YOLOv5、v8改进:引入SKAttention注意力机制
目录
1.简介
2.YOLOv5改进
2.1增加以下SKAttention.yaml文件
2.2common.py配置
2.3yolo.py配置
1.简介
论文链接:https://arxiv.org/pdf/1903.06586.pdf
最近对卷积神经网络中的“自适应调整感受野”这样的操作很感兴趣,从字面的意思可以理解:如果可以自适应的调整感受野的大小,其背后说得应该就是自适应的选择卷积核的大小。看上去不难理解,但是仔细想想,大多的网络模型,他的BankBone和Neck和Prediction三个网络组成了神经网络,作为特征提取,卷积核是关键因素,卷积核都是固定设置的,那么如何做到对于输入的特征图,做到自适应的选择卷积核。所以就有了很多的疑惑。并且这项工作在前几年就有人提出,比如我最近看了一篇SKAttention注意力,其中就用到了自适应的选择卷积核去调整感受野。比如动态卷积,同样是抛弃传统的固定卷积核,选择动态的卷积核来做特征提取。
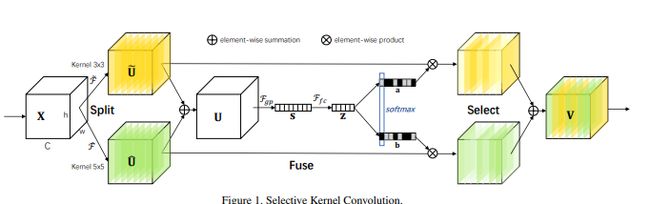
由于不同大小的感受野对于不同尺度的目标有不同的效果,论文目的是使得网络可以自动地利用对分类有效的感受野捕捉到的信息。为了解决这个问题,作者提出了一种新的深度结构在CNN中对卷积核的动态选择机制,该机制允许每个神经元根据输入信息的多尺度自适应地调整其感受野(卷积核)的大小。称为“选择性核(Selective Kernel)”,它可以更好地捕捉复杂图像空间的多尺度特征,而不会像一般的CNN那样浪费大量的计算资源。SKN的另一个优点是它可以聚合深度特征,使它更容易理解,同时也允许更好的可解释性。其灵感来源是,我们在看不同尺寸不同远近的物体时,视觉皮层神经元接受域大小是会根据刺激来进行调节的。具体是设计了一个称为选择性内核单元(SK)的构建块,其中,多个具有不同内核大小的分支在这些分支中的信息引导下,使用SoftMax进行融合。由多个SK单元组成SKNet,SKNet中的神经元能够捕获不同尺度的目标物体。
SKNet网络主要分为Split,Fuse,Select三个操作。Split算子产生多条不同核大小的路径,上图中的模型只设计了两个不同大小的卷积核,实际上可以设计多个分支的多个卷积核。fuse运算符结合并聚合来自多个路径的信息,以获得用于选择权重的全局和综合表示。select操作符根据选择权重聚合不同大小内核的特征图。
总的来说,SKN结构的优势是它可以更有效地捕捉图像空间。

作为即插即用的注意力模块,可以添加到YOLOv5网络中的任何地方。
2.YOLOv5改进
2.1增加以下SKAttention.yaml文件
# YOLOv5 by YOLOAir, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOAir head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
# [-1, 1, SKAttention, [256]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, SKAttention, [1024]], #修改
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.2common.py配置
./models/common.py文件增加以下模块
class SKAttention(nn.Module):
def __init__(self, channel=512,kernels=[1,3,5,7],reduction=16,group=1,L=32):
super().__init__()
self.d=max(L,channel//reduction)
self.convs=nn.ModuleList([])
for k in kernels:
self.convs.append(
nn.Sequential(OrderedDict([
('conv',nn.Conv2d(channel,channel,kernel_size=k,padding=k//2,groups=group)),
('bn',nn.BatchNorm2d(channel)),
('relu',nn.ReLU())
]))
)
self.fc=nn.Linear(channel,self.d)
self.fcs=nn.ModuleList([])
for i in range(len(kernels)):
self.fcs.append(nn.Linear(self.d,channel))
self.softmax=nn.Softmax(dim=0)
def forward(self, x):
bs, c, _, _ = x.size()
conv_outs=[]
### split
for conv in self.convs:
conv_outs.append(conv(x))
feats=torch.stack(conv_outs,0)#k,bs,channel,h,w
### fuse
U=sum(conv_outs) #bs,c,h,w
### reduction channel
S=U.mean(-1).mean(-1) #bs,c
Z=self.fc(S) #bs,d
### calculate attention weight
weights=[]
for fc in self.fcs:
weight=fc(Z)
weights.append(weight.view(bs,c,1,1)) #bs,channel
attention_weughts=torch.stack(weights,0)#k,bs,channel,1,1
attention_weughts=self.softmax(attention_weughts)#k,bs,channel,1,1
### fuse
V=(attention_weughts*feats).sum(0)
return V
2.3yolo.py配置
在 models/yolo.py文件夹下
- 定位到parse_model函数中,注册以下代码
elif m is SKAttention:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, *args[1:]]
有遇到问题的小伙伴欢迎评论区留言!