PyTorch深度学习实践---笔记
PyTorch深度学习实践---笔记
- 2.线性模型(Linear Model)
-
- 2.exercise
- 3. 梯度下降算法(Gradient Descent)
-
- 3.1梯度下降(Gradient Descent)
- 3.2 随机梯度下降(Stochastic Gradient Descent)
- 4. 反向传播(Back Propagation)
- 5. 用PyTorch实现线性回归
- 6. 逻辑回归(Logistics Regression)
- 7. 处理多维特征的输入(Multiple Dimension Input)
- 8. 加载数据集
- 9. 多分类问题
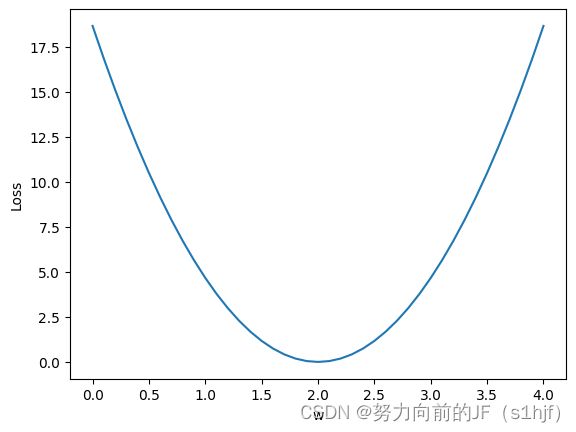
2.线性模型(Linear Model)
import numpy as np
import matplotlib.pyplot as plt
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
def forward(x):
return x*w
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)*(y_pred-y)
w_list=[]
mse_list=[]
for w in np.arange(0.0,4.1,0.1):
print('w=',w)
l_sum=0
for x_val,y_val in zip(x_data,y_data):
y_pred_val=forward(x_val)
loss_val=loss(x_val,y_val)
l_sum+=loss_val
print('\t',x_val,y_val,y_pred_val,loss_val)
print('MSE=',l_sum/3)
w_list.append(w)
mse_list.append(l_sum/3)
plt.plot(w_list,mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
Exercise:
[Link](The mplot3d toolkit — Matplotlib 3.7.1 documentation)
[docs](numpy.meshgrid — NumPy v1.25 Manual)
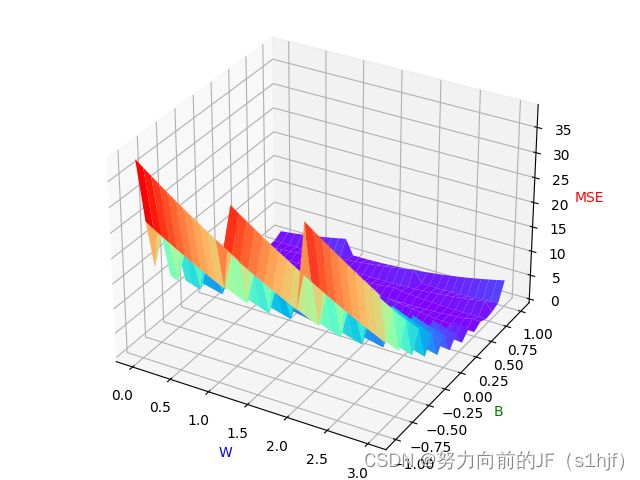
2.exercise
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
%matplotlib notebook
x_data=[1.0,2.0,3.0]
y_data=[3.0,5.0,7.0]
def forward(x):
return x*w+b
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)*(y_pred-y)
w_list=[]
mse_list=[]
b_list=[]
for w in np.arange(0.0,3.1,0.1):
for b in np.arange(-1,1.1,0.1):
print('w=',w)
print('b=',b)
l_sum=0
for x_val,y_val in zip(x_data,y_data):
y_pred_val=forward(x_val)
loss_val=loss(x_val,y_val)
l_sum+=loss_val
