ICASSP 2023 | 深度窄带网络消除实时语音通信中的干扰音
来源:ICASSP 2023
作者:Feifei Xiong, Jinwei Feng等
论文题目:Deep Subband Network for Joint Suppression of Echo, Noise and Reverberation in Real-Time Fullband Speech Communication
本文由阿里巴巴钉钉蜂鸣鸟音频实验室(Hummingbird Audio Lab)自主研发,提出了一种基于频-时调制谱的改进型窄带滤波网络(STSubNet),“一模型,多任务”方案,联合消除实时语音通信中常见的三种干扰音(回声,噪音和混响)。


一、摘要
本文由阿里巴巴钉钉蜂鸣鸟音频实验室(Hummingbird Audio Lab)自主研发,提出了基于之前研发的频-时调制谱深度窄带滤波网络(spectro-temporal SubNet,STSubNet [1]),在保留 STSubNet 对于语音去噪去混响优势的前提下,进一步增加了对于回声这类干扰声的抑制,实现了在同一网络下三大类干扰声,即回声,噪音和混响的联合消除。为了提升模型消除干扰声的效率以及最小化减少对于各自干扰声抑制带来的语音损伤,STSubNet 集成了传统的自适应滤波器以及一种新颖的时域损失函数,直接应用于全带语音信号(fullband,采样率48kHz,这几年在实时语音通信 real-time communication RTC 场景下从宽带16kHz提升到全带48kHz也变得越来越受欢迎)。
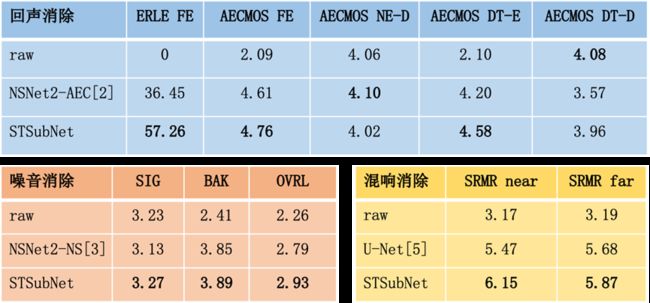
实验表明,更好的自适应滤波器以及此自适应滤波器处理后的结果作为STSubNet的第一通道输入得到了更好的去除三大干扰声的效果。在三个公开的测试集里 [2,3,4],相比于state-of-the-art专门用于去除回声的模型 [2],我们的模型 STSubNet 在远端单讲场景下效果提升 57%,双讲场景下效果提升9%,相比于 SOTA专门用于去除噪音的模型 [3],STSubNet 语音质量提升5%, 相比于 SOTA专门用于去除混响的模型 [5],STSubNet 语音质量提升8%。据我们了解,这也是行业首次对于此三大干扰声在一个神经网络模型进行处理的研究尝试。
二、研究目的
近年来,使用深度学习监督下的语音增强技术不久收到了极大的关注,而且已经开始部署于产品用于实时语音通信与交互中,比如这几年宣传的比较多的AI降噪技术,基于训练数据的可用性和丰富性,以及深度神经网络架构实时性的进步,AI降噪提供了比传统去除干扰声的方法更高效的性能。尽管这几年这个研发方向有着巨大的创新和改进,实时语音增强技术仍存在很多挑战,其中就包括在同一模型里实现不同种类的干扰声的消除,避免多个模型部署带来的模型间error propagation,计算量不足,算法延迟过大等弊端。
不同于经典的以全频带语音信息作为输入的神经网络框架,窄带滤波网络(SubNet)专注于每个频带信息作为输入,并让每个频带共享网络参数。其原理在于基于本地频谱模式下提取的频带的信号特征能否有效的区分开语音和非语音信息。为了进一步提高窄带滤波网络效能,本质上是如何提高输入的频带信息对于语音和非语音的鉴别力(discrimination)。受到听觉处理研发方向的启发,即哺乳动物听觉感知系统对于声音的特征值提取在于频-时调制谱感受区(STRFs)的感知,听觉感知神经突触的触发对应特定感受区里面的调制信息,我们之前提出一种更高效地提取STRF的信息的方法用作窄带滤波网络的输入以提高窄带滤波网络对于消除噪音和混响的效能,即STSubNet网络 [1]。本文基于STSubNet,尝试在同一网络模型下去联合消除实时语音通信中三大常见干扰声(回声,噪音和混响),实现“一模型,多任务”。
具体来说,回声消除采取了hybrid的算法方案,即使用传统的自适应滤波器来消除线性回声信号带来的干扰,残留的回声信号以及噪音和混响交给STSubNet网络模型来处理。为了提升模型消除干扰声的效率以及最小化减少对于各自干扰声抑制带来的语音损伤,STSubNet 集成了一种新颖的时域损失函数来达到不同子任务内部和不同子任务之间的权衡,即回声消除任务中单讲不漏回声和双讲透明之间的权衡,去噪和去混响子任务中对于抑制不想要的干扰声和保留想要的语音信号之间的权衡,以提高窄带滤波网络对于消除残留回声,噪音和混响的效能。
三、研究方法
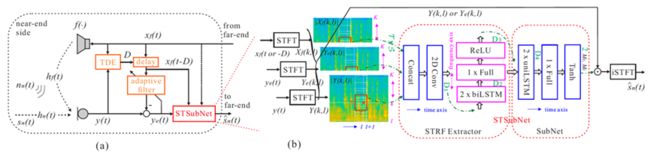
