Apache Durid(入门 安装 数据摄取 查询 集成SpringBoot)
Apache Durid
- Apache Durid
-
- 1. Durid概述
-
- 1.1 为什么使用
-
- 1.1.1 云原生数据库
- 1.1.2 轻松集成
- 1.1.3 超高性能
- 1.1.4 工作流
- 1.1.5 多种部署方式
- 1.2 使用场景
-
- 1.2.1 常见的使用场景
-
- 1.2.1.1 用户活动和行为
- 1.2.1.2 网络流
- 1.2.1.3 数字营销
- 1.2.1.4 应用性能管理
- 1.2.1.5 物联网和设备指标
- 1.2.1.6 OLAP和商业智能
- 1.2.2 适合的场景
- 1.2.3 不适合的场景
- 2. Durid是什么
-
- 2.1 主要特性
- 2.2 和其他技术对比
- 2.3 数据摄入
- 2.4 数据存储
- 2.5 查询
- 3. 安装部署
-
- 3.1 环境介绍
- 3.2 安装方式
-
- 3.2.1 源代码编译
- 3.2.2 官网下载
- 3.2.3 Imply组合套件
- 3.3 单机配置参考
-
- 3.3.1 Nano-Quickstart
- 3.3.2 微型快速入门
- 3.3.3 小型
- 3.3.4 中型
- 3.3.5 大型
- 3.3.6 超大型
- 3.4 单机版安装
-
- 3.4.1 软件要求
- 3.4.2 硬件要求
- 3.5 imply方式安装
-
- 3.5.1 安装perl
- 3.5.2 关闭防火墙
- 3.5.3 安装JDK
-
- 3.5.3.1 下载JDK
- 3.5.4 安装imply
-
- 3.5.4.1 登录Imply官网
- 4. 数据摄取
-
- 4.1 加载本地文件
-
- 4.1.1.1 数据选择
- 4.1.1.2 演示数据查看
- 4.1.1.3 选择数据源
- 4.1.1.4 加载数据
- 4.1.2 数据源规范配置
-
- 4.1.2.1 设置时间列
- 4.1.2.2 设置转换器
- 4.1.2.3 设置过滤器
- 4.1.2.4 配置schema
- 4.1.2.5 配置Partition
- 4.1.3 提交任务
- 4.2 kafka加载流式数据
-
- 4.2.1 安装Kafka
-
- 4.2.1.1 编辑资源清单
- 4.2.4 发送数据到kafka
- # 4.2.5 数据选择
- 4.2.8 清理数据
- 5. 数据查询
-
- 5.1 准备工作
-
- 5.1.1 导入大量数据
- 5.2 原生查询
-
- 5.2.1 查询语法
- 5.3 查询类型
-
- 5.4.1 时间序列查询
-
- 查询属性
- 5.4.2 TopN查询
- 5.4.5 分组查询
- 5.5 查询组件
-
- 5.5.1 Filter
- 5.5.2聚合器
- 5.6 Druid SQL
-
- 5.6.1基本查询
-
- 5.6.1.1查询数据总条数
- 5.6.2 聚合功能
- 5.7 客户端API
-
- 5.7.1 引入Pom依赖
Apache Durid

1. Durid概述
Apache Druid是一个集时间序列数据库、数据仓库和全文检索系统特点于一体的分析性数据平台。本文将带你简单了解Druid的特性,使用场景,技术特点和架构。这将有助于你选型数据存储方案,深入了解Druid存储,深入了解时间序列存储等。
Apache Druid是一个高性能的实时分析型数据库。
1.1 为什么使用
1.1.1 云原生数据库
一个现代化的云原生,流原生,分析型数据库
Druid是为快速查询和快速摄入数据的工作流而设计的。Druid强在有强大的UI,运行时可操作查询,和高性能并发处理。Druid可以被视为一个满足多样化用户场景的数据仓库的开源替代品。
1.1.2 轻松集成
轻松与现有的数据管道集成
Druid可以从消息总线流式获取数据(如Kafka,Amazon Kinesis),或从数据湖批量加载文件(如HDFS,Amazon S3和其他同类数据源)。
1.1.3 超高性能
比传统方案快100倍的性能
- Druid对数据摄入和数据查询的基准性能测试大大超过了传统解决方案。
- Druid的架构融合了数据仓库,时间序列数据库和检索系统最好的特性。
1.1.4 工作流
解锁新的工作流
Druid为Clickstream,APM(应用性能管理系统),supply chain(供应链),网络遥测,数字营销和其他事件驱动形式的场景解锁了新的查询方式和工作流。Druid专为实时和历史数据的快速临时查询而构建。
1.1.5 多种部署方式
可以部署在AWS/GCP/Azure,混合云,k8s和租用服务器上
Druid可以部署在任Linux环境中,无论是内部环境还是云环境。部署Druid是非常easy的:通过添加或删减服务来扩容缩容。
1.2 使用场景
Apache Druid适用于对实时数据提取,高性能查询和高可用要求较高的场景。因此,Druid通常被作为一个具有丰富GUI的分析系统,或者作为一个需要快速聚合的高并发API的后台。Druid更适合面向事件数据。
1.2.1 常见的使用场景
比较常见的使用场景
1.2.1.1 用户活动和行为
Druid经常用在点击流,访问流,和活动流数据上。具体场景包括:衡量用户参与度,为产品发布追踪A/B测试数据,并了解用户使用方式。Druid可以做到精确和近似计算用户指标,例如不重复计数指标。这意味着,如日活用户指标可以在一秒钟计算出近似值(平均精度98%),以查看总体趋势,或精确计算以展示给利益相关者。Druid可以用来做“漏斗分析”,去测量有多少用户做了某种操作,而没有做另一个操作。这对产品追踪用户注册十分有用。
1.2.1.2 网络流
Druid常常用来收集和分析网络流数据。Druid被用于管理以任意属性切分组合的流数据。Druid能够提取大量网络流记录,并且能够在查询时快速对数十个属性组合和排序,这有助于网络流分析。这些属性包括一些核心属性,如IP和端口号,也包括一些额外添加的强化属性,如地理位置,服务,应用,设备和ASN。Druid能够处理非固定模式,这意味着你可以添加任何你想要的属性。
1.2.1.3 数字营销
Druid常常用来存储和查询在线广告数据。这些数据通常来自广告服务商,它对衡量和理解广告活动效果,点击穿透率,转换率(消耗率)等指标至关重要。
Druid最初就是被设计成一个面向广告数据的强大的面向用户的分析型应用程序。在存储广告数据方面,Druid已经有大量生产实践,全世界有大量用户在上千台服务器上存储了PB级数据。
1.2.1.4 应用性能管理
Druid常常用于追踪应用程序生成的可运营数据。和用户活动使用场景类似,这些数据可以是关于用户怎样和应用程序交互的,它可以是应用程序自身上报的指标数据。Druid可用于下钻发现应用程序不同组件的性能如何,定位瓶颈,和发现问题。
不像许多传统解决方案,Druid具有更小存储容量,更小复杂度,更大数据吞吐的特点。它可以快速分析数以千计属性的应用事件,并计算复杂的加载,性能,利用率指标。比如,基于百分之95查询延迟的API终端。我们可以以任何临时属性组织和切分数据,如以天为时间切分数据,如以用户画像统计,如按数据中心位置统计。
1.2.1.5 物联网和设备指标
Driud可以作为时间序列数据库解决方案,来存储处理服务器和设备的指标数据。收集机器生成的实时数据,执行快速临时的分析,去估量性能,优化硬件资源,和定位问题。
和许多传统时间序列数据库不同,Druid本质上是一个分析引擎。Druid融合了时间序列数据库,列式分析数据库,和检索系统的理念。它在单个系统中支持了基于时间分区,列式存储,和搜索索引。这意味着基于时间的查询,数字聚合,和检索过滤查询都会特别快。
你可以在你的指标中包括百万唯一维度值,并随意按任何维度组合group和filter(Druid 中的dimension维度类似于时间序列数据库中的tag)。你可以基于tag group和rank,并计算大量复杂的指标。而且你在tag上检索和过滤会比传统时间序列数据库更快。
1.2.1.6 OLAP和商业智能
Druid经常用于商业智能场景。公司部署Druid去加速查询和增强应用。和基于Hadoop的SQL引擎(如Presto或Hive)不同,Druid为高并发和亚秒级查询而设计,通过UI强化交互式数据查询。这使得Druid更适合做真实的可视化交互分析。
1.2.2 适合的场景
如果您的使用场景符合以下的几个特征,那么Druid是一个非常不错的选择:
- 数据插入频率比较高,但较少更新数据
- 大多数查询场景为聚合查询和分组查询(GroupBy),同时还有一定得检索与扫描查询
- 将数据查询延迟目标定位100毫秒到几秒钟之间
- 数据具有时间属性(Druid针对时间做了优化和设计)
- 在多表场景下,每次查询仅命中一个大的分布式表,查询又可能命中多个较小的lookup表
- 场景中包含高基维度数据列(例如URL,用户ID等),并且需要对其进行快速计数和排序
- 需要从Kafka、HDFS、对象存储(如Amazon S3)中加载数据
1.2.3 不适合的场景
如果您的使用场景符合以下特征,那么使用Druid可能是一个不好的选择:
- 根据主键对现有数据进行低延迟更新操作。Druid支持流式插入,但不支持流式更新(更新操作是通过后台批处理作业完成)
- 延迟不重要的离线数据系统
- 场景中包括大连接(将一个大事实表连接到另一个大事实表),并且可以接受花费很长时间来完成这些查询
2. Durid是什么
Apache Druid 是一个开源的分布式数据存储引擎。
Druid的核心设计融合了OLAP/analytic databases,timeseries database,和search systems的理念,以创造一个适用广泛用例的统一系统。Druid将这三种系统的主要特性融合进Druid的ingestionlayer(数据摄入层),storage format(存储格式化层),querying layer(查询层),和core architecture(核心架构)中。
2.1 主要特性
列式存储
Druid单独存储并压缩每一列数据。并且查询时只查询特定需要查询的数据,支持快速scan,ranking和groupBy。
原生检索索引
Druid为string值创建反向索引以达到数据的快速搜索和过滤。
流式和批量数据摄入
开箱即用的Apache kafka,HDFS,AWS S3连接器connectors,流式处理器。
灵活的数据模式
Druid优雅地适应不断变化的数据模式和嵌套数据类型。
基于时间的优化分区
Druid基于时间对数据进行智能分区。因此,Druid基于时间的查询将明显快于传统数据库。
支持SQL语句
除了原生的基于JSON的查询外,Druid还支持基于HTTP和JDBC的SQL。
水平扩展能力
百万/秒的数据摄入速率,海量数据存储,亚秒级查询。
易于运维
可以通过添加或移除Server来扩容和缩容。Druid支持自动重平衡,失效转移。
2.2 和其他技术对比
- Druid:是一个实时处理时序数据的OLAP数据库,它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引。
- Kylin:核心是Cube,Cube是一种预计算技术,预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。
- Presto:它没有使用MapReduce,大部分场景下比Hive快一个数量级,其中的关键是所有的处理都在内存中完成。
- Impala:基于内存运算,速度快,支持的数据源没有Presto多。
- Spark SQL:基于Spark平台上的一个OLAP框架,基本思路是增加机器来并行计算,从而提高查询速度。
ES:最大的特点是使用了倒排索引解决索引问题。根据研究,ES在数据获取和聚集用的资源比在Druid高。
框架选型:
- 从超大数据的查询效率来看: Druid > Kylin > Presto > Spark SQL
- 从支持的数据源种类来讲: Presto > Spark SQL > Kylin > Druid
2.3 数据摄入
Druid同时支持流式和批量数据摄入。Druid通常通过像Kafka这样的消息总线(加载流式数据)或通过像HDFS这样的分布式文件系统(加载批量数据)来连接原始数据源。
Druid通过Indexing处理将原始数据以segment的方式存储在数据节点,segment是一种查询优化的数据结构。
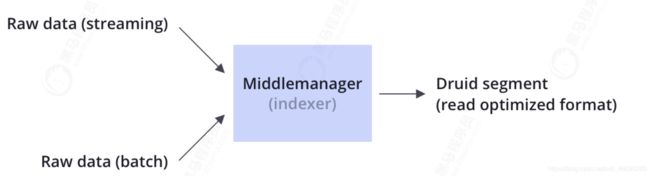
2.4 数据存储
像大多数分析型数据库一样,Druid采用列式存储。根据不同列的数据类型(string,number等),Druid对其使用不同的压缩和编码方式。Druid也会针对不同的列类型构建不同类型的索引。
类似于检索系统,Druid为string列创建反向索引,以达到更快速的搜索和过滤。类似于时间序列数据库,Druid基于时间对数据进行智能分区,以达到更快的基于时间的查询。
不像大多数传统系统,Druid可以在数据摄入前对数据进行预聚合。这种预聚合操作被称之为rollup,这样就可以显著的节省存储成本。

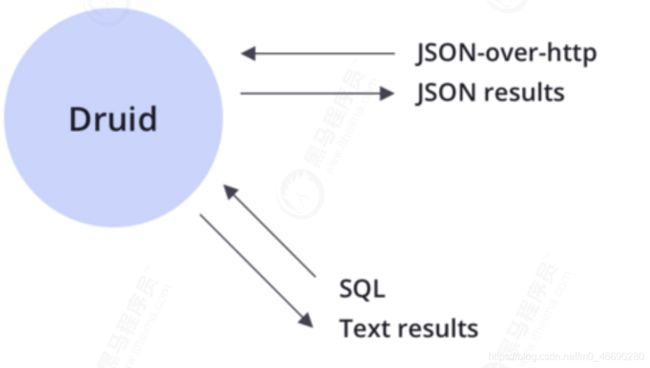
2.5 查询
Druid支持JSON-over-HTTP和SQL两种查询方式。除了标准的SQL操作外,Druid还支持大量的唯一性操作,利用Druid提供的算法套件可以快速的进行计数,排名和分位数计算。
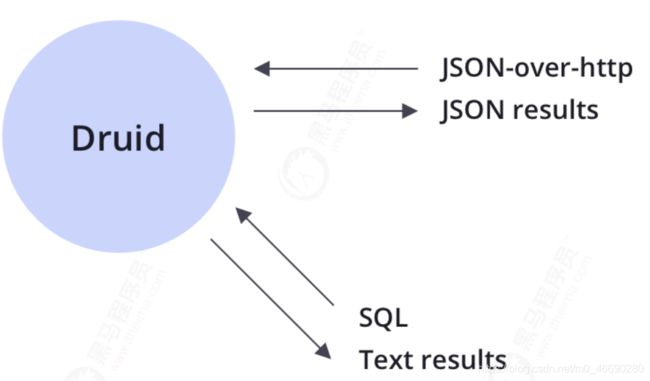
Drui被设计成一个健壮的系统,它需要7*24小时运行。
Druid拥有以下特性,以确保长期运行,并保证数据不丢失。
数据副本
Druid根据配置的副本数创建多个数据副本,所以单机失效不会影响Druid的查询。
独立服务
Druid清晰的命名每一个主服务,每一个服务都可以根据使用情况做相应的调整。服务可以独立失败而不影响其他服务的正常运行。例如,如果数据摄入服务失效了,将没有新的数据被加载进系统,但是已经存在的数据依然可以被查询。
自动数据备份
Druid自动备份所有已经indexed的数据到一个文件系统,它可以是分布式文件系统,如HDFS。你可以丢失所有Druid集群的数据,并快速从备份数据中重新加载。
滚动更新
通过滚动更新,你可以在不停机的情况下更新Druid集群,这样对用户就是无感知的。所有Druid版本都是向后兼容。
3. 安装部署
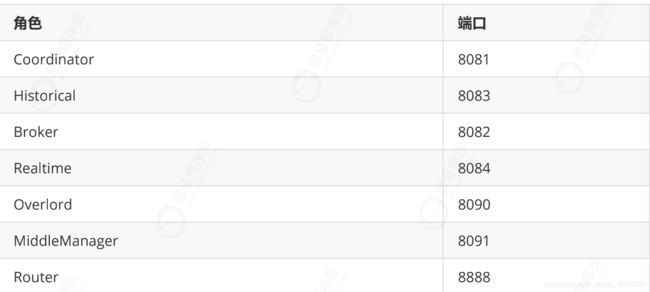
3.1 环境介绍
Durid端口列表
以下是Durid默认的端口列表,防止因为端口占用导致服务器启动失败
3.2 安装方式
获取Druid安装包有以下几种方式
3.2.1 源代码编译
druid/release,主要用于定制化需求时,比如结合实际环境中的周边依赖,或者是加入支持特定查询的部分的优化必定等。
3.2.2 官网下载
官网安装包下载:download,包含Druid部署运行的最基本组件
3.2.3 Imply组合套件
Imply,该套件包含了稳定版本的Druid组件、实时数据写入支持服务、图形化展示查询Web UI和SQL查询支持组件等,目的是为更加方便、快速地部署搭建基于Druid的数据分析应用产品。
3.3 单机配置参考
3.3.1 Nano-Quickstart
1 CPU, 4GB 内存
启动命令: bin/start-nano-quickstart
配置目录: conf/druid/single-server/nano-quickstart
3.3.2 微型快速入门
4 CPU, 16GB 内存
启动命令: bin/start-micro-quickstart
配置目录: conf/druid/single-server/micro-quickstart
3.3.3 小型
8 CPU, 64GB 内存 (~i3.2xlarge)
启动命令: bin/start-small
配置目录: conf/druid/single-server/small
3.3.4 中型
16 CPU, 128GB 内存 (~i3.4xlarge)
启动命令: bin/start-medium
配置目录: conf/druid/single-server/medium
3.3.5 大型
32 CPU, 256GB 内存 (~i3.8xlarge)
启动命令: bin/start-large
配置目录: conf/druid/single-server/large
3.3.6 超大型
64 CPU, 512GB 内存 (~i3.16xlarge)
启动命令: bin/start-xlarge
配置目录: conf/druid/single-server/xlarge
3.4 单机版安装
3.4.1 软件要求
Java 8 (8u92+)
Linux, Mac OS X, 或者其他的类Unix OS (Windows是不支持的)