print('\t',x_val,y_val,y_pred_val,loss_val)
print('MSE=',l_sum/3)
w_list.append(w)
b_list.append(b)
mse_list.append(l_sum/3)
W=np.array(w_list)
W=np.unique(W)
B=np.array(b_list)
B=np.unique(B)
MSE=np.array(mse_list)
W,B=np.meshgrid(W,B)
MSE=MSE.reshape(21,31)
fig=plt.figure()
ax=Axes3D(fig)
ax.plot_surface(W, B, MSE, cmap='rainbow')
ax.set_xlabel('W', color='b')
ax.set_ylabel('B', color='g')
ax.set_zlabel('MSE', color='r')
plt.show()
3. 梯度下降算法(Gradient Descent)
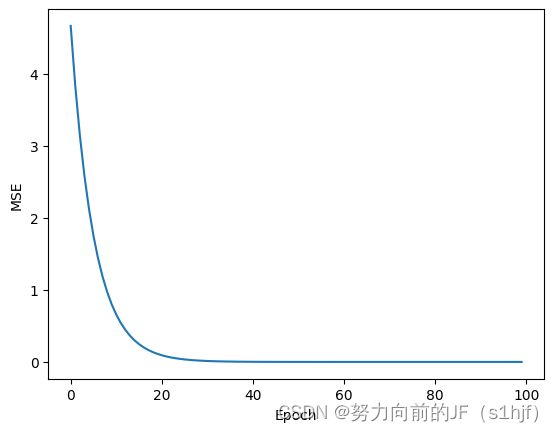
3.1梯度下降(Gradient Descent)
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost / len(xs)
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
print('Predict(before training)', 4, forward(4))
cost_list = []
epoch_list = []
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
cost_list.append(cost_val)
epoch_list.append(epoch)
print('Epoch:', epoch, 'w=', w, 'loss', cost_val)
print('Predict(after training)', 4, forward(4))
plt.plot(epoch_list, cost_list)
plt.xlabel('Epoch')
plt.ylabel('MSE')
plt.show()
3.2 随机梯度下降(Stochastic Gradient Descent)
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
def gradient(x, y):
return 2 * x * (x * w - y)
print('Predict(before training)', 4, forward(4))
loss_list = []
epoch_list = []
for epoch in range(100):
for x, y in zip(x_data, y_data):
grad = gradient(x, y)
w -= 0.01 * grad
print("\tgrad:", x, y, grad)
l = loss(x, y)
print("progress:", epoch, "w=", w, "loss=", l)
epoch_list.append(epoch)
loss_list.append(l)
print('Predict(after training)', 4, forward(4))
plt.plot(epoch_list, loss_list)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
