爬虫-python -(7) post中data加密 requet进阶
文章目录
- 1.爬虫-网易云评论
-
- 1.直接通过post的表单数据得到评论
- 2.data加密过程解析
- 2.总结
1.爬虫-网易云评论
1.直接通过post的表单数据得到评论
首先随便打开一个音乐
锦里-HOPE-T / 接个吻,开一枪
获取以下位置文字

查找文字是没有在源代码里面,所以肯定是后面加载的,所以需要从网络的XHR里面寻找。
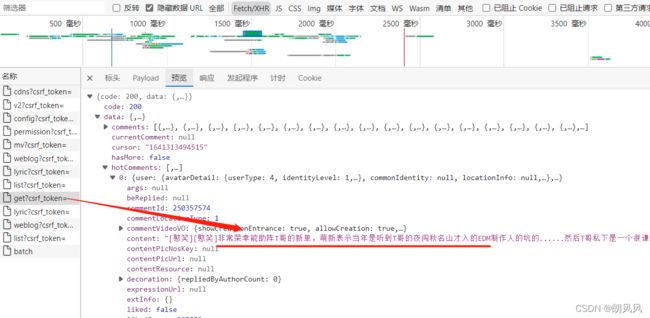
最终在这里找到,可以知道是通过post请求得到,需要知道表单也就是data数据,
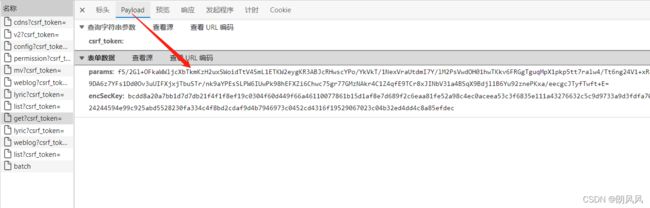
现在可以直接通过request.post 可以直接得到评论。
import requests
url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token='
data = {'params': 'fS/2Gl+OFkaWWljcXbTkmKzH2uxSWoidTtV4SmL1ETKW2eygKR3ABJcRHwscYPo/YkVkT/1NexVraUtdmI7Y/lM2PsVwdOH01hwTKkv6FRGgTguqMpX1pkp5tt7ralw4/Tt6ng24V1+xR8lAGTJMd0u+0cjjyD6iAa9DA6z7YFs1Dd0Ov3uUIFXjxjTbuSTr/nk9aYPEsSLPW6IUwPk98hEFXZi6Chwc75gr77GMzNAkr4C1Z4qfE9TCr8xJINbV31a4BSqX9Bdjl1B6Yu92znePKxa/eecgcJTyfTwft+E=',
'encSecKey':'bcdd8a20a7bb1d7d7db21f4f1f8ef19c0304f60d449f66a46110077861b15d1af8e7d689f2c6eaa81fe52a98c4ec0aceea53c3f6835e111a43276632c5c9d9733a9d3fdfa70309471b98abc6cf4ad7c24244594e99c925abd5528230fa334c4f8bd2cdaf9d4b7946973c0452cd4316f19529067023c04b32ed4dd4c8a85efdec'}
resp = requests.post(url, data=data)
respconter = resp.json()['data']['hotComments']
resp.close()
index= 0
for i in respconter:
print(index,i['content'])
index+=1
2.data加密过程解析
以上这样随便比较简单,但是换个网站就不能用了,现在就是要找到一个通用的,需要了解data数据很长码加密过程,然后通过py模拟,然后再写入data。
首先需要从调用堆栈里面找到,加密函数

需要在最后的函数输出点,加入断点,然后刷新网站,找对对应网站访问,


直到找到刚刚post的那个网站,然后从这个位置开始往上找data,
直到没有上面没有data,下一步恰好出现data,说明在这个恰好出现data函数这部分,加密了。
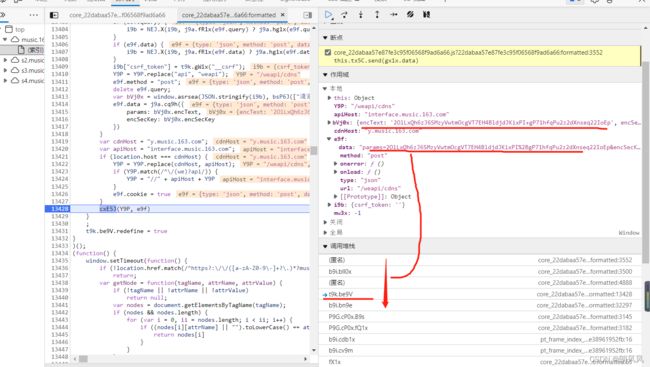
在这个函数体开始加入断点,从新刷新网站,找到读取对应网站,从这个函数开始一步步往下,直至找到加密函数。
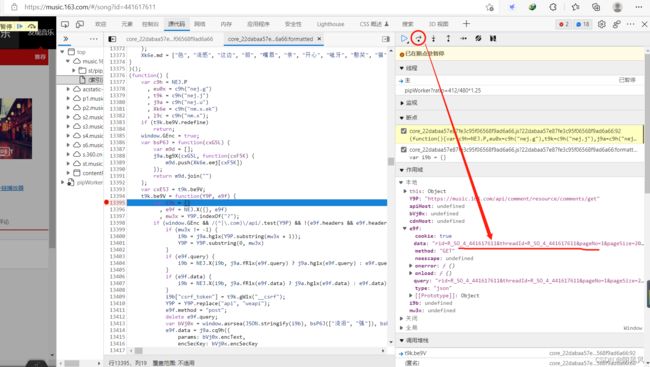
这一步执行完毕出现一个字典,字典内元素就是data的加密数据。说明这个函数实现了加密过程。