安装Docker环境
安装Docker-compose环境
3.4.2 硬件要求
Druid包括几个单服务配置示例,以及使用这些配置启动Druid进程的脚本。
如果您在笔记本电脑等小型机器上运行以进行快速评估,那么micro-quickstart配置是一个不错的选择,适用于 4CPU/16GB RAM环境。如果您计划在教程之外使用单机部署进行进一步评估,我们建议使用比micro-quickstart更大的配置。
虽然为大型单台计算机提供了示例配置,但在更高规模下,我们建议在集群部署中运行Druid,以实现容错和减少资源争用。
3.5 imply方式安装
安装推荐Imply方式,Imply方式出了提供druid组件,还有图形化、报表等功能
3.5.1 安装perl
因为启动druid 需要用到perl环境,需要安装下
yum install perl gcc kernel-devel
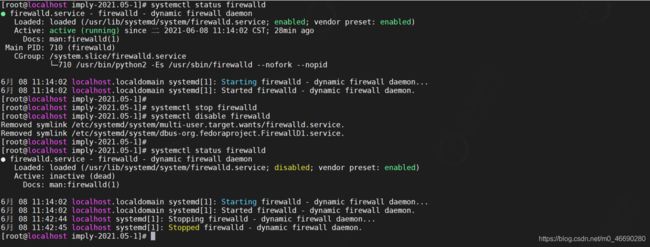
3.5.2 关闭防火墙
#查看防火状态
systemctl status firewalld
#暂时关闭防火墙
systemctl stop firewalld
#永久关闭防火墙
systemctl disable firewalld
3.5.3 安装JDK
选择与自己系统相匹配的版本,我的是Centos7 64位的,所以如果是我的话我会选择此版本,要
记住的你们下载的话选择的是以tar.gz结尾的。
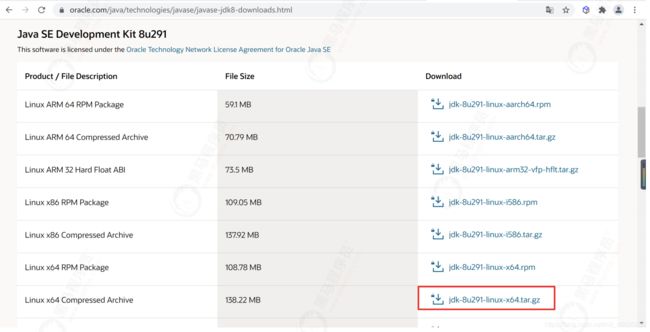
3.5.3.1 下载JDK
到Oracle 官网下载jdk1.8,选择 jdk-8u301-linux-x64.tar.gz
将文件下载到本地后上传到linux目录下
上传文件,解压目录
mkdir /usr/local/java
tar -zxvf jdk-8u301-linux-x64.tar.gz
配置环境变量
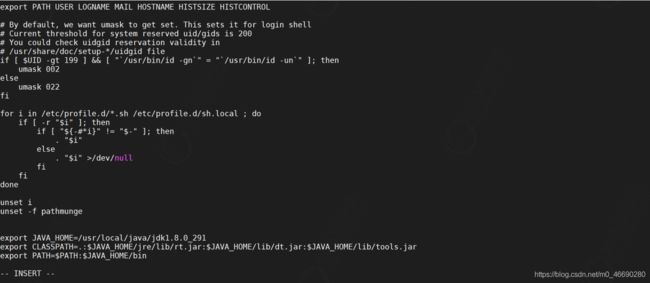
配置环境变量,修改profile文件并加入如下内容
vi /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_291
export
CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools
.jar
export PATH=$PATH:$JAVA_HOME/bin
生效配置
source /etc/profile
检查环境
java -version

3.5.4 安装imply
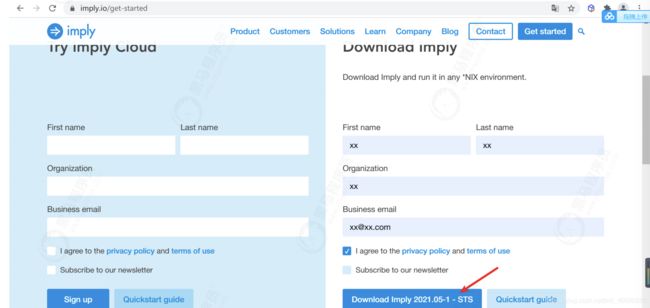
3.5.4.1 登录Imply官网
访问https://imply.io/get-started,进入Imply官网,查找合适的imply的版本的安装包,并填写简要信息后就可以下载了
解压imply
下载后上传到服务器,并进行解压
# 创建imply安装目录
mkdir /usr/local/imply
# 解压imply
tar -zxvf imply-2021.05-1.tar.gz
环境准备
进入 imply-2021.05-1 目录后
# 进入imply目录
cd imply-2021.05-1
快速启动
使用本地存储、默认元数据存储derby,自带zookeeper启动,来体验下 druid
# 创建日志目录
mkdir logs
# 使用命令启动
nohup bin/supervise -c conf/supervise/quickstart.conf > logs/quickstart.log 2>&1 &
查看日志
通过 quickstart.log 来查看impl启动日志
tail -f logs/quickstart.log
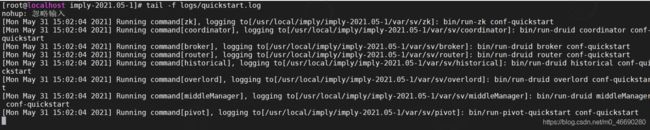
每启动一个服务均会打印出一条日志。可以通过var/sv/xxx/current查看服务启动时的日志信息
tail -f var/sv/broker/current
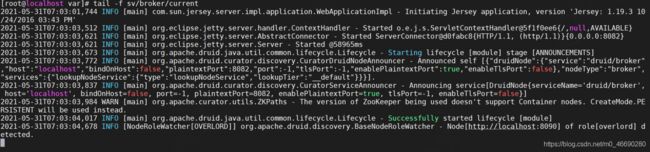
访问Imply
可以通过访问 9095 端口来访问 imply 的管理页面
http://localhost:9095/
访问Druid
访问 8888 端口就可以访问到我们的 druid 了
http://localhost:8888
4. 数据摄取
4.1 加载本地文件
我们导入演示案例种的演示文件
4.1.1.1 数据选择
通过UI选择 local disk
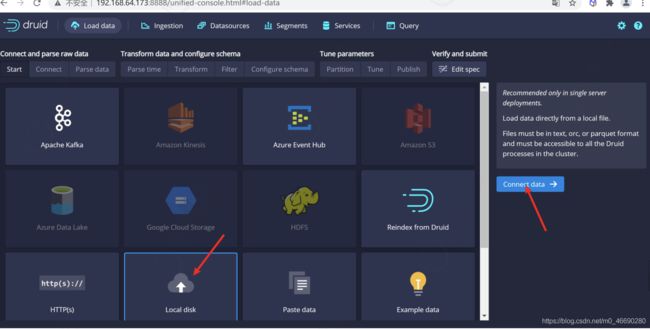
并选择 Connect data
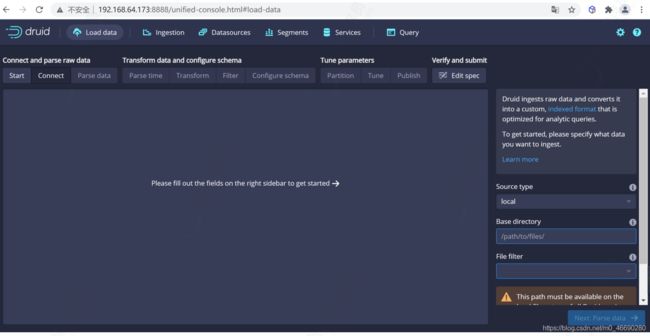
4.1.1.2 演示数据查看
演示数据在 quickstart/tutorial 目录下的 wikiticker-2015-09-12-sampled.json.gz 文件
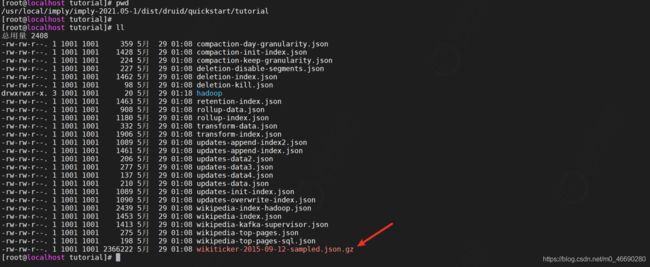
4.1.1.3 选择数据源
因为我们是通过 imply 安装的,在 Base directory 输入绝对路径 /usr/local/imply/imply- 2021.05-1/dist/druid/quickstart/tutorial , File filter 输入 wikiticker-2015-09-12- sampled.json.gz ,并选择 apply 应用配置,我们数据已经加载进来了
Base directory 和 File filter 分开是因为可能需要同时从多个文件中摄取数据。
4.1.1.4 加载数据
数据定位后,您可以点击"Next: Parse data"来进入下一步。
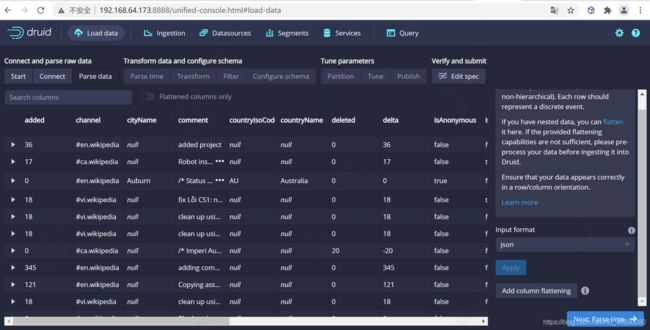
数据加载器将尝试自动为数据确定正确的解析器。在这种情况下,它将成功确定 json 。可以随意使用不同的解析器选项来预览Druid如何解析您的数据。
4.1.2 数据源规范配置
4.1.2.1 设置时间列
json 选择器被选中后,点击 Next:Parse time 进入下一步来决定您的主时间列。
Druid的体系结构需要一个主时间列(内部存储为名为 _time 的列)。如果您的数据中没有时间戳,请选择 固定值(Constant Value) 。在我们的示例中,数据加载器将确定原始数据中的时间列是唯一可用作主时间列的候选者。
这里可以选择时间列,以及时间的显示方式
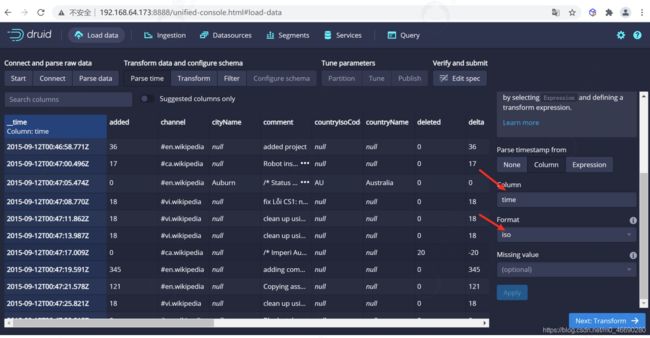
4.1.2.2 设置转换器
在这里可以新增虚拟列,将一个列的数据转换成另一个虚拟列,这里我们没有设置,直接跳过
4.1.2.3 设置过滤器
这里可以设置过滤器,对于某些数据可以不进行显示,这里我们也跳过
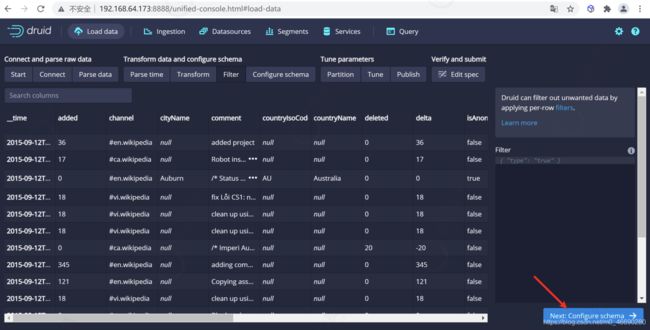
4.1.2.4 配置schema
在 Configure schema 步骤中,您可以配置将哪些维度和指标摄入到Druid中,这些正是数据在被Druid中摄取后出现的样子。 由于我们的数据集非常小,关掉rollup、确认更改
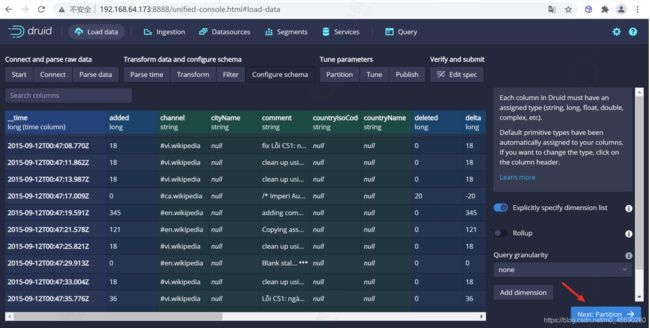
4.1.2.5 配置Partition
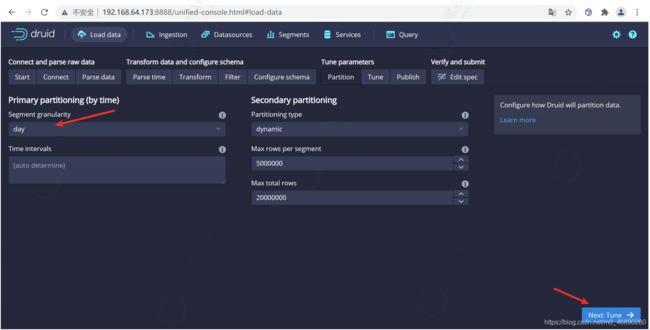
一旦对schema满意后,点击 Next 后进入 Partition 步骤,该步骤中可以调整数据如何划分为段文件的方式,因为我们数据量非常小,这里我们按照 DAY 进行分段
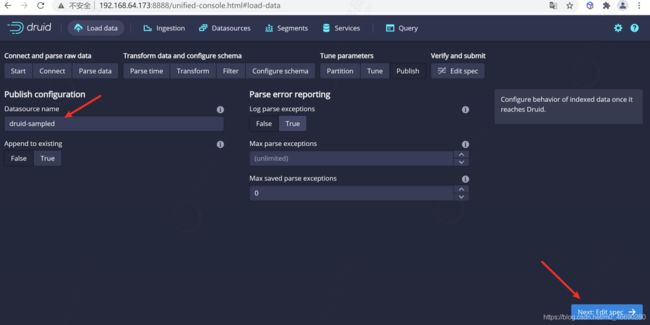
4.1.3 提交任务
发布数据
点击完成 Tune 步骤,进入到 Publish 步,在这里我们可以给我们的数据源命名,这里我们就命名为 druid-sampled ,
点击下一步就可以查看我们的数据规范
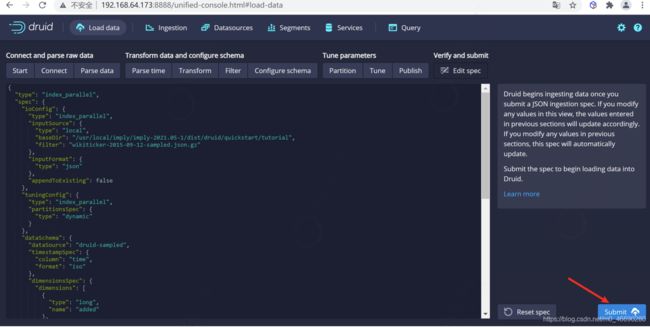
这就是您构建的规范,为了查看更改将如何更新规范是可以随意返回之前的步骤中进行更改,同样,您也可以直接编辑规范,并在前面的步骤中看到它。
提交任务
对摄取规范感到满意后,请单击 Submit ,然后将创建一个数据摄取任务。