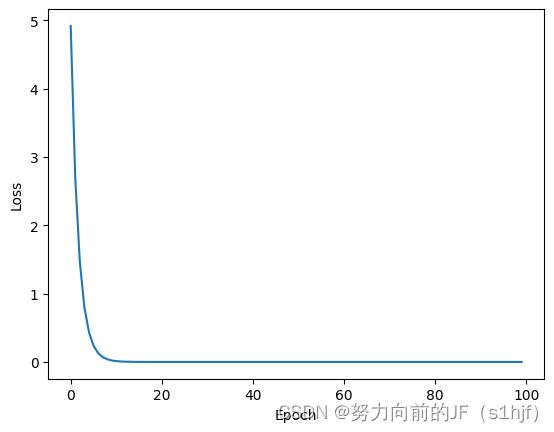
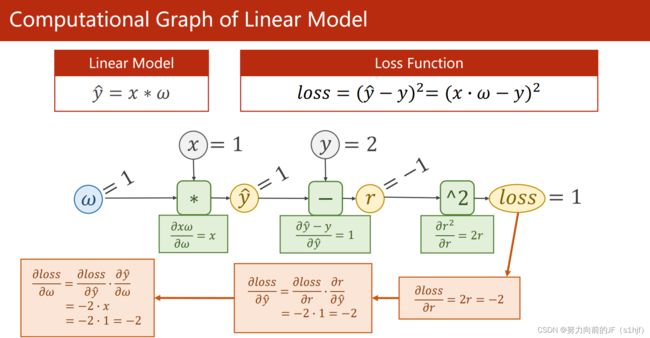
4. 反向传播(Back Propagation)
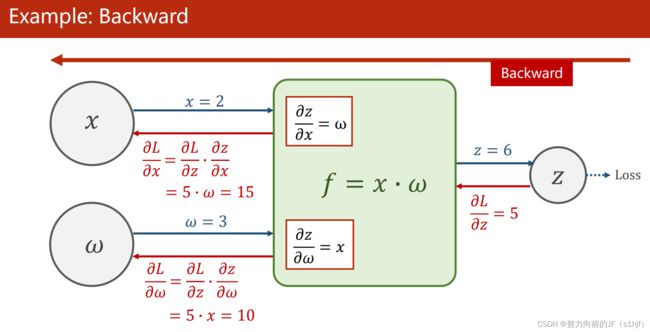
Example 1:
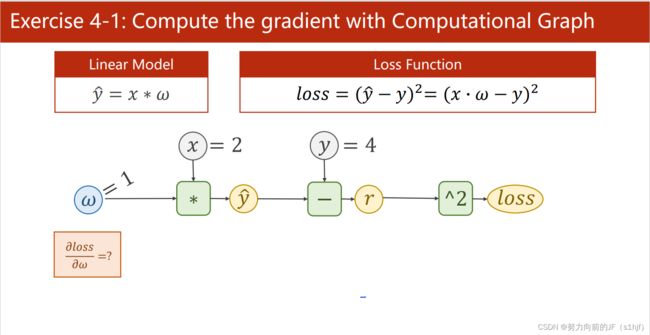
Exercise 4-1:Answer=-8
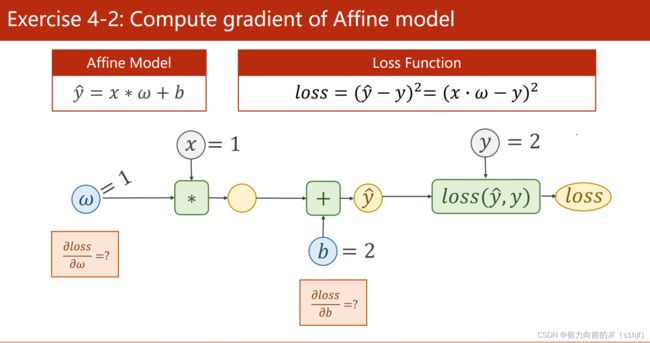
Exercise 4-2 Answer.1=2,Answer.2=2
import torch
from matplotlib import pyplot as plt
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
w=torch.Tensor([1.0])
w.requires_grad=True
def forward(x):
return x*w
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)**2
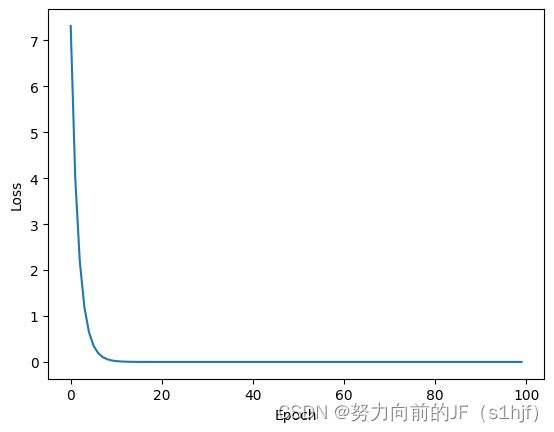
print("predict (before training)",4,forward(4).item)
epoch_list=[]
MSE_list=[]
for epoch in range(100):
epoch_list.append(epoch)
for x,y in zip(x_data,y_data):
l=loss(x,y)
l.backward()
print('\tgrad:',x,y,w.grad.item())
w.data=w.data-0.01*w.grad.data
w.grad.data.zero_()
print("progress:",epoch,l.item())
MSE_list.append(l.item())
print("prdict (after training)",4,forward(4).item())
plt.plot(epoch_list,MSE_list)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.set_tittle("PyTorch")
plt.show()

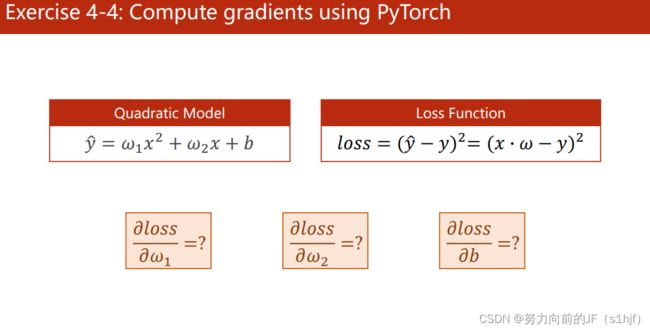
Answer.1:
∂ L o s s ∂ w 1 = 2 ∗ ( w 1 ∗ x 2 + w 2 ∗ x + b − y ) ∗ x 2 \frac{\partial Loss}{\partial w_1}=2*(w_1*x^2+w_2*x+b-y)*x^2 ∂w1∂Loss=2∗(w1∗x2+w2∗x+b−y)∗x2
Answer.2:
∂ L o s s ∂ w 2 = 2 ∗ ( w 1 ∗ x 2 + w 2 ∗ x + b − y ) ∗ x \frac {\partial Loss}{\partial w_2}=2*(w_1*x^2+w_2*x+b-y)*x ∂w2∂Loss=2∗(w1∗x2+w2∗x+b−y)∗x
Answer.3:
∂ L o s s ∂ b = 2 ∗ ( w 1 ∗ x 2 + w 2 ∗ x + b − y ) \frac {\partial Loss}{\partial b}=2*(w_1*x^2+w_2*x+b-y) ∂b∂Loss=2∗(w1∗x2+w2∗x+b−y)
