场景应用题目常见面试真题详解
文章目录
- 1. 场景应用
-
- 1.1 微信红包相关问题
- 1.2 秒杀系统相关问题
- 1.3 扫码登录流程
- 1.4 如何实现单点登录?
- 1.5 如何设计一个本地缓存?
1. 场景应用
1.1 微信红包相关问题
参考答案
概况:2014年微信红包使用数据库硬抗整个流量,2015年使用cache抗流量。
微信的金额什么时候算?
微信红包的金额是拆的时候实时算出来,不是预先分配的,采用的是纯内存计算,不需要预算空间存储。采取实时计算金额的考虑,是因为实时效率很高,而预算需要占存储,预算空间效率低。
为什么明明抢到红包,点开后发现没有?
2014年的红包一点开就知道金额,分两次操作,先抢到金额,然后再转账。2015年的红包的拆和抢是分离的,需要点两次,因此会出现抢到红包了,但点开后告知红包已经被领完的状况。进入到第一个页面不代表抢到,只表示当时红包还有。
红包里的金额怎么算?为什么出现各个红包金额相差很大?
随机,额度在0.01和剩余平均值*2之间。
例如:发100块钱,总共10个红包,那么平均值是10块钱一个,那么发出来的红包的额度在0.01元~20元之间波动。当前面3个红包总共被领了40块钱时,剩下60块钱,总共7个红包,那么这7个红包的额度在:0.01~(60/7*2)=17.14之间。
注意:这里的算法是每被抢一个后,剩下的会再次执行上面的这样的算法。这样算下去,会超过最开始的全部金额,因此到了最后面如果不够这么算,那么会采取如下算法:保证剩余用户能拿到最低1分钱即可。如果前面的人手气不好,那么后面的余额越多,红包额度也就越多,因此实际概率一样的。
红包的设计
微信从财付通拉取金额数据过来,生成个数/红包类型/金额放到redis集群里,app端将红包ID的请求放入请求队列中,如果发现超过红包的个数,直接返回。根据红包的逻辑处理成功得到令牌请求,则由财付通进行一致性调用,通过像比特币一样,两边保存交易记录,交易后交给第三方服务审计,如果交易过程中出现不一致就强制回归。
红包如何计算被抢完?
cache会抵抗无效请求,将无效的请求过滤掉,实际进入到后台的量不大。cache记录红包个数,原子操作进行个数递减,到0表示被抢光。财付通按照20万笔每秒入账准备,但实际还不到8万每秒。
通如何保持8w每秒的写入?
多主sharding,水平扩展机器。
据容量多少?
一个红包只占一条记录,有效期只有几天,因此不需要太多空间。
查询红包分配,压力大不?
抢到红包的人数和红包都在一条cache记录上,没有太大的查询压力。
一个红包一个队列?
没有队列,一个红包一条数据,数据上有一个计数器字段。
有没有从数据上证明每个红包的概率是不是均等?
不是绝对均等,就是一个简单的拍脑袋算法。
拍脑袋算法,会不会出现两个最佳?
会出现金额一样的,但是手气最佳只有一个,先抢到的那个最佳。
每领一个红包就更新数据么?
每抢到一个红包,就cas更新剩余金额和红包个数。
红包如何入库入账?
数据库会累加已经领取的个数与金额,插入一条领取记录,入账则是后台异步操作。
入帐出错怎么办?比如红包个数没了,但余额还有?
最后会有一个take all操作,另外还有一个对账来保障。
1.2 秒杀系统相关问题
参考答案
秒杀应该考虑哪些问题?