您可以进入任务视图,重点关注新创建的任务。任务视图设置为自动刷新,请等待任务成功。
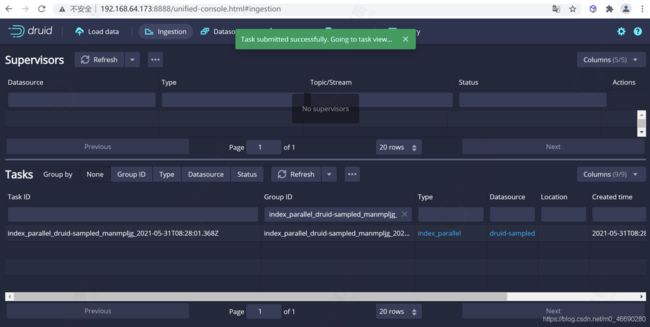
当一项任务成功完成时,意味着它建立了一个或多个段,这些段现在将由Data服务器接收。
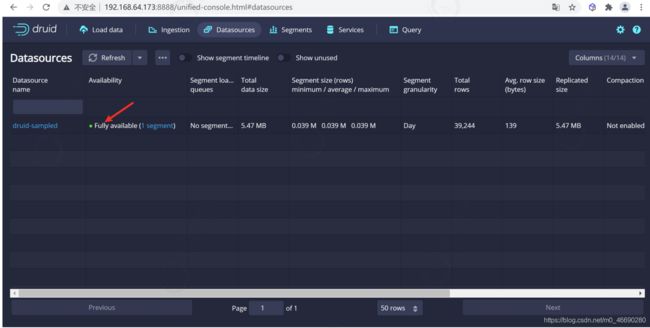
查看数据源
从标题导航到 Datasources 视图,一旦看到绿色(完全可用)圆圈,就可以查询数据源。此时,您可以转到 Query 视图以对数据源运行SQL查询。
查询数据
可以转到查询页面进行数据查询,这里在sql窗口编写sql后点击运行就可以查询数据了

4.2 kafka加载流式数据
4.2.1 安装Kafka
这里我们使用 docker-compose 的方式启动kafka
4.2.1.1 编辑资源清单
vi docker-compose.yml
version: '2'
services:
kafka:
image: wurstmeister/kafka ## 镜像
volumes:
- /etc/localtime:/etc/localtime ## 挂载位置(kafka镜像和宿主机器之间时间保持一直)
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.64.186 ## 修改:宿主机IP
KAFKA_ZOOKEEPER_CONNECT: 192.168.64.186:2181 ## 卡夫卡运行是基于zookeeper的
KAFKA_ADVERTISED_PORT: 9092
KAFKA_LOG_RETENTION_HOURS: 120
KAFKA_MESSAGE_MAX_BYTES: 10000000
KAFKA_REPLICA_FETCH_MAX_BYTES: 10000000
KAFKA_GROUP_MAX_SESSION_TIMEOUT_MS: 60000
KAFKA_NUM_PARTITIONS: 3
KAFKA_DELETE_RETENTION_MS: 1000
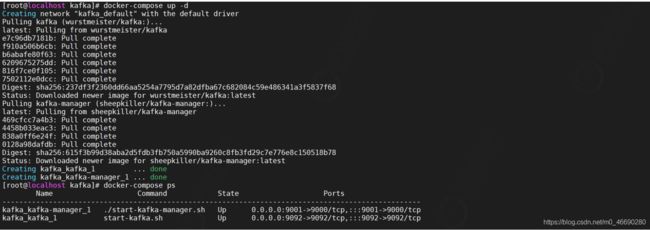
启动容器
docker-compose up -d
docker-compose ps
验证kafka
启动kafka后需要验证kafka是否可用
登录容器
登录容器并进入指定目录
#进入容器
docker exec -it kafka_kafka_1 bash
#进入 /opt/kafka_2.13-2.7.0/bin/ 目录下
cd /opt/kafka_2.13-2.7.0/bin/

发送消息
运行客户端发送消息,注意这里的连接地址需要写我们配置的宿主机地址
#运行kafka生产者发送消息
./kafka-console-producer.sh --broker-list 192.168.64.173:9092 --topic test
发送的数据如下
{"datas":
[{"channel":"","metric":"temperature","producer":"ijinus","sn":"IJA0101-
00002245","time":"1543207156000","value":"80"}],"ver":"1.0"}

消费消息
运行消费者消费消息
./kafka-console-consumer.sh --bootstrap-server 192.168.64.173:9092 --topic test --from-beginning

有数据打印说明我们kafka安装是没有问题的
4.2.4 发送数据到kafka
编写代码
编写代码发送消息到kafka中
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
@Component
public class KafkaSender {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息到kafka
*
* @param topic 主题
* @param message 内容体
*/
public void sendMsg(String topic, String message) {
kafkaTemplate.send(topic, message);
}
}
@RestController
@RequestMapping("/taxi")
public class KafkaController {
@Autowired
private KafkaSender kafkaSender;
@RequestMapping("/batchTask/{num}")
public String batchAdd(@PathVariable("num") int num) {
for (int i = 0; i < num; i++) {
Message message = Utils.getRandomMessage();
kafkaSender.sendMsg("message", JSON.toJSONString(message));
}
return "OK";
}
@RequestMapping("/update")
public String update(@RequestBody Message message) {
kafkaSender.sendMsg("messageupdate", JSON.toJSONString(message));
return "OK";
}
}
server:
port: 8010
spring:
application:
name: druid-kafka-service
######################### 数据源连接池的配置信息 #################
kafka:
bootstrap-servers: localhost:9092
producer: # producer 生产者
retries: 0 # 重试次数
acks: 1 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 # 批量大小
buffer-memory: 33554432 # 生产端缓冲区大小
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# value-serializer: com.itheima.demo.config.MySerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
发送消息
使用postman 发送消息到kafka,消息地址:http://localhost:8010/taxi/batchTask/10,消息数据如下
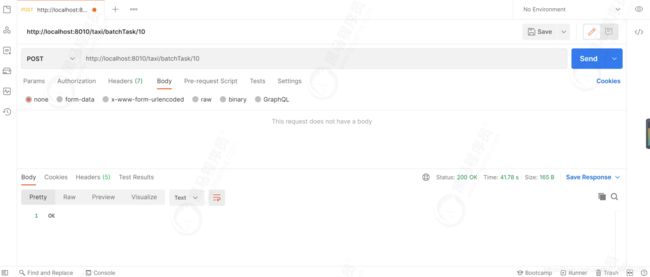
显示OK说明消息已经发送到了kafka中
# 4.2.5 数据选择
kafka数据查看
在load页面选择kafka,进行数据摄取模式选择
选择数据源
在这里输入ZK的地址以及需要选择数据的 topic
localhost:9092
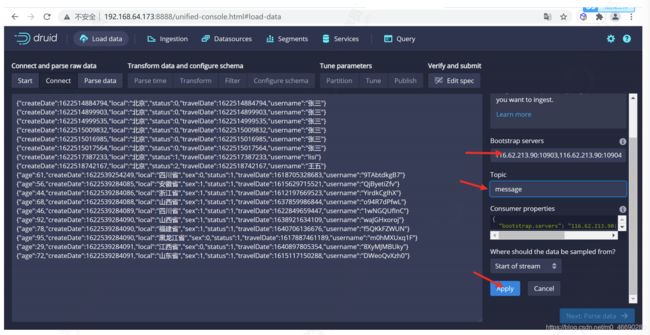
加载数据
点击 apply 应用配置,设置加载数据源
数据源规范配置
设置时间列
json 选择器被选中后,点击 Next:Parse time 进入下一步来决定您的主时间列。
因为我们的时间列有两个创建时间以及打车时间,我们配置时间列为 trvelDate
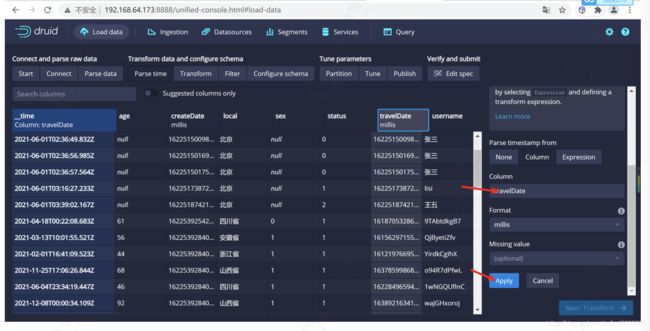
设置转换器
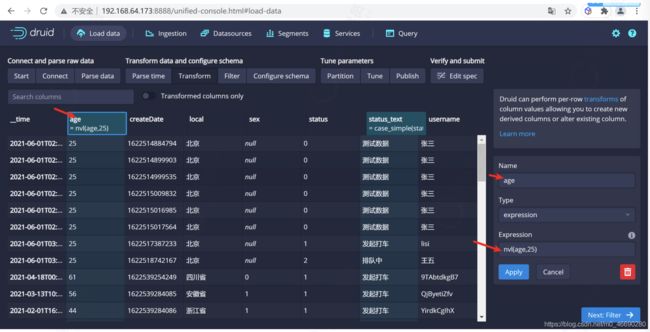
在这里可以新增虚拟列,将一个列的数据转换成另一个虚拟列,这里我们增加一个状态的虚拟列,来显示状态的中文名称我们定义 0:测试数据, 1:发起打车,2:排队中,3:司机接单,4:乘客上车,5:完成打车
我们使用 case_simple 来实现判断功能,更多判断功能参考
case_simple(status,0,'测试数据',1,'发起打车',2,'排队中',3,'司机接单',4,'完成打车','状态 错误')
在这里我们新建了一个 status_text 的虚拟列来展示需要中文显示的列
配置年龄默认值,如果为空我们设置为25
