【论文笔记】Attention is all you need
在阅读本文之前,关于self-attention的详细介绍,比较全面的transformer总结看之前copy的这篇文章。
有了self-attention的基础之后再看这篇论文,感觉就容易了。
论文:Attention is all you need。
文章目录
-
- 1-2 Introduction & Background
- 3 Model Architecture
-
- 3.1 Encoder and Decoder Stacks
- 3.2 Attention
-
- 3.2.1 Scaled Dot-Product Attention
- 3.2.2 Multi-Head Attention
- 3.2.3 模型中attention的应用
- 3.3 Position-wise Feed-Forward Networks 基于位置的前馈网络
- 3.4 Embeddings and Softmax
- 3.5 Positional Encoding
- 4 why self-attention
- 5 Training
-
- 5.1 training data and batching
- 5.2 Hardware and Schedule
- 5.3 Optimizer
- 5.4 regularization
- 6 results
-
- 6.1 机器翻译
1-2 Introduction & Background
RNN:This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.
解决(治标不治本,因为根本上序列计算的限制还在):
- factorization tricks.
- conditional computation.
也使用过CNN来as basic building block, such as:ByteNet, ConvS2S. But: makes it more diffucult to learn dependencies between distant positions.(计算量与观测序列X和输出序列Y的长度成正比)
历史:
| 名称 | 解释 | 局限 |
|---|---|---|
| seq2seq | ||
| encoder-decoder | 传统,一般配合RNN | |
| RNN\LSTM\GRU | 方向:单向双向;depth:单层or multi-layer; | RNN难以应付长序列、无法并行实现、对齐问题;神经网络需要能够将源语句的所有必要信息压缩成固定长度的向量 |
| CNN | 可以并行计算、变长序列样本 | 占内存、很多trick、大数据量上参数调整不容易 |
| Attention Mechanism | 关注向量子集、解决对齐问题 |
提到的点:
self-attention;
recurrent attention mechanism.
transduction models
3 Model Architecture
大部分的encoder-decoder structure:
输入序列:输入序列 x = (x1,…,xn), N个
encoder输出的连续表示:z = (z1,…,zn),N个
docoder的outputs: y=(y1,…,ym),M个
一次一个元素。consuming the previously generated symbols as additional input when generating the next.

The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder.
3.1 Encoder and Decoder Stacks
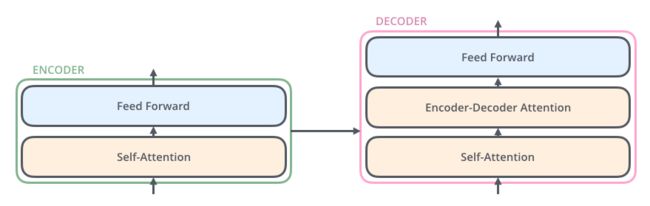
Encoder: a stack of N = 6 identical layers.Each layer has two sub-layers:(从下到上)
- multi-head self-attention mechanism.
- simple, position-wise fully conntected feed-forward network(以下叫ffnn).
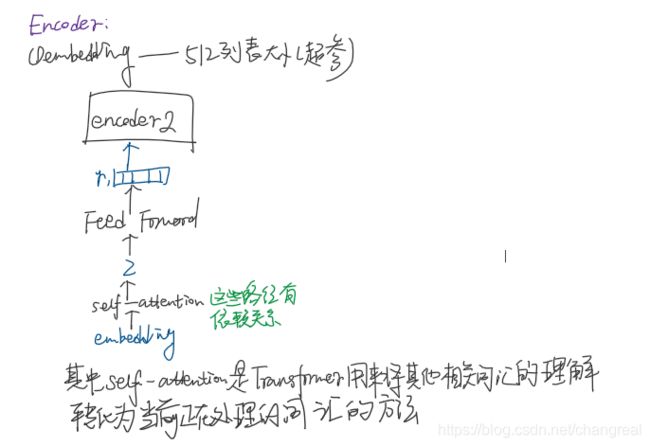
We employ a residual connection around each of the two sub-layers(2个子层之间残差连接) + layer normalization. 也就是说,每个子层的输出是LayerNorm(x + Sublayer(x)).
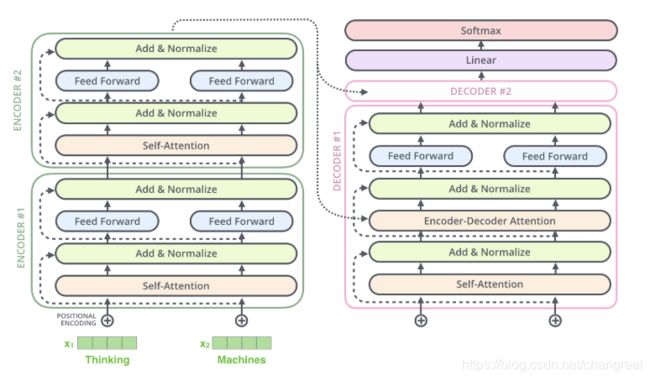
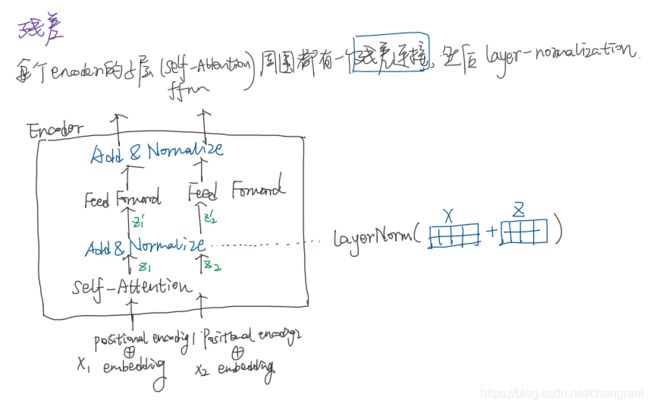
all sub-layers in the model + embediding layers, produce outputs of dimension dmodel = 512.