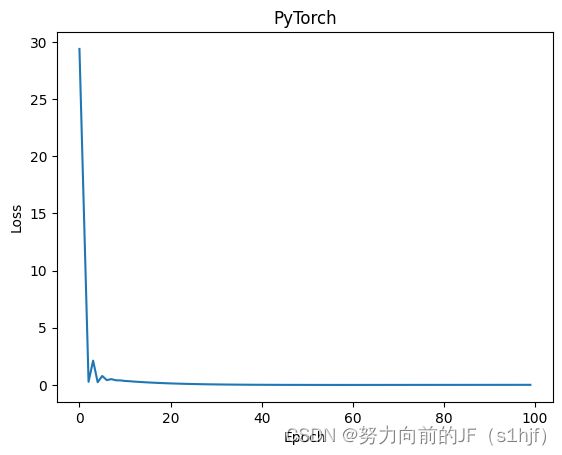
import torch
from matplotlib import pyplot as plt
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
w_1=torch.Tensor([1.0])
w_1.requires_grad=True
w_2=torch.Tensor([2.0])
w_2.requires_grad=True
b=torch.Tensor([3.0])
b.requires_grad=True
def forward(x):
return w_1*(x**2)+w_2*x+b
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)**2
print("predict (before training)",4,forward(4).item)
epoch_list=[]
MSE_list=[]
for epoch in range(100):
epoch_list.append(epoch)
for x,y in zip(x_data,y_data):
l=loss(x,y)
l.backward()
print('\tgrad:','X:',x,'Y:',y,w_1.grad.item(),w_2.grad.item(),b.grad.item())
w_1.data=w_1.data-0.01*w_1.grad.data
w_2.data=w_2.data-0.01*w_2.grad.data
b.data=b.data-0.01*b.grad.data
w_1.grad.data.zero_()
w_2.grad.data.zero_()
b.grad.data.zero_()
print("progress:",epoch,l.item())
MSE_list.append(l.item())
print("prdict (after training)",4,forward(4).item(),'w_1=',w_1.item(),'w_2=',w_2.item(),'b=',b.data.item())
plt.plot(epoch_list,MSE_list)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title("PyTorch")
plt.show()
5. 用PyTorch实现线性回归
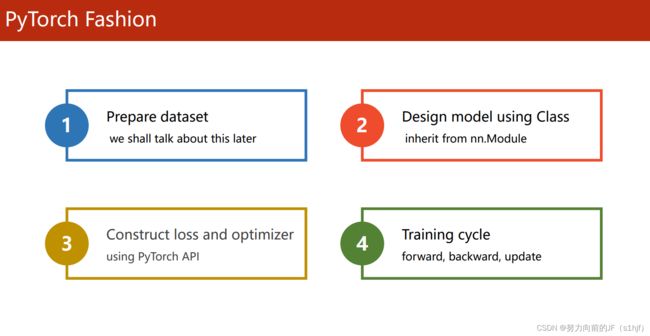
前馈->反馈->更新
前馈算损失,反馈算梯度,然后更新,反反复复

import torch
x_data=torch.Tensor([[1.0],[2.0],[3.0]])
y_data=torch.Tensor([[2.0],[4.0],[6.0]])
class LinearModel(torch.nn.Module):#LinearModel相当于是继承torch.nn.Module的子类
def __init__(self):#Python中类的初始化都是__init__()
super(LinearModel,self).__init__()#继承父类的__init__方法,在__init__初始化方法后还想继承父类的__init__(),就在子类中使用super()函数
self.linear=torch.nn.Linear(1,1)#定义子类的linear属性
def forward(self,x):
y_pred=self.linear(x)#调用子类的linear属性