nvl(age,25)
配置性别设置,我们需要设置为男女,0:男,1:女,如果为null,我们设置为男
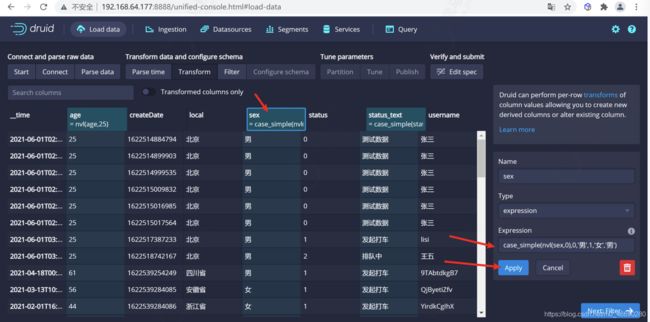
设置过滤器
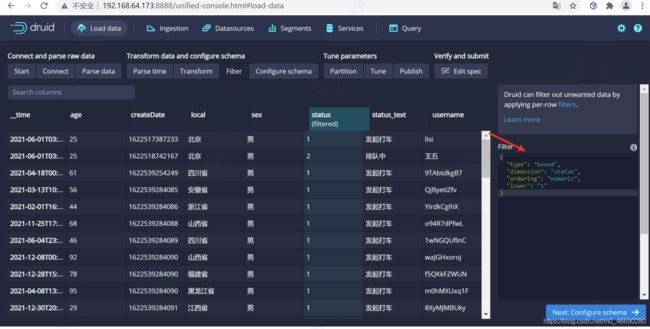
这里可以设置过滤器,对于某些数据不展示,这里我们使用 区间过滤器 选择显示 status>=1 的数据,具体表达式可用参考
{
"type" : "bound",
"dimension" : "status",
"ordering": "numeric",
"lower": "1",
}
因为我们把数据是0的测试数据不显示了,所以只显示了一条数据为1的数据
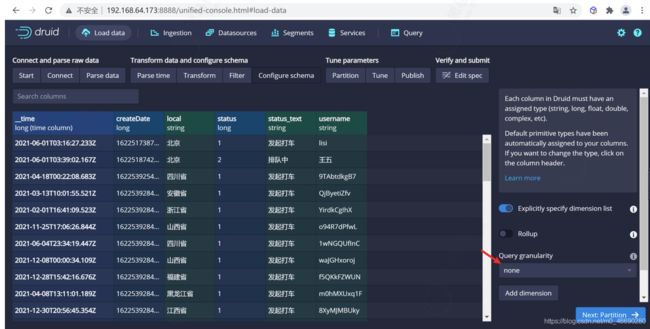
配置schema
在 Configure schema 步骤中,您可以配置将哪些维度和指标摄入到Druid中,这些正是数据在被Druid中摄取后出现的样子。 由于我们的数据集非常小,关掉rollup、确认更改。
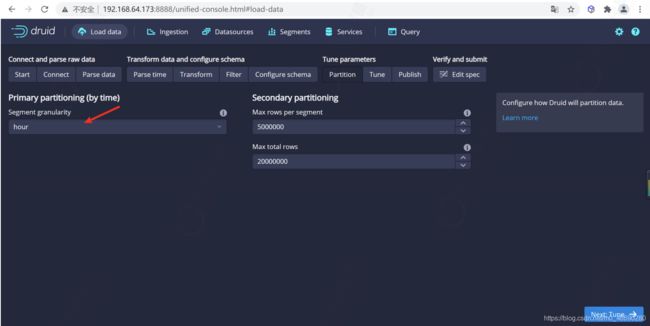
配置Partition
一旦对schema满意后,点击 Next 后进入 Partition 步骤,该步骤中可以调整数据如何划分为段文件的方式,因为我们打车一般按照小时来算的,我们设置为分区为``hour
配置拉取方式
这里设置kafka的拉取方式,主要设置偏移量的一些配置
在 Tune 步骤中**,将 Use earliest offset 设置为 True 非常重要**,因为我们需要从流的开始位置消费数据。 其他没有任何需要更改的地方,进入到 Publish 步
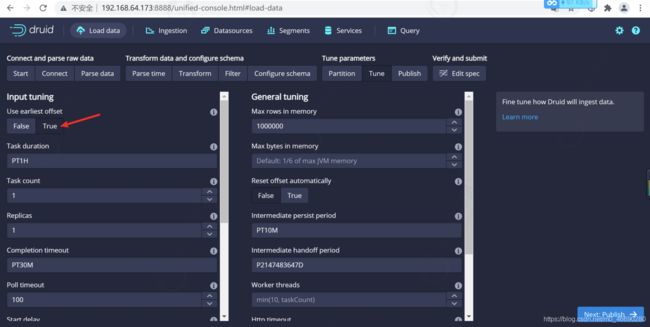
提交任务
发布数据
点击完成 Tune 步骤,进入到 Publish 步,在这里我们可以给我们的数据源命名,这里我们就命名为 taxi-message ,
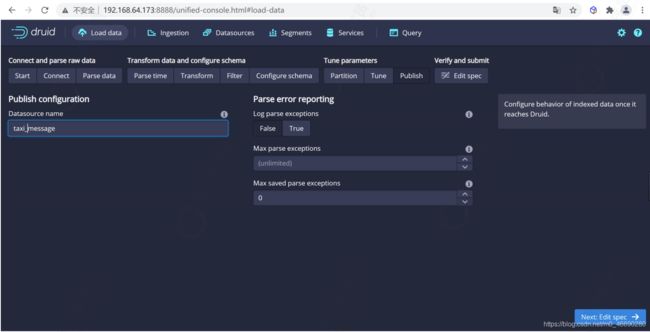
点击下一步就可以查看我们的数据规范
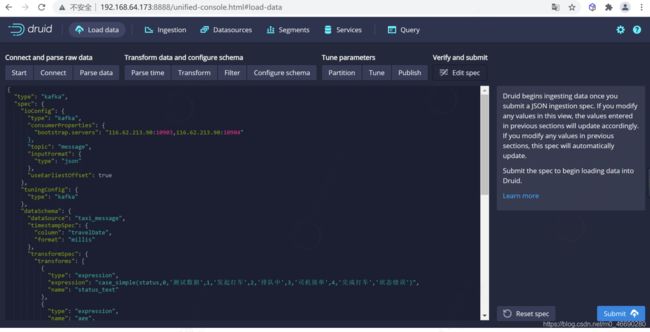
这就是您构建的规范,为了查看更改将如何更新规范是可以随意返回之前的步骤中进行更改,同样,您也可以直接编辑规范,并在前面的步骤中看到它。
提交任务
对摄取规范感到满意后,请单击 Submit ,然后将创建一个数据摄取任务。
您可以进入任务视图,重点关注新创建的任务。任务视图设置为自动刷新,请等待任务成功。
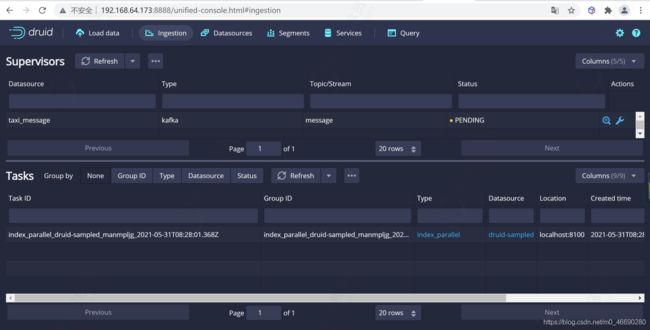
当一项任务成功完成时,意味着它建立了一个或多个段,这些段现在将由Data服务器接收。
查看数据源
从标题导航到 Datasources 视图,一旦看到绿色(完全可用)圆圈,就可以查询数据源。此时,您可以转到 Query 视图以对数据源运行SQL查询。
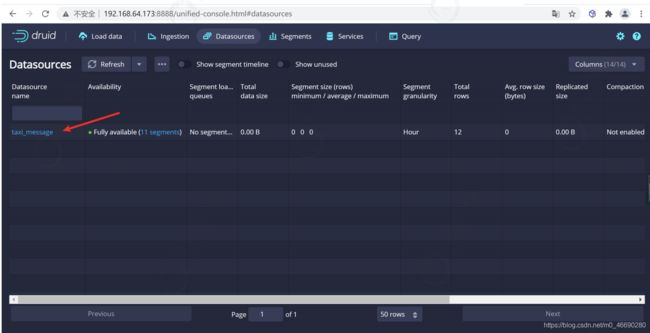
查询数据
可以转到查询页面进行数据查询,这里在sql窗口编写sql后点击运行就可以查询数据了

动态添加数据
发送一条数据到kafka
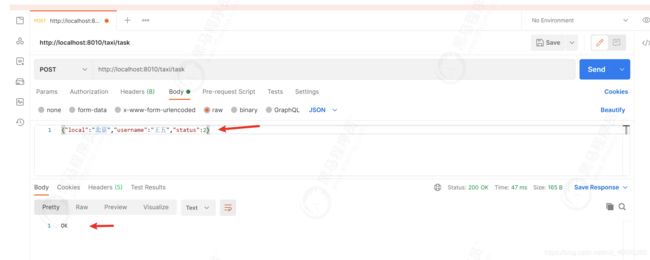
druid 查询数据,发现新的数据已经进来了
4.2.8 清理数据
关闭集群
# 进入impl安装目录
cd /usr/local/imply/imply-2021.05-1
# 关闭集群
./bin/service --down

等待关闭服务
通过进程查看,查看服务是否已经关闭
ps -ef|grep druid

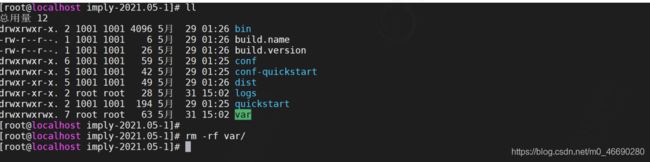
清理数据
通过删除druid软件包下的 var 目录的内容来重置集群状态
ll
rm -rf var
** 重新启动集群**
nohup bin/supervise -c conf/supervise/quickstart.conf > logs/quickstart.log 2>&1 &
查看数据源
登录后查看数据源,我们发现已经被重置了
5. 数据查询
Druid支持JSON-over-HTTP和SQL两种查询方式。除了标准的SQL操作外,Druid还支持大量的唯一性操作,利用Druid提供的算法套件可以快速的进行计数,排名和分位数计算。
5.1 准备工作
5.1.1 导入大量数据
准备大量数据提供查询,我们插入1万条随机打车数据
http://localhost:8010/taxi/batchTask/100000
查看数据摄取进程
我们发现数据摄取进程正在运行,可以等待数据摄取任务结束
5.2 原生查询
Druid 最开始的时候是不支持 SQL 查询的,原生查询是通过查询 Broker 提供的 http server 来实现的
5.2.1 查询语法
curl -L -H'Content-Type:application/json' -XPOST --data-binary
@<query_json_file> <queryable_host>:<port>/druid/v2/?pretty
查询案例
编辑查询JSON
# 创建查询目录
mkdir query
# 编辑查询的JSON
vi query/filter1.json
{
"queryType":"timeseries",
"dataSource":"taxi_message",
"granularity":"month",
"aggregations":[
{
"type":"count",
"name":"taxiNum"
}
],
"filter":{"type":"selector","dimension":"status","value":1},
"intervals":["2021-06-07/2022-06-07"]
}
参数解释
- queryType:查询类型,timeseries代表时间序列查询
- dataSource:数据源,指定需要查询的数据源是什么
- granularity:分组粒度,指定需要进行分组的粒度是什么样的
- aggregations:聚合查询:里面我们聚合了count,对数据进行统计
- filter:数据过滤,需要查询那些数据
- intervals:查询时间的范围,注意时间范围是前闭后开的,后面的日期是查询不到的
执行查询命令
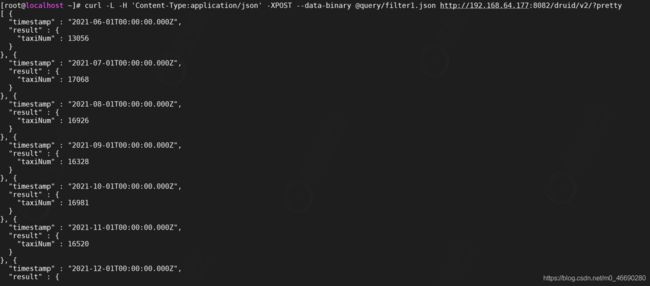
在命名行中执行下面的命令会将查询json发送到对应的broker中进行查询 --data-binary 指定的查询json的路径
curl -L -H 'Content-Type:application/json' -XPOST --data-binary
@query/filter1.json http://192.168.64.177:8082/druid/v2/?pretty
我们查询了每个月发起打车的人数有多少
5.3 查询类型
druid查询采用的是HTTP RESTFUL方式,REST接口负责接收客户端的查询请求,客户端只需要将查询条件封装成JSON格式,通过HTTP方式将JSON查询条件发送到broker节点,查询成功会返回JSON格式的结果数据。了解一下druid提供的查询类型
5.4.1 时间序列查询
timeseries时间序列查询对于指定时间段按照查询规则返回聚合后的结果集,查询规则中可以设置查询粒度,结果排序方式以及过滤条件,过滤条件可以使用嵌套过滤,并且支持后聚合。
查询属性
时间序列查询主要包括7个主要部分
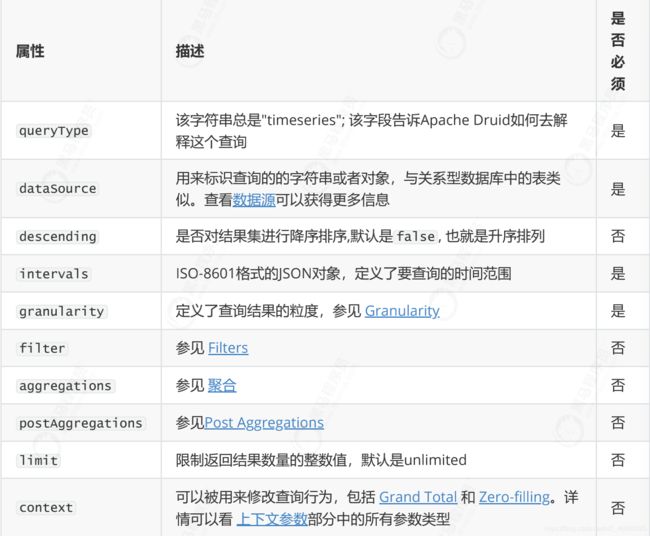
数据源
,Granularity
,Filters
,聚合
,Post Aggregations
,Grand Total
,Zero-filling
,上下文参数
{
"queryType":"topN",
"dataSource":"taxi_message",
"dimension":"local",
"threshold":2,
"metric":"age",
"granularity":"month",
"aggregations":[
{
"type":"longMin",
"name":"age",
"fieldName":"age"
}
],