-
超卖问题
分析秒杀的业务场景,最重要的有一点就是超卖问题,假如备货只有100个,但是最终超卖了200,一般来讲秒杀系统的价格都比较低,如果超卖将严重影响公司的财产利益,因此首当其冲的就是解决商品的超卖问题。
-
高并发
秒杀具有时间短、并发量大的特点,秒杀持续时间只有几分钟,而一般公司都为了制造轰动效应,会以极低的价格来吸引用户,因此参与抢购的用户会非常的多。短时间内会有大量请求涌进来,后端如何防止并发过高造成缓存击穿或者失效,击垮数据库都是需要考虑的问题。
-
接口防刷
现在的秒杀大多都会出来针对秒杀对应的软件,这类软件会模拟不断向后台服务器发起请求,一秒几百次都是很常见的,如何防止这类软件的重复无效请求,防止不断发起的请求也是需要我们针对性考虑的。
-
秒杀URL
对于普通用户来讲,看到的只是一个比较简单的秒杀页面,在未达到规定时间,秒杀按钮是灰色的,一旦到达规定时间,灰色按钮变成可点击状态。这部分是针对小白用户的,如果是稍微有点电脑功底的用户,会通过F12看浏览器的network看到秒杀的url,通过特定软件去请求也可以实现秒杀。或者提前知道秒杀url的人,一请求就直接实现秒杀了。这个问题我们需要考虑解决。
-
数据库设计
秒杀有把我们服务器击垮的风险,如果让它与我们的其他业务使用在同一个数据库中,耦合在一起,就很有可能牵连和影响其他的业务。如何防止这类问题发生,就算秒杀发生了宕机、服务器卡死问题,也应该让他尽量不影响线上正常进行的业务。
秒杀系统的设计方案
-
秒杀系统的数据库设计
针对秒杀的数据库问题,应该单独设计一个秒杀数据库,防止因为秒杀活动的高并发访问拖垮整个网站。这里只需要两张表,一张是秒杀订单表,一张是秒杀货品表:


其实应该还有几张表,商品表:可以关联goods_id查到具体的商品信息,商品图像、名称、平时价格、秒杀价格等,还有用户表:根据用户user_id可以查询到用户昵称、用户手机号,收货地址等其他额外信息,这个具体就不给出实例了。
-
秒杀URL的设计
为了避免有程序访问经验的人通过下单页面url直接访问后台接口来秒杀货品,我们需要将秒杀的url实现动态化,即使是开发整个系统的人都无法在秒杀开始前知道秒杀的url。具体的做法就是通过md5加密一串随机字符作为秒杀的url,然后前端访问后台获取具体的url,后台校验通过之后才可以继续秒杀。
-
秒杀页面静态化
将商品的描述、参数、成交记录、图像、评价等全部写入到一个静态页面,用户请求不需要通过访问后端服务器,不需要经过数据库,直接在前台客户端生成,这样可以最大可能的减少服务器的压力。具体的方法可以使用freemarker模板技术,建立网页模板,填充数据,然后渲染网页。
-
单体redis升级为集群redis
秒杀是一个读多写少的场景,使用redis做缓存再合适不过。不过考虑到缓存击穿问题,我们应该构建redis集群,或采用哨兵模式,可以提升redis的性能和可用性。
-
使用nginx
nginx是一个高性能web服务器,它的并发能力可以达到几万,而tomcat只有几百。通过nginx映射客户端请求,再分发到后台tomcat服务器集群中可以大大提升并发能力。
-
精简SQL
典型的一个场景是在进行扣减库存的时候,传统的做法是先查询库存,再去update。这样的话需要两个sql,而实际上一个sql我们就可以完成的。可以用这样的做法:
update miaosha_goods set stock=stock-1 where goos_id={#goods_id} and version=#{version} and sock>0;。这样的话,就可以保证库存不会超卖并且一次更新库存,还有注意一点这里使用了版本号的乐观锁,相比较悲观锁,它的性能较好。 -
redis预减库存
很多请求进来,都需要后台查询库存,这是一个频繁读的场景。可以使用redis来预减库存,在秒杀开始前可以在redis设值,比如
redis.set(goodsId,100),这里预放的库存为100可以设值为常量),每次下单成功之后,Integer stock = (Integer)redis.get(goosId);然后判断sock的值,如果小于常量值就减去1。不过注意当取消的时候,需要增加库存,增加库存的时候也得注意不能大于之间设定的总库存数(查询库存和扣减库存需要原子操作,此时可以借助lua脚本)下次下单再获取库存的时候,直接从redis里面查就可以了。 -
接口限流
秒杀最终的本质是数据库的更新,但是有很多大量无效的请求,我们最终要做的就是如何把这些无效的请求过滤掉,防止渗透到数据库。限流的话,需要入手的方面很多:
- 前端限流:首先第一步就是通过前端限流,用户在秒杀按钮点击以后发起请求,那么在接下来的5秒是无法点击(通过设置按钮为disable)。这一小举措开发起来成本很小,但是很有效。
- 同一个用户x秒内重复请求直接拒绝:具体多少秒需要根据实际业务和秒杀的人数而定,一般限定为10秒。具体的做法就是通过redis的键过期策略,首先对每个请求都从
String value = redis.get(userId);。如果获取到这个value为空或者为null,表示它是有效的请求,然后放行这个请求。如果不为空表示它是重复性请求,直接丢掉这个请求。如果有效,采用redis.setexpire(userId,value,10).value可以是任意值,一般放业务属性比较好,这个是设置以userId为key,10秒的过期时间(10秒后,key对应的值自动为null)。 - 令牌桶算法限流:接口限流的策略有很多,我们这里采用令牌桶算法。令牌桶算法的基本思路是每个请求尝试获取一个令牌,后端只处理持有令牌的请求,生产令牌的速度和效率我们都可以自己限定。
-
异步下单
为了提升下单的效率,并且防止下单服务的失败。需要将下单这一操作进行异步处理。最常采用的办法是使用队列,队列最显著的三个优点:异步、削峰、解耦。这里可以采用rabbitmq,在后台经过了限流、库存校验之后,流入到这一步骤的就是有效请求。然后发送到队列里,队列接受消息,异步下单。下完单,入库没有问题可以用短信通知用户秒杀成功。假如失败的话,可以采用补偿机制,重试。
-
服务降级
假如在秒杀过程中出现了某个服务器宕机,或者服务不可用,应该做好后备工作。之前的博客里有介绍通过Hystrix进行服务熔断和降级,可以开发一个备用服务,假如服务器真的宕机了,直接给用户一个友好的提示返回,而不是直接卡死,服务器错误等生硬的反馈。
1.3 扫码登录流程
参考答案
什么是二维码?