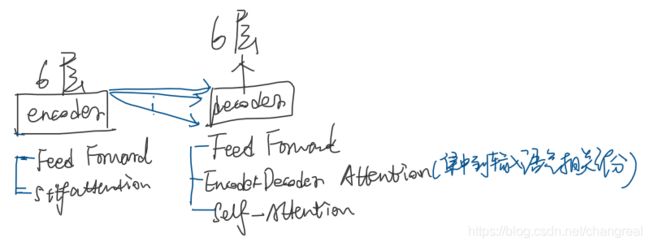
Decoder: a stack of N = 6 identical layers. the decoder inserts a third sub-layer:(从下到上)
- multi-head self-attention子层(接收encoder stack的输出)(mask)
- encoder-decoder attention
- ffnn
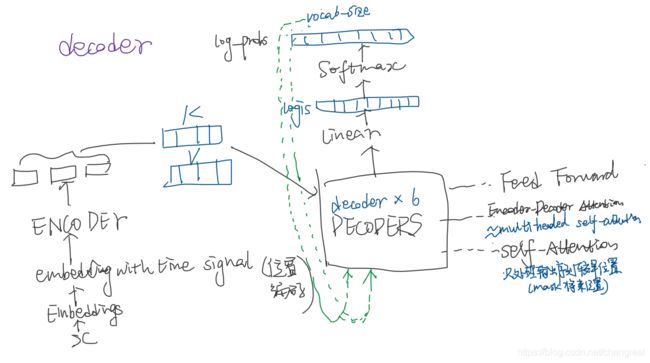
masking ensures that the predictions for position i can depend only on the known outputs at positions less than i.
每个子层residual connections + layer normalization.(残差连接round each of the sub-layers.)
3.2 Attention
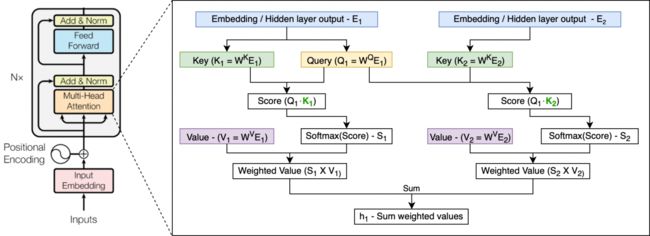
attention机制就是mapping a query and a set of key-value pairs to an output(all are vectors). the output is computed as a weighted sum of the values, where the weight assigned to each values is computed by a compatibility function of the query with the corresponding key.
这篇文章用到的attenion是:
- scaled Dot-Product Attention
- Multi-Head Attention
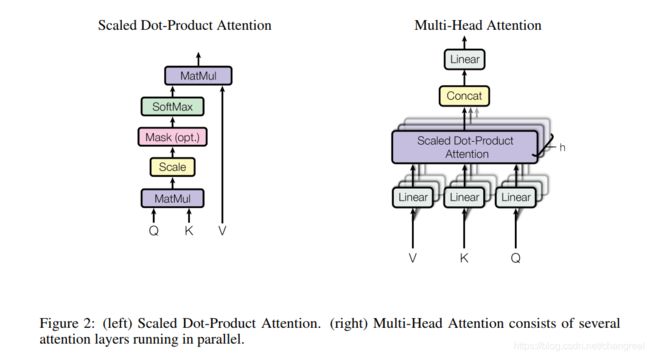
3.2.1 Scaled Dot-Product Attention
The input consists of queries and keys of dimension dk, and values of dimension dv. We compute the dot products of the query with all keys, divide each by sqrt(dk), and apply a softmax function to obtain the weights on the values.
在实践中,we compute the attention function on a set of queries simultaneously, packed together into a matrix Q. The keys and values are also packed together into matrices K and V.