"filter":{"type":"selector","dimension":"sex","value":"也"},
"intervals":["2021-06-07/2022-06-07"]
}
5.4.2 TopN查询
topn查询是通过给定的规则和显示维度返回一个结果集,topn查询可以看做是给定排序规则,返回单一维度的group by查询,但是topn查询比group by性能更快。metric这个属性是topn专属的按照该指标排序。
查询属性
topn的查询属性如下

案例
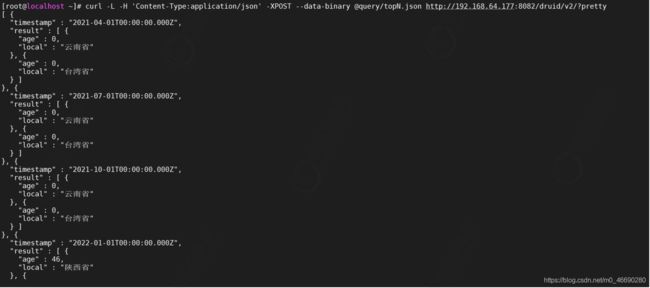
查询每个季度年龄最小的女性的前两个的城市
vi query/topN.json
{
"queryType":"topN",
"dataSource":"taxi_message",
"dimension":"local",
"threshold":2,
"metric":"age",
"granularity":"Quarter",
"aggregations":[
{
"type":"longMin",
"name":"age",
"fieldName":"age"
}
],
"filter":{"type":"selector","dimension":"sex","value":"也"},
"intervals":["2021-06-07/2022-06-07"]
}
执行查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/topN.json http://192.168.64.177:8082/druid/v2/?pretty
5.4.5 分组查询
在实际应用中经常需要进行分组查询,等同于sql语句中的Group by查询,如果对单个维度和指标进行分组聚合计算,推荐使用topN查询,能够获得更高的查询性能,分组查询适合多维度,多指标聚合查询
查询属性
下表内容为一个GroupBy查询的主要部分:
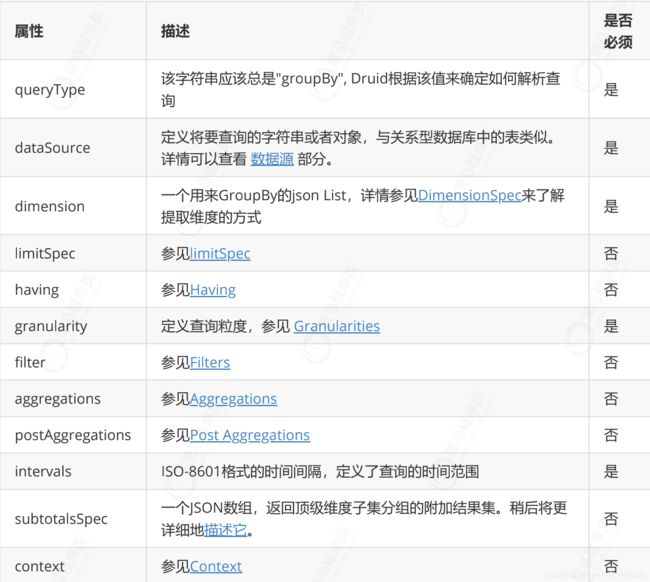
案例
每一季度统计年龄在21-31的男女打车的数量
vi query/groupBy.json
{
"queryType":"groupBy",
"dataSource":"taxi_message",
"granularity":"Quarter",
"dimensions":["sex"],
"aggregations":[
{
"type":"count",
"name":"taxiNum"
}
],
"filter":{
"type":"bound",
"dimension":"age",
"lower":"21",
"upper":"31",
"alphaNumeric":true
},
"intervals":["2021-06-07/2022-06-07"]
}
执行查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary
@query/groupBy.json http://192.168.64.177:8082/druid/v2/?pretty

5.5 查询组件
在介绍具体的查询之前,我们先来了解一下各种查询都会用到的基本组件,如
Filter,Aggregator,Post-Aggregator,Query,Interval等,每种组件都包含很多的细节
5.5.1 Filter
Filter就是过滤器,在查询语句中就是一个JSON对象,用来对维度进行筛选和过滤,表示维度满足
Filter的行是我们需要的数据,类似sql中的where字句。Filter包含的类型如下:
选择过滤器
Selector Filter的功能类似于SQL中的 where key=value ,它的json示例如下
"Filter":{"type":"selector","dimension":dimension_name,"value":target_value}
使用案例
vi query/filter1.json
{
"queryType":"timeseries",
"dataSource":"taxi_message",
"granularity":"month",
"aggregations":[
{
"type":"count",
"name":"taxiNum"
}
],
"filter":{"type":"selector","dimension":"status","value":1},
"intervals":["2021-06-07/2022-06-07"]
}
正则过滤器
Regex Filter 允许用户使用正则表达式进行维度的过滤筛选,任何java支持的标准正则表达式druid都支持,它的JSON格式如下:
"filter":{"type":"regex","dimension":dimension_name,"pattern":regex}
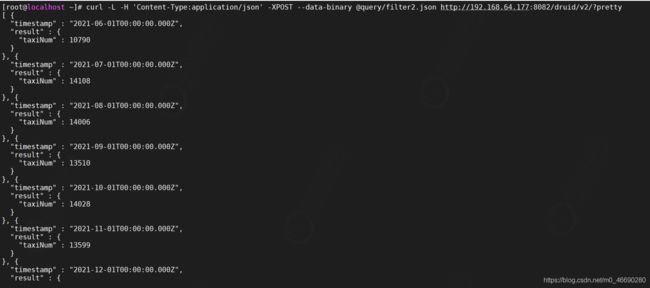
使用案例,我们搜索姓名包含数字的的用户进行聚合统计
vi query/filter2.json
{
"queryType":"timeseries",
"dataSource":"taxi_message",
"granularity":"month",
"aggregations":[
{
"type":"count",
"name":"taxiNum"
}
],
"filter":{"type":"regex","dimension":"username","pattern":"[0-9]{1,}"},
"intervals":["2021-06-07/2022-06-07"]
}
执行查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary
@query/filter2.json http://192.168.64.177:8082/druid/v2/?pretty
逻辑过滤器
Logincal Expression Filter包含and,not,or三种过滤器,每一种都支持嵌套,可以构建丰富的逻辑表达式,与sql中的and,not,or类似,JSON表达式如下:
"filter":{"type":"and","fields":[filter1,filter2]}
"filter":{"type":"or","fields":[filter1,filter2]}
"filter":{"type":"not","fields":[filter]}
使用案例,我们查询每一个月,进行打车并且是女性的数量
vi query/filter3.json
{
"queryType":"timeseries",
"dataSource":"taxi_message",
"granularity":"month",
"aggregations":[
{
"type":"count",
"name":"taxiNum"
}
],
"filter":{
"type":"and",
"fields":[
{"type":"selector","dimension":"status","value":1},
{"type":"selector","dimension":"sex","value":"也"}
]
},
"intervals":["2021-06-07/2022-06-07"]
}
进行数据查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary
@query/filter3.json http://192.168.64.177:8082/druid/v2/?pretty
包含过滤器
In Filter类似于SQL中的in, 比如 where username in(‘zhangsan’,‘lisi’,‘zhaoliu’),它的JSON格式如下:
{
"type":"in",
"dimension":"local",
"values":['四川省','江西省','福建省']
}
使用案例,我们查询每一个月,在四川省、江西省、福建省打车的人数
vi query/filter4.json
{
"queryType":"timeseries",
"dataSource":"taxi_message",
"granularity":"month",
"aggregations":[
{
"type":"count",