return y_pred
model=LinearModel()#创建类LinearModel的实例
criterion=torch.nn.MSELoss(reduction='sum')#损失函数
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)#优化器
for epoch in range(1000):#训练迭代
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()#梯度清零
loss.backward()#反向传播
optimizer.step()#计算梯度,梯度更新
print('w =',model.linear.weight.item())
print('b =',model.linear.bias.item())
x_test=torch.Tensor([4.0])
y_test=model(x_test)
print('y_pred =',y_test.data)
这篇文章可以帮助理解LinearModel的写法
python类中super()_wanghua609的博客-CSDN博客
6. 逻辑回归(Logistics Regression)
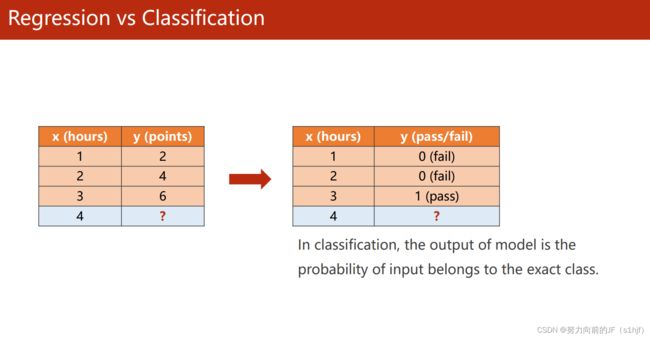
逻辑回归主要用于分类问题,线性回归的输出值是连续空间
Classification Problem
类别之间没有大小关系
分类问题的输出是一个概率问题,为Ⅰ类的概率是多少,为Ⅱ类的概率是多少…
根据概率值的最大值判断所属类别。
实际上计算的就是 y_hat=1 的概率。
要将输出值映射到【0,1】,因为概率值是在【0,1】的。
Sigmoid函数也是一种饱和函数(输入值x大于某个值后,输出值y基本不变)。
sigmoid函数中最出名的函数就是Logistics函数,因此大多数书籍资料中将Logistics函数成为sigmoid函数。
σ()就是sigmoid函数。

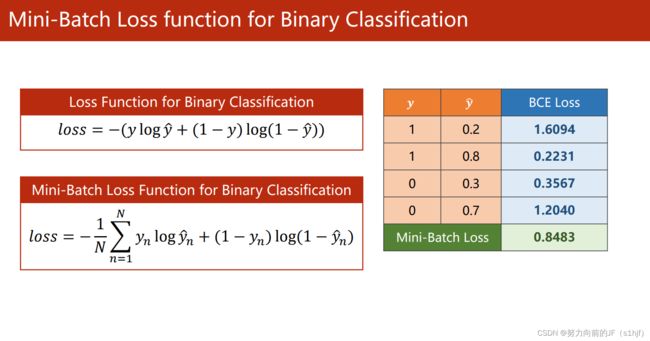
计算分布之间的差异。
这个用于二分类的函数,叫做BCE函数。(CE:cross-entropy)
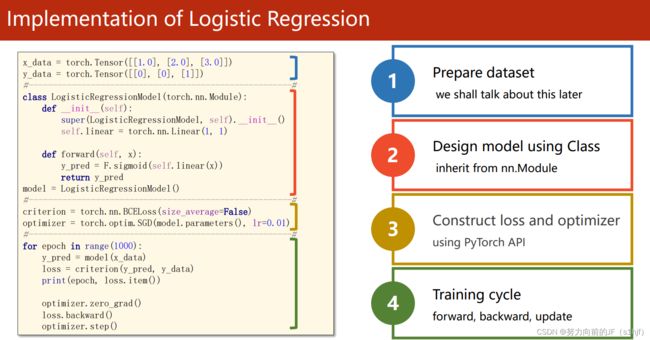
#torch.nn.Functional.sigmoid() use torch.sigmoid() instead.
import torch
import numpy as np
import matplotlib.pyplot as plt
x_data=torch.Tensor([[1.0],[2.0],[3.0]])
y_data=torch.Tensor([[0],[0],[1]])
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel,self).__init__()
self.linear=torch.nn.Linear(1,1)
def forward(self,x):
y_pred=torch.sigmoid(self.linear(x))
return y_pred
model=LogisticRegressionModel()
criterion=torch.nn.BCELoss(reduction='sum')
#size_average=True
#size_average and reduce args will be deprecated,
#please use reduction='mean' instead.
