文件覆盖 - 如果流使用的构造器是
FileWriter(file,true):不会对原有文件覆盖,而是在原有文件基础上追加内容
- 如果流使用的构造器是
节点(文件)流(字节读入读出)
节点(文件)流使用字节读入读出主要是针对于非文本类型的数据,其使用方法和字符读入读出的流程完全相同。唯一不同的地方在于,使用的类是FileInputOutputStream和FileOutputOutputStream和
try {
File file = new File("JDBC1/src/main/java/hello.jpg");
fis = new FileInputStream(file);
char[] cbuf = new char[5];
int len;
while((len=fis.read(cbuf)!=-1){ //返回读入的一个祖父,如果达到文件末尾,返回-1
for(int i = 0;i<len;i++) //读入几个,遍历几个
System.out.print((char) i); //hello
}
说明:在实际开发中,利用基本的文件输入输出流效率相对较低,一般不使用
缓冲流
使用缓冲流的能够加速文件读写,更加方便流的读取。这是因为缓冲流类内部提供流缓冲区,能够加快数据存取的速度。
缓冲流的读入与写出流程如下
public static void main(String[] args) {
FileInputStream fis = null;
FIleOutputStream fos =null;
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
// 1.造文件
File scrFile = new File("JDBC1/src/main/java/hello.jpg");
File desFile = new File("JDBC1/src/main/java/hello.jpg");
// 2.造流
// 2.1 造节点流
FileInputStream fis = new FileInputStream(srcFile);
FileOutputStream fos = new FileOutputStream(desFile);
// 2.2 造缓冲流
bis = new BufferedInputStream(fis);
bos = new BufferedOutputStream(fos);
// 3.复制的细节:读取写入
byte[] buffer = new byte[10];
int len;
while((len=bis.read(buffer))!=-1){
bos.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4.关闭资源
try {
// 要求:先关闭外层的流,再关闭内层的流,先关闭输出流,再关闭输入流
bos.close();
bis.close();
fos.close();
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
说明:
- 构建时先构建节点流再构建缓冲流;
- 关闭时先关闭外层流,再关闭内层流;先关闭输出流,再关闭输入流。
小结
Java的I/O流相对简单,套路也很固定,只要掌握了一种流的读入读出就能够很快迁移应用至其他流的读入读出中。因此,这一部分只需要了解一下I/O流的分类与体系架构,大致了解一下各个流的功能,在需要使用的时候,套用模板即可。