"name":"taxiNum"
}
],
"filter":{
"type":"in",
"dimension":"local",
"values":["四川省","江西省","福建省"]
},
"intervals":["2021-06-07/2022-06-07"]
}
进行数据查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary
@query/filter4.json http://192.168.64.177:8082/druid/v2/?pretty
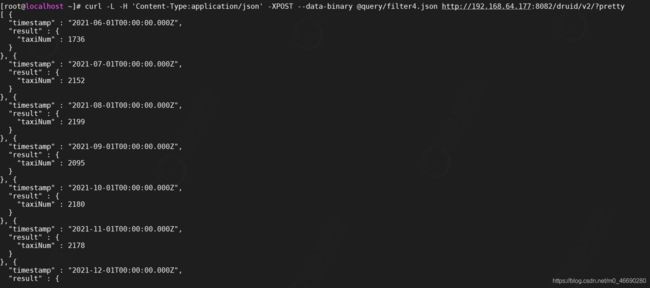
区间过滤器
Bound Filter是比较过滤器,包含大于,等于,小于三种,它默认支持的就是字符串比较,是基于字典顺序,如果使用数字进行比较,需要在查询中设定alpaNumeric的值为true,需要注意的是Bound Filter默认的大小比较为>=或者<=,因此如果使用<或>,需要指定lowerStrict值为true,或者upperStrict值为true,它的JSON格式如下: 21 <=age<=31
{
"type":"bound",
"dimension":"age",
"lower":"21", #默认包含等于
"upper":"31", #默认包含等于
"alphaNumeric":true #数字比较时指定alphaNumeric为true
}
使用案例,我们查询每一个月,年龄在21-31之间打车人的数量
vi query/filter5.json
{
"queryType":"timeseries",
"dataSource":"taxi_message",
"granularity":"month",
"aggregations":[
{
"type":"count",
"name":"taxiNum"
}
],
"filter":{
"type":"bound",
"dimension":"age",
"lower":"21",
"upper":"31",
"alphaNumeric":true
},
"intervals":["2021-06-07/2022-06-07"]
}
进行数据查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter5.json http://192.168.64.177:8082/druid/v2/?pretty
聚合粒度
聚合粒度通过granularity配置项指定聚合时间跨度,时间跨度范围要大于等于创建索引时设置的索引粒度,druid提供了三种类型的聚合粒度分别是:Simple,Duration,Period
Simple的聚合粒度
Simple的聚合粒度通过druid提供的固定时间粒度进行聚合,以字符串表示,定义查询规则的时候不需要显示设置type配置项,druid提供的常用Simple粒度:
all,none,minute,fifteen_minute,thirty_minute,hour,day,month,Quarter(季度),year;
- all:会将起始和结束时间内所有数据聚合到一起返回一个结果集,
- none:按照创建索引时的最小粒度做聚合计算,最小粒度是毫秒为单位,不推荐使用性能较差;
- minute:以分钟作为聚合的最小粒度;
- fifteen_minute:15分钟聚合;
- thirty_minute:30分钟聚合
- hour:一小时聚合
- day:天聚合
- month:月聚合
- Quarter:季度聚合
- year:年聚合
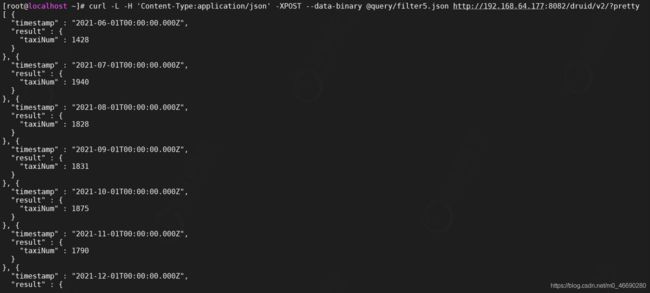
编写测试,我们这里按照季度聚合,并且我们过滤年龄是21-31的数据,并且按照地域以及性别进行分组
vi query/filter6.json
{
"queryType":"groupBy",
"dataSource":"taxi_message",
"granularity":"Quarter",
"dimensions":["local","sex"],
"aggregations":[
{
"type":"count",
"name":"taxiNum"
}
],
"filter":{
"type":"bound",
"dimension":"age",
"lower":"21",
"upper":"31",
"alphaNumeric":true
},
"intervals":["2021-06-07/2022-06-07"]
}
进行查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter6.json http://192.168.64.177:8082/druid/v2/?pretty
Duration聚合粒度
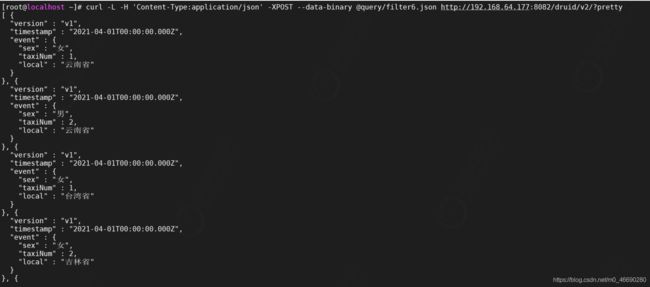
duration聚合粒度提供了更加灵活的聚合粒度,不只局限于Simple聚合粒度提供的固定聚合粒度,而是以毫秒为单位自定义聚合粒度,比如两小时做一次聚合可以设置duration配置项为7200000毫秒,所以Simple聚合粒度不能够满足的聚合粒度可以选择使用Duration聚合粒度。
注意:使用Duration聚合粒度需要设置配置项type值为duration
编写测试,我们按照
vi query/filter7.json
{
"queryType":"groupBy",
"dataSource":"taxi_message",
"granularity":{
"type":"duration",
"duration":7200000
},
"dimensions":["local","sex"],
"aggregations":[
{
"type":"count",
"name":"taxiNum"
}
],
"filter":{
"type":"bound",
"dimension":"age",
"lower":"21",
"upper":"31",
"alphaNumeric":true
},
"intervals":["2021-06-07/2021-06-10"]
}
数据查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter7.json http://192.168.64.177:8082/druid/v2/?pretty
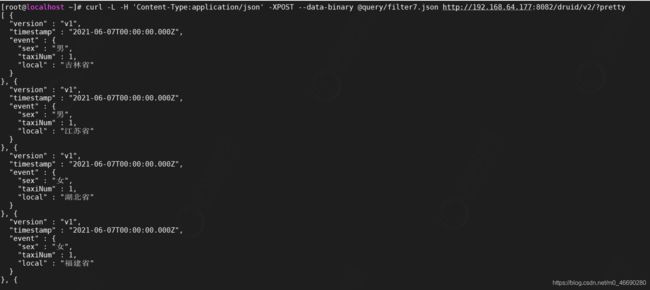
Period聚合粒度
Period聚合粒度采用了日期格式,常用的几种时间跨度表示方法,一小时:PT1H,一周:P1W,一天:P1D,一个月:P1M;使用Period聚合粒度需要设置配置项type值为period,
编写测试,我们按照一天进行聚合
vi query/filter8.json
{
"queryType":"groupBy",
"dataSource":"taxi_message",
"granularity":{
"type":"period",
"period":"P1D"
},
"dimensions":["sex"],
"aggregations":[
{
"type":"count",
"name":"taxiNum"
}
],
"filter":{
"type":"bound",
"dimension":"age",
"lower":"21",
"upper":"31",
"alphaNumeric":true
},
"intervals":["2021-06-07/2021-06-10"]
}
数据查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter8.json http://192.168.64.177:8082/druid/v2/?pretty
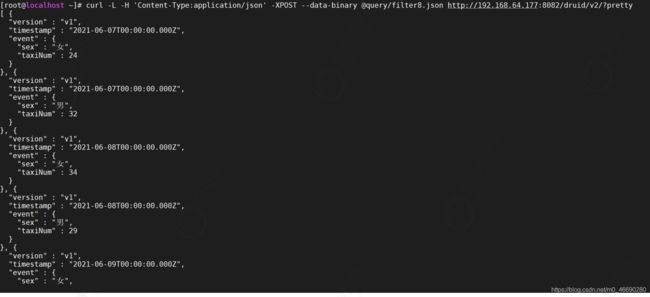
5.5.2聚合器
Aggregator是聚合器,聚合器可以在数据摄入阶段和查询阶段使用,在数据摄入阶段使用聚合器能够在数据被查询之前按照维度进行聚合计算,提高查询阶段聚合计算性能,在查询过程中,使用聚合器能够实现各种不同指标的组合计算。
公共属性
聚合器的公共属性介绍
- type:声明使用的聚合器类型;