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(1000):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
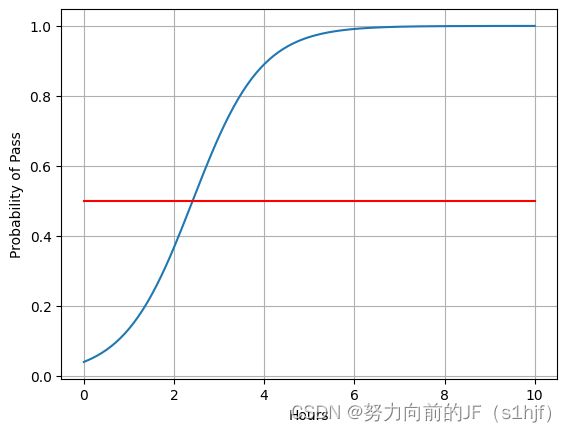
x=np.linspace(0,10,200)
x_t=torch.Tensor(x).view((200,1))
y_t=model(x_t)
y=y_t.data.numpy()
plt.plot(x,y)
plt.plot([0,10],[0.5,0.5],c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()
7. 处理多维特征的输入(Multiple Dimension Input)
输入值有多个特征
每一行成为Record, 每一列叫做Feature(特征/字段),结构化的数据。
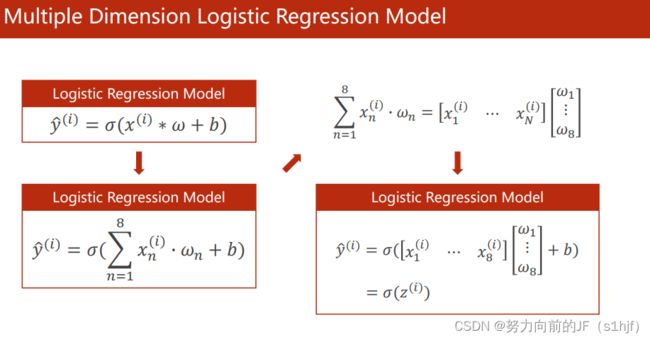
每一个特征值都要与一个权重相乘,x看成一个向量,乘上w1到w8,标量转置相乘做内积。
σ就是sigmoid函数。
计算转化成向量化的运算,然后通过并行计算,通过GPU的能力,提高运算速度。
矩阵可以看作是空间变换的函数。


从8个特征(8维)学到6个特征(6维)再到4个特征,最后到1个特征。
当然也可以直接从8个特征学到1个特征
import numpy as np
import torch
import matplotlib.pyplot as plt
xy = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]])
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epoch_list = []
loss_list = []
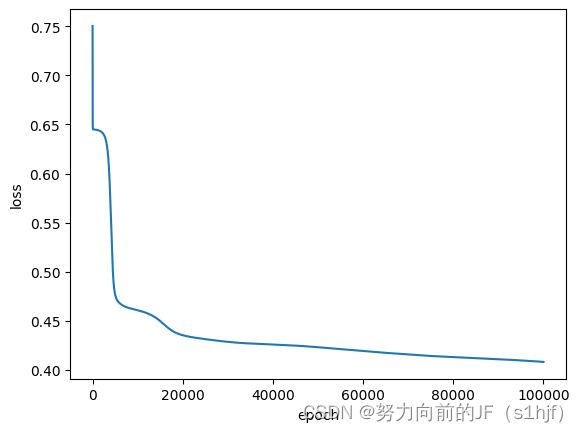
for epoch in range(100000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
8. 加载数据集
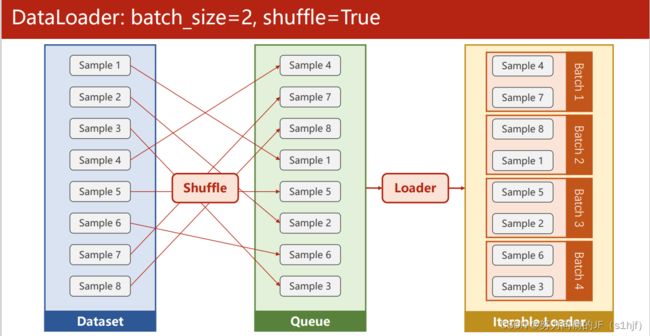
Dataset主要用于构建数据集,支持索引(利用下标)
Dataloader主要用于Mini-Batch


笔记来源:《PyTorch深度学习实践》完结合集
9. 多分类问题
输出时,每一个输出代表每种标签的概率。属于1的概率是多少,属于2的概率是多少,等等。各个输出值大于0,且值得的合等于1。
本笔记来自:【《PyTorch深度学习实践》完结合集】 https://www.bilibili.com/video/BV1Y7411d7Ys/?share_source=copy_web&vd_source=292129053a8880be150381f42c6b50c4