上图概述了我们提出的 STSubNet 的回声,噪音,混响的联合消除架构:
Ø 短时傅立叶变换 STFT 框架下的实时语音处理;
Ø 自适应滤波器 adaptive filter (AF):用于消除回声信号里面的线性部分。为了得到更好的收敛效果,远端信号与麦克风信号之间的时延需要进行精确补偿,这就需要一个额外的辅助模块,即时延估计 time delay estimation TDE。 AF算法用了两类,一类(AF1)为开源的RTC toolkit SpeexDSP [6] 的实现方法;另一类(AF2)使用了子带实现的比例归一化最小二乘算法;
Ø 频-时调制谱深度窄带滤波网络 STSubNet,即 STRF 提取(二维卷积网络+双向频谱方向的长短期记忆网络)+窄带滤波网络 SubNet,网络输出为复数域的掩码(mask)。其输入信号包括远端信号,麦克风接收到的原始信号,以及自适应滤波器AF处理完之后的信号。
损失函数 Loss function:时域里的signal-to-distortion ratio (SDR) loss
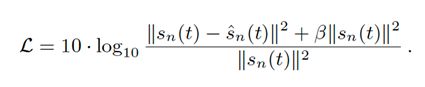
另一方面,上述的损失函数并不是很适合只有远端信号的场景,即只有回声信号,近端并没有说话人说话,受到 [7] 的启发,我们提出了一个辅助的损失函数
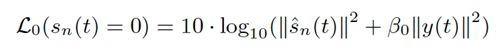
网络大小,计算量见如下表格(real time factor RTF 值是在Intel Xeon CPU E5-2682 v4 (2.50 GHz)运行得到的)
四、实验结果
为了充分理解本文提出的模型对于不同干扰声的抑制效果,根据数据集 [2,3,4,8,9,10],我们仿真出了十组不同的测试集(下图的上半段)以及三个公开的测试集 [2,3,4](下图的下半段),评价指标 evaluation metrics 包括 Echo return loss enhancement (ERLE), wideband perceptual evaluation of speech quality score (PESQ), normalized speech-to-reverberation modulation energy ratio (SRMR), DNSMOS (speech quality SIG, background noise quality BAK, and overall quality OVRL), AECMOS (far-end MOS, near-end DMOS, double talk Echo and other DMOS), 所有指标越高越好,而且[11,12] 表明 DNSMOS 和 AECMOS 更符合主观体验的指标。
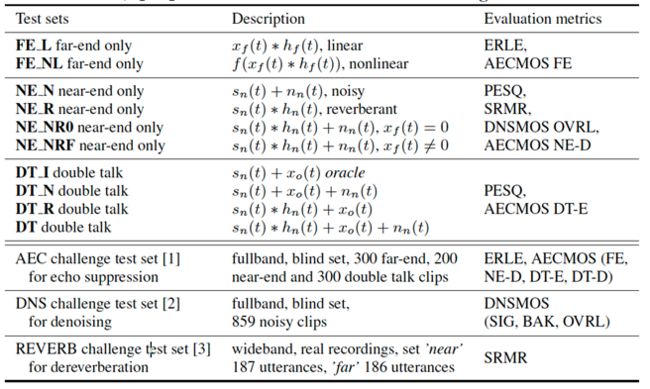
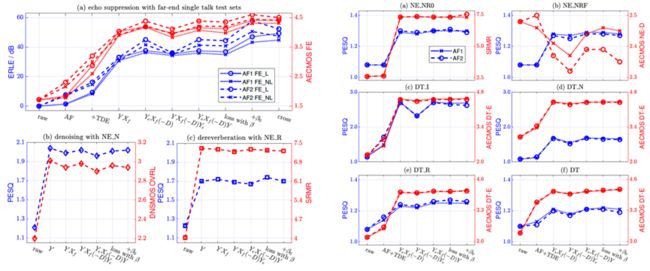
上图的实验结果给出了以下几点重要的信息:
Ø 效果更好的自适应滤波器AF2对于后续的模型STSubNet 帮助更大;
Ø 作为模型输入的第一通道,自适应滤波器AF处理完之后的信号对于回声消除更有利,而麦克风原始信号对于去噪去混响更友好,而提出的损失函数能缓解上述的权衡;
Ø 双讲的场景比单讲(远端或者近端)的场景要更具挑战;去混响比去噪更具挑战(根据语音质量PESQ)。
为了验证所提方案的回声,噪音,混响消除的实际效果,测试集用了三个公开的测试集 [2,3,4],并跟state-of-the-art其他方案对比。
更多样例试听:GitHub - ffxiong/stsubnet
五、结论
本文提出了基于频-时调制谱的深度窄带滤波网络用于实时全带语音通信,在同一网络同时实现去回声,去噪和去混响的功能。实验结果验证了更好的自适应滤波器以及提出的新颖的时域损失函数对于STSubNet性能的提升。对比于目前SOTA方法,STSubNet不仅能有效进行去回声,去噪和去混响三个功能的同时实现,并在很小的网络参数量的情况下达到有竞争力的语音增强表现。
六、参考文献
[1] F. Xiong, W. Chen, P. Wang, X. Li, and J. Feng, “Spectro-Temporal SubNet for real-time monaural speech denoising and dereverberation,” in Interspeech, 2022, pp. 931–935.