- name:定义返回值的字段名称,相当于sql语法中的字段别名;
- fieldName:数据源中已定义的指标名称,该值不可以自定义,必须与数据源中的指标名一致;
计数聚合
计数聚合器,等同于sql语法中的count函数,用于计算druid roll-up合并之后的数据条数,并不是摄入的原始数据条数,在定义数据模式指标规则中必须添加一个count类型的计数指标count;
比如想查询Roll-up 后有多少条数据,查询的JSON格式如下
vi query/aggregator1.json
{
"queryType":"timeseries",
"dataSource":"taxi_message",
"granularity":"Quarter",
"aggregations":[
{
"type":"count",
"name":"count"
}
],
"filter":{
"type":"bound",
"dimension":"age",
"lower":"21",
"upper":"31",
"alphaNumeric":true
},
"intervals":["2021-06-07/2022-06-07"]
}
求合聚合
求和聚合器,等同于sql语法中的sum函数,用户指标求和计算,druid提供两种类型的聚合器,分别是long类型和double类型的聚合器;
第一类就是longSum Aggregator ,负责整数类型的计算,JSON格式如下:
{“type”:“longSum”,“name”:out_name,“fieldName”:“metric_name”}
第二类是doubleSum Aggregator,负责浮点数计算,JSON格式如下:
{“type”:“doubleSum”,“name”:out_name,“fieldName”:“metric_name”}
示例
vi query/aggregator2.json
{
"queryType":"timeseries",
"dataSource":"taxi_message",
"granularity":"Quarter",
"aggregations":[
{
"type":"longSum",
"name":"ageSum",
"fieldName":"age"
}
],
"filter":{
"type":"bound",
"dimension":"age",
"lower":"21",
"upper":"31",
"alphaNumeric":true
},
"intervals":["2021-06-07/2022-06-07"]
}
5.6 Druid SQL
Druid SQL是一个内置的SQL层,是Druid基于JSON的本地查询语言的替代品,它由基于 ApacheCalcite的解析器和规划器提供支持
Druid SQL将SQL转换为查询Broker(查询的第一个进程)上的原生Druid查询,然后作为原生Druid查询传递给数据进程。除了在Broker上 转换SQL) 的(轻微)开销之外,与原生查询相比,没有额外的性能损失。
5.6.1基本查询
5.6.1.1查询数据总条数
可以在druid的控制台进行查询
select count(1) from "taxi_message"
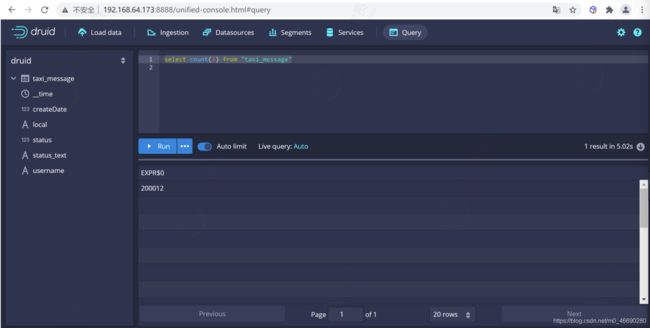
查询当前打车人数
我们可以统计出来当前的打车的人数
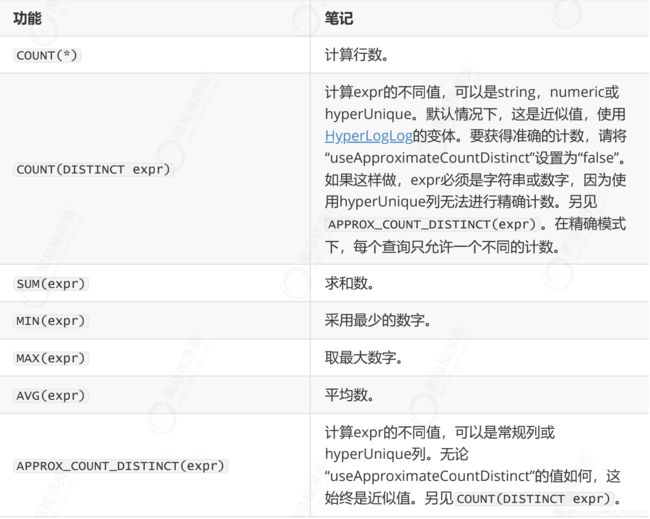
5.6.2 聚合功能
聚合函数可以出现在任何查询的SELECT子句中。可以使用类似语法过滤任何聚合器 AGG(expr) FILTER(WHERE whereExpr) 。过滤的聚合器仅聚合与其过滤器匹配的行。同一SQL查询中的两个聚合器可能具有不同的筛选器。
只有COUNT聚合可以接受DISTINCT。

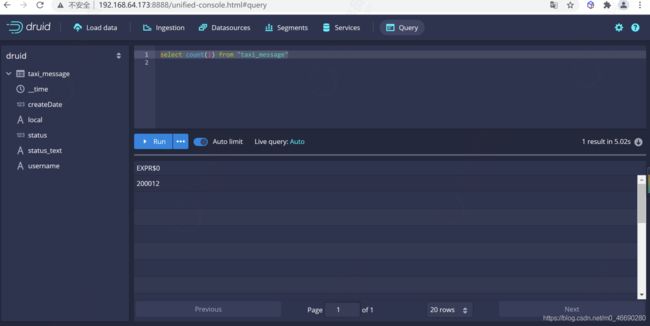
查询数据总条数
可以在druid的控制台进行查询
select count(1) from "taxi_message"
5.7 客户端API
我们在这里实现SpringBoot+Mybatis实现SQL查询ApacheDruid数据
5.7.1 引入Pom依赖
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.2.0version>
dependency>
<dependency>
<groupId>org.apache.calcite.avaticagroupId>
<artifactId>avaticaartifactId>
<version>1.18.0version>
dependency>
<dependency>
<groupId>org.apache.calcite.avaticagroupId>
<artifactId>avatica-serverartifactId>
<version>1.18.0version>
dependency>
dependencies>
配置数据源连接
在application.yml中配置数据库的连接信息
连接时需注意Druid时区和JVM时区,不设置时区时默认采用JVM时区
文档参考地址:https://calcite.apache.org/avatica/docs/client_reference.html
spring:
datasource:
# 连接池信息
url: jdbc:avatica:remote:url=http://192.168.64.177:8082/druid/v2/sql/avatica/
# 驱动信息
driver-class-name: org.apache.calcite.avatica.remote.Driver
编写代码
@Data
@ToString
public class TaxiMessage {
private String __time;
private Integer age;
private Integer createDate;
private String local;
private String sex;
private Integer status;
private String statusText;
private String username;
}
编写mapper
所有字段名、表名必须使用如下方式标识 “表名”
@Mapper
public interface TaxiMessageMapper {
@Select("SELECT * FROM \"taxi_message\" where username=#{username}")
public TaxiMessage findByUserName(String username);
}
编写Service
@Service
public class TaxiMessageService {
@Autowired
private TaxiMessageMapper taxiMessageMapper;
public TaxiMessage findByUserName(String username) {
return taxiMessageMapper.findByUserName(username);
}
}
编写启动类
@SpringBootApplication
@MapperScan(basePackages = "com.druid.mapper")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}
** 编写测试类**
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class DruidTest {
@Autowired
private TaxiMessageService taxiMessageService;
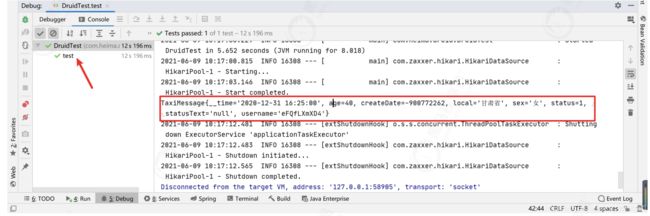
@Test
public void test() {
TaxiMessage taxiMessage = taxiMessageService.findByUserName("eFQfLXmXD4");
System.out.println(taxiMessage);
Assert.assertNotNull(taxiMessage);
}
}