二维码又称二维条码,常见的二维码为QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar Code条形码能存更多的信息,也能表示更多的数据类型。-- 百度百科
在商品上,一般都会有条形码,条形码也称为一维码,条形码只能表示一串数字。二维码要比条形码丰富很多,可以存储数字、字符串、图片、文件等,比如我们可以把 www.nowcoder.com 存储在二维码中,扫码二维码我们就可以获取到牛客网的地址。
移动端基于token的认证机制
在了解扫码登录原理之前,有必要先了解移动端基于 token 的认证机制,对理解扫码登录原理还是非常有帮助的。基于 token 的认证机制跟我们常用的账号密码认证方式有较大的不同,安全系数比账号密码要高,如果每次验证都传入账号密码,那么被劫持的概率就变大了。
基于 token 的认证机制流程图,如下图所示:

基于 token 的认证机制,只有在第一次使用需要输入账号密码,后续使用将不在输入账号密码。其实在登陆的时候不仅传入账号、密码,还传入了手机的设备信息。在服务端验证账号、密码正确后,服务端会做两件事。
- 将账号与设备关联起来,在某种意义上,设备信息就代表着账号。
- 生成一个 token 令牌,并且在 token 与账号、设备关联,类似于key/value,token 作为 key ,账号、设备信息作为value,持久化在磁盘上。
将 token 返回给移动端,移动端将 token 存入在本地,往后移动端都通过 token 访问服务端 API ,当然除了 token 之外,还需要携带设备信息,因为 token 可能会被劫持。带上设备信息之后,就算 token 被劫持也没有关系,因为设备信息是唯一的。
这就是基于 token 的认证机制,将账号密码换成了 token、设备信息,从而提高了安全系数,可别小看这个 token ,token 是身份凭证,在扫码登录的时候也会用到。
二维码扫码登录的原理
好了,知道了移动端基于 token 的认证机制后,接下来就进入我们的主题:二维码扫码登陆的原理。先上二维码扫码登录的流程图:
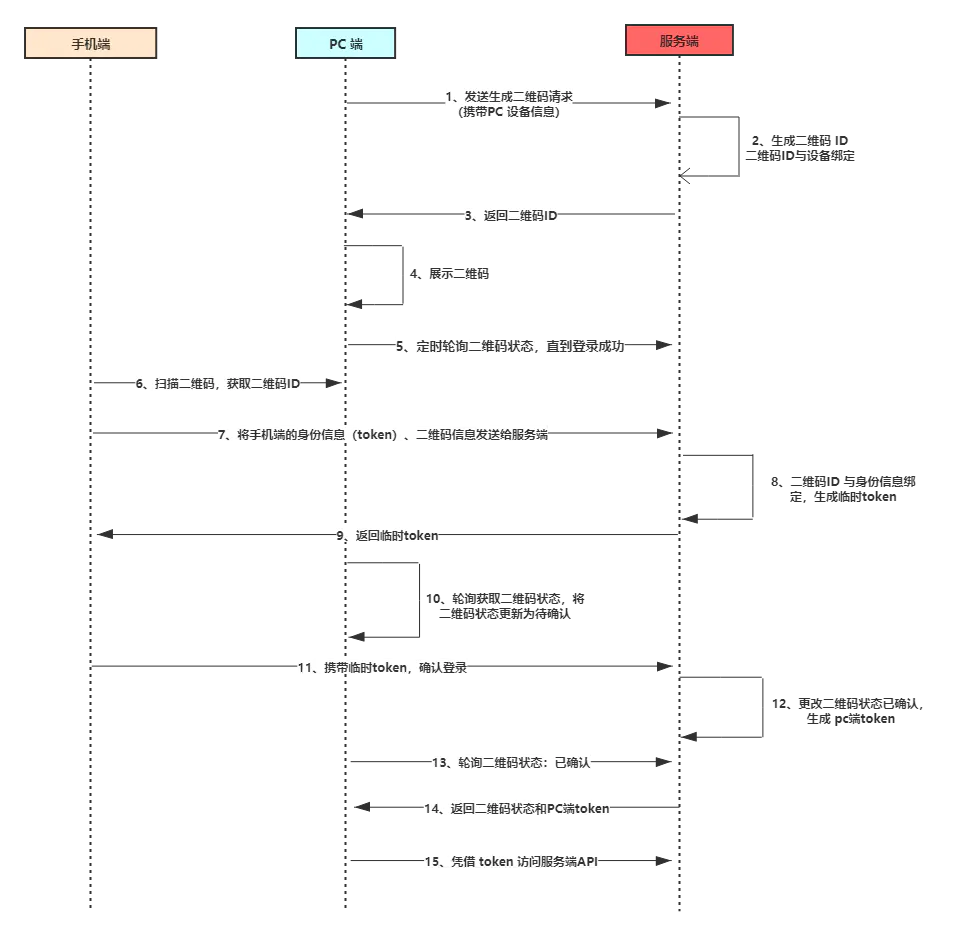
扫码登录可以分为三个阶段:待扫描、已扫描待确认、已确认。我们就来看看这三个阶段。
-
带扫描阶段
待扫描阶段也就是流程图中 1~5 阶段,即生成二维码阶段,这个阶段跟移动端没有关系,是 PC 端跟服务端的交互过程。
首先 PC 端携带设备信息想服务端发起生成二维码请求,服务端会生成唯一的二维码 ID,你可以理解为 UUID,并且将 二维码 ID 跟 PC 设备信息关联起来,这跟移动端登录有点相似。
PC 端接受到二维码 ID 之后,将二维码 ID 以二维码的形式展示,等待移动端扫码。此时在 PC 端会启动一个定时器,轮询查询二维码的状态。如果移动端未扫描的话,那么一段时间后二维码将会失效。
-
已扫码待确认阶段
流程图中第 6 ~ 10 阶段,我们在 PC 端登录微信时,手机扫码后,PC 端的二维码会变成已扫码,请在手机端确认。这个阶段是移动端跟服务端交互的过程。
首先移动端扫描二维码,获取二维码 ID,然后将手机端登录的信息凭证(token)和 二维码 ID 作为参数发送给服务端,此时的手机一定是登录的,不存在没登录的情况。
服务端接受请求后,会将 token 与二维码 ID 关联,为什么需要关联呢?你想想,我们使用微信时,移动端退出, PC 端是不是也需要退出,这个关联就有点把子作用了。然后会生成一个一次性 token,这个 token 会返回给移动端,一次性 token 用作确认时候的凭证。
然后PC 端的定时器,会轮询到二维码的状态已经发生变化,会将 PC 端的二维码更新为已扫描,请确认。
-
已确认
流程图中的 第 11 ~ 15 步骤,这是扫码登录的最后阶段,移动端携带上一步骤中获取的临时 token ,确认登录,服务端校对完成后,会更新二维码状态,并且给 PC 端生成一个正式的 token ,后续 PC 端就是持有这个 token 访问服务端。
PC 端的定时器,轮询到了二维码状态为登录状态,并且会获取到了生成的 token ,完成登录,后续访问都基于 token 完成。
在服务器端会跟手机端一样,维护着 token 跟二维码、PC 设备信息、账号等信息。
1.4 如何实现单点登录?