[2] R. Cutler, A. Saabas, T. Parnamaa, M. Purin, H. Gamper, S. Braun, K. Sorensen, and R. Aichner, “ICASSP 2022 acoustic echo cancellation challenge,” in ICASSP, 2022, pp. 9107–9111.
[3] H. Dubey, V. Gopal, R. Cutler, S. Matusevych, S. Braun, E. S. Eskimez, M. Thakker, T. Yoshioka, H. Gamper, and R. Aichner, “ICASSP 2022 deep noise suppression challenge,” in ICASSP, 2022, pp. 9271–9275.
[4] K. Kinoshita, M. Delcroix, S. Gannot, E. A. P. Habets, R. Haeb-Umbach, W. Kellermann, V. Leutnant, R. Maas, T. Nakatani, B. Raj, A. Sehr, and T. Yoshioka, “A summary of the REVERB challenge: State-of-the-art and remaining challenges in reverberant speech processing research,” EURASIP Journal on Advances in Signal Processing, no. 7, 2016.
[5] O. Ernst, S. E. Chazan, S. Gannot, and J. Goldberger, “Speech dereverberation using fully convolutional networks,” in European Signal Processing Conference, 2018, pp. 390–394.
[6] https://gitlab.xiph.org/xiph/speexdsp/
[7] M. Delcroix, K. Kinoshita, T. Ochiai, K. Zmolikova, H. Sato, and T. Nakatani, “Listen only to me! How well can target speech extraction handle false alarms?,” in Interspeech, 2022, pp. 216–220.
[8] https://www.mmsp.ece.mcgill.ca/Documents/Data/
[9] G. Wichern, J. Antognini, M. Flynn, L. R. Zhu, E. McQuinn, D. Crow, E. Manilow, and J. Le Roux, “WHAM!: Extending speech separation to noisy environments,” in Interspeech, 2019.
[10] J. Eaton, N. D. Gaubitch, A. H. Moore, and P. A. Naylor, “Estimation of room acoustic parameters: The ACE challenge,” IEEE Trans Audio Speech Lang Process, vol. 24, no. 10, pp. 1681–1693, 2016.
[11] C. K. A. Reddy, V. Gopal, and R. Cutler, “DNSMOS P.835: A nonintrusive perceptual objective speech quality metric to evaluate noise suppressors,” in ICASSP, 2022, pp. 886–890.
[12] M. Purin, S. Sootla, M. Sponza, A. Saabas, and R. Cutler, “AECMOS: A speech quality assessment metric for echo impairment,” in ICASSP, 2022, pp. 901–905.