通过搜索找到实际函数位置。
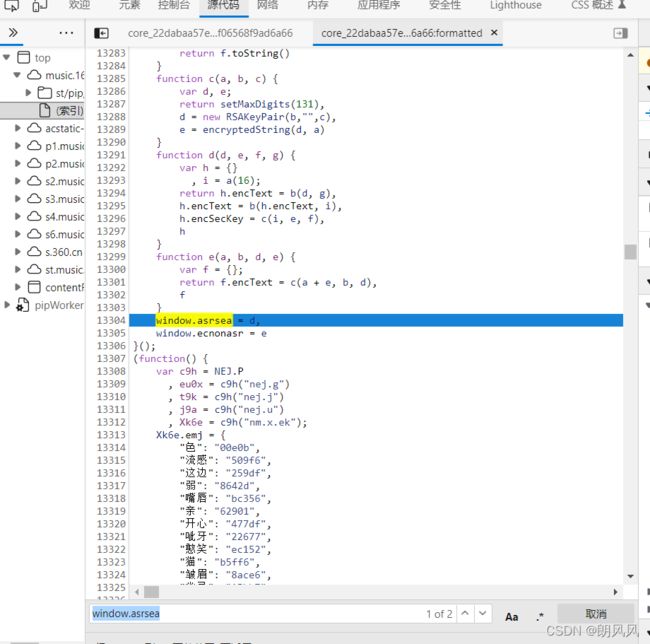
这里有个小技巧,就是固定值输入的函数,多次重复实现没有变化,说明输出也是固定值,就可以把它确定下来,可以在控制台里面测试这个函数,

后面就不再赘叙,直接开搞,
import requests
from Crypto.Cipher import AES
import base64
import json
"""
function a(a) { #产生16位随机字符串
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {%encSecKey
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
var bVj0x = window.asrsea(JSON.stringify(i9b), bsP6J(["流泪", "强"]), bsP6J(Xk6e.md), bsP6J(["爱心", "女孩", "惊恐", "大笑"]));
"""
id= '1830876799' #网站后缀 可遍历主页 以及子页找到这个网站
data = {
'csrf_token': "", #可以设置里面参数
'cursor': "-1",
'offset': "0",
'orderType': "1",
'pageNo': "1",
'pageSize': "20",
'rid': "R_SO_4_"+id,
'threadId': "R_SO_4_"+id
}
url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token='
e = '010001'
f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
g = '0CoJUm6Qyw8W8jud'
i = "vW4CviGtDxA8It3G" #手动固定-》知道和那个对应
#encSecKey 加密起来太麻烦了 直接把随机16个字符串固定 然后输出固定的encSecKey
def get_encSecKey():
return '74b3073f5347d351734c794350b873c65585bed7938f0ed668b9d6c7fe76d03101a2313b9906685ca381460a2991c65a39ca8f951c43870fbe71e50e97d2482f07c74a01301b04b814f9776328f2bfc95733ee738ca3d91c3e954a17cc03eb51c55085c2928fd8306fbc4d2c2240313a01fc252af8e4b39ae4867bc864d61796'
# 加密函数
def enc_params(data,key):
BLOCK_SIZE = 16
iv = '0102030405060708'
aes = AES.new(key=key.encode('utf-8'), mode=AES.MODE_CBC, IV=iv.encode('utf-8')) #创建加密器 mode:模式 iv:偏移量
x = data + (BLOCK_SIZE - len(data) % BLOCK_SIZE) * chr(BLOCK_SIZE - len(data) % BLOCK_SIZE) #AES 要求长度为16 不足16位的倍数就用空格补足为16位
x = x.encode()
bs = aes.encrypt(x) #加密
return str(base64.b64encode(bs),'utf-8')#转化成字符串返回
def get_params(data):
first = enc_params(data,g)
second= enc_params(first,i)
return second
data = {
'params': get_params(json.dumps(data)),
'encSecKey':get_encSecKey()
}
resp = requests.post(url, data=data)
respconter = resp.json()['data']['hotComments']
resp.close()
index= 0
for i in respconter:
print(index,i['content'])
index+=1
2.总结
请求的post加密。我还是第一次遇到,这种方法其实蛮有意思,以后遇见这样的事情,可以参照今天的模板。