参考答案
单点登录全称Single Sign On(以下简称SSO),是指在多系统应用群中登录一个系统,便可在其他所有系统中得到授权而无需再次登录,包括单点登录与单点注销两部分。
登录
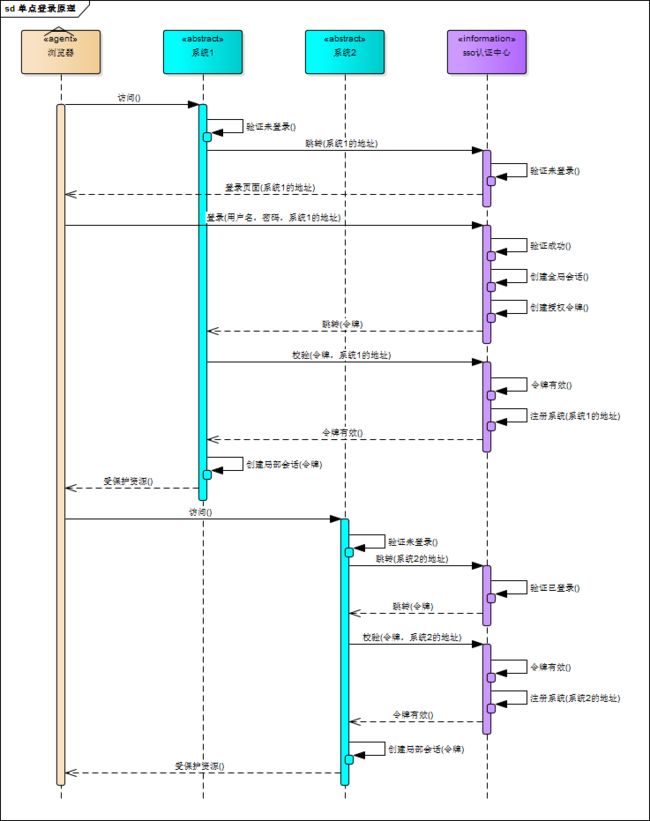
相比于单系统登录,sso需要一个独立的认证中心,只有认证中心能接受用户的用户名密码等安全信息,其他系统不提供登录入口,只接受认证中心的间接授权。间接授权通过令牌实现,sso认证中心验证用户的用户名密码没问题,创建授权令牌,在接下来的跳转过程中,授权令牌作为参数发送给各个子系统,子系统拿到令牌,即得到了授权,可以借此创建局部会话,局部会话登录方式与单系统的登录方式相同。这个过程,也就是单点登录的原理,用下图说明:
下面对上图简要描述:
- 用户访问系统1的受保护资源,系统1发现用户未登录,跳转至sso认证中心,并将自己的地址作为参数;
- sso认证中心发现用户未登录,将用户引导至登录页面;
- 用户输入用户名密码提交登录申请;
- sso认证中心校验用户信息,创建用户与sso认证中心之间的会话,称为全局会话,同时创建授权令牌;
- sso认证中心带着令牌跳转会最初的请求地址(系统1);
- 系统1拿到令牌,去sso认证中心校验令牌是否有效;
- sso认证中心校验令牌,返回有效,注册系统1;
- 系统1使用该令牌创建与用户的会话,称为局部会话,返回受保护资源;
- 用户访问系统2的受保护资源;
- 系统2发现用户未登录,跳转至sso认证中心,并将自己的地址作为参数;
- sso认证中心发现用户已登录,跳转回系统2的地址,并附上令牌;
- 系统2拿到令牌,去sso认证中心校验令牌是否有效;
- sso认证中心校验令牌,返回有效,注册系统2;
- 系统2使用该令牌创建与用户的局部会话,返回受保护资源。
用户登录成功之后,会与sso认证中心及各个子系统建立会话,用户与sso认证中心建立的会话称为全局会话,用户与各个子系统建立的会话称为局部会话,局部会话建立之后,用户访问子系统受保护资源将不再通过sso认证中心,全局会话与局部会话有如下约束关系:
- 局部会话存在,全局会话一定存在;
- 全局会话存在,局部会话不一定存在;
- 全局会话销毁,局部会话必须销毁。
注销
单点登录自然也要单点注销,在一个子系统中注销,所有子系统的会话都将被销毁,用下面的图来说明:

sso认证中心一直监听全局会话的状态,一旦全局会话销毁,监听器将通知所有注册系统执行注销操作。下面对上图简要说明:
- 用户向系统1发起注销请求;
- 系统1根据用户与系统1建立的会话id拿到令牌,向sso认证中心发起注销请求;
- sso认证中心校验令牌有效,销毁全局会话,同时取出所有用此令牌注册的系统地址;
- sso认证中心向所有注册系统发起注销请求;
- 各注册系统接收sso认证中心的注销请求,销毁局部会话;
- sso认证中心引导用户至登录页面。
部署
单点登录涉及sso认证中心与众子系统,子系统与sso认证中心需要通信以交换令牌、校验令牌及发起注销请求,因而子系统必须集成sso的客户端,sso认证中心则是sso服务端,整个单点登录过程实质是sso客户端与服务端通信的过程,用下图描述:
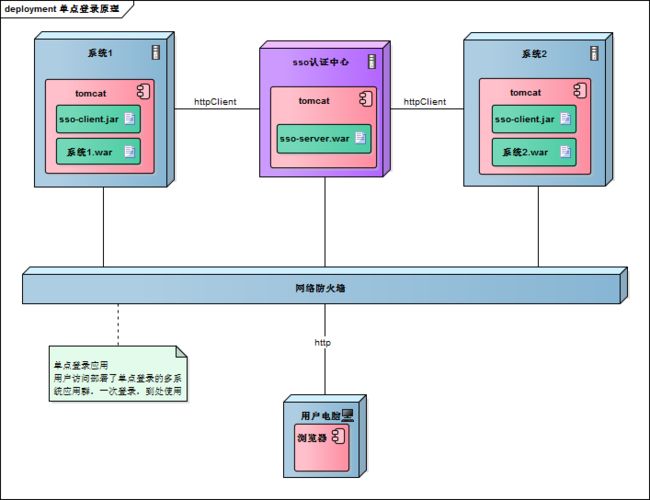
sso认证中心与sso客户端通信方式有多种,这里以简单好用的httpClient为例,web service、rpc、restful api都可以。
1.5 如何设计一个本地缓存?
参考答案
想要设计一个本地缓存,考虑点主要在数据用何种方式存储,能存储多少数据,多余的数据如何处理等几个点,下面我们来详细的介绍每个考虑点:
-
数据结构
首要考虑的就是数据该如何存储,用什么数据结构存储。最简单的就直接用Map来存储数据,或者复杂的如redis一样提供了多种数据类型哈希,列表,集合,有序集合等,底层使用了双端链表,压缩列表,集合,跳跃表等数据结构。
-
对象上限
因为是本地缓存,内存有上限,所以一般都会指定缓存对象的数量比如1024,当达到某个上限后需要有某种策略去删除多余的数据。
-
清除策略
上面说到当达到对象上限之后需要有清除策略,常见的比如有LRU(最近最少使用)、FIFO(先进先出)、LFU(最近最不常用)、SOFT(软引用)、WEAK(弱引用)等策略。
-
过期时间
除了使用清除策略,一般本地缓存也会有一个过期时间设置,比如redis可以给每个key设置一个过期时间,这样当达到过期时间之后直接删除,采用清除策略+过期时间双重保证。
-
线程安全
像redis是直接使用单线程处理,所以就不存在线程安全问题。而我们现在提供的本地缓存往往是可以多个线程同时访问的,所以线程安全是不容忽视的问题,并且线程安全问题是不应该抛给使用者去保证。
-
简明的接口
提供一个傻瓜式的对外接口是很有必要的,对使用者来说使用此缓存不是一种负担而是一种享受,提供常用的get,put,remove,clear,getSize等方法即可。
-
是否持久化
这个其实不是必须的,是否需要将缓存数据持久化看需求。本地缓存如ehcache是支持持久化的,而guava是没有持久化功能的。分布式缓存如redis是有持久化功能的,memcached是没有持久化功能的。
-
阻塞机制
问题。而我们现在提供的本地缓存往往是可以多个线程同时访问的,所以线程安全是不容忽视的问题,并且线程安全问题是不应该抛给使用者去保证。
-
简明的接口
提供一个傻瓜式的对外接口是很有必要的,对使用者来说使用此缓存不是一种负担而是一种享受,提供常用的get,put,remove,clear,getSize等方法即可。
-
是否持久化
这个其实不是必须的,是否需要将缓存数据持久化看需求。本地缓存如ehcache是支持持久化的,而guava是没有持久化功能的。分布式缓存如redis是有持久化功能的,memcached是没有持久化功能的。
-
阻塞机制
我们使用缓存的目的就是因为被缓存的数据生成比较费时,比如调用对外的接口,查询数据库,计算量很大的结果等等。这时候如果多个线程同时调用get方法获取的结果都为null,每个线程都去执行一遍费时的计算,其实也是对资源的浪费。最好的办法是只有一个线程去执行,其他线程等待,计算一次就够了。但是此功能基本上都交给使用者来处理,很少有本地缓存有这种功能。