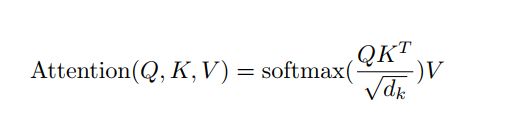

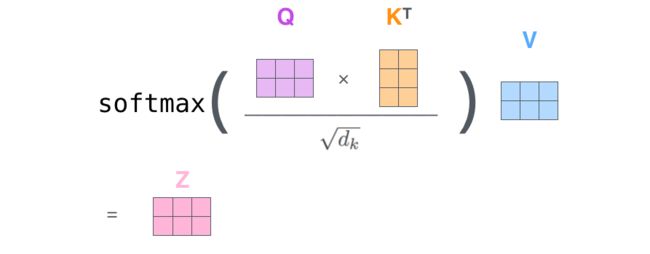
PS:2个最常用的attention函数是additive attention, dot-product attention. dot-product更快、更有效利用空间。
当dk都很小的时候两者表现差不多,但是dk大的时候,不带缩放的dot-product大幅度增长,然后会 pushing the softmax function into regions where it has extremely small gradients,因此,scale the dot product by 1/sqrt(dk).
3.2.2 Multi-Head Attention
在多头 attention的情况下,我们对每个头保持独立的Q/K/V权重矩阵,从而得到不同的Q/K/V矩阵。和之前一样,我们用X乘以WQ/WK/WV矩阵得到Q/K/V矩阵。
也是就:Queries, Keys, Values。
如果做上面列出的同样的self-attention计算,只是8次不同的加权矩阵,能得到8个不同的Z矩阵。
说的attention heads也就是产生的不同的Z矩阵。
论文提出对queries, keys, values做h次不同的投影,映射的维度都是dk,dv,然后经过scaled dot-product attention将结果拼接在一起,最终通过一个线性映射输出。通过多头注意力,模型能够获得不同子空间下的位置信息。
These are concatenated and once again projected, resulting in the final values.

8个不同的Z矩阵压缩成一个矩阵,乘以一个额外的权值矩阵W0,得到结果Z矩阵,它能从所有attention heads里捕获到信息,从而把这个句子喂给FFNN。

multi-head attention要点:
- employ h = 8 parallel attention layers, or heads.
- For each of these we use dk = dv = dmodel /h = 64. (dmodel 就是整合起来的维度)
- Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
3.2.3 模型中attention的应用
The Transformer uses multi-head attention in three different ways:
-
In “encoder-decoder attention” layers
输入为encoder的输出和decoder的self-attention输出。——queries来自于之前的decoder层,keys,values来自于encoder的输出。
Encoder-Decoder Attention层的工作原理与multi-headed self attention类似,只是它从其下一层创建queries矩阵,并从编码器堆栈的输出中获取keys和values矩阵。 -
encoder的self-attention layers.
Each position in the encoder can attend to all positions in the previous layer of the encoder
输入的Q、K、V都是一样的(input embedding and positional embedding) -
decoder的self-attention layers.
We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections.
在decoder的self-attention层中,只能够访问当前位置前面的位置
3.3 Position-wise Feed-Forward Networks 基于位置的前馈网络
编码器和解码器中的每个层都包含一个完全连接的前馈网络,该前馈网络单独且相同地应用于每个位置。This consists of two linear transformations(两层Dense层) with a ReLU activation in between. 可以看成是两层的1*1的1d-convolution。hidden_size变化为:512->2048->512
FFN(X) = max(0, xW1+b1)W2 + b2
they use different parameters from layer to layer.
Position-wise feed forward network,其实就是一个MLP网络。
3.4 Embeddings and Softmax
we use learned embeddings to convert the input tokens and output tokens to vectors of dimension dmodel. we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation. In the embedding layers, we multiply those weights by sqrt(dmodel).
3.5 Positional Encoding
we must inject some information about the relative or absolute position of the tokens in the sequence. add “positional encodings” to the input embeddings at the bottoms of the encoder and decoder stacks.
transformer向每个输入的embedding添加一个向量——positional encoding。这些向量遵循模型学习的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。
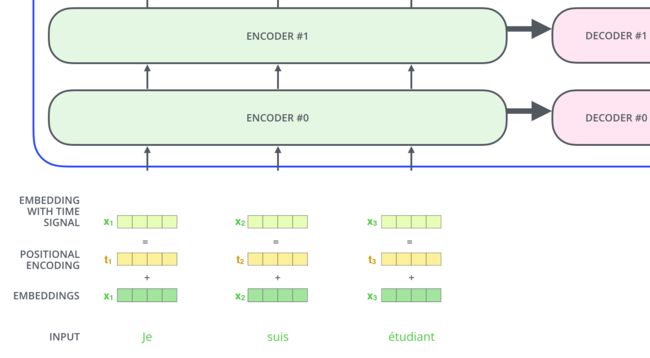
The positional encodings have the same dimension dmodel as the embeddings, so that the two can be summed.
positional encodings can be learned and fixed.
使用不同频率的正弦和余弦函数:
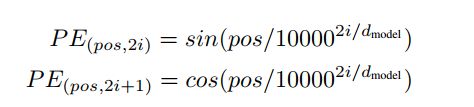
where pos is the position and i is the dimension.
We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset k, PEpos+k can be represented as a linear function of PEpos.
正弦和余弦函数具有周期性,对于固定长度偏差k(类似于周期),post +k位置的PE可以表示成关于pos位置PE的一个线性变化(存在线性关系),这样可以方便模型学习词与词之间的一个相对位置关系。
这种编码方法的优势是可以拓展到不可见的序列长度,比如如果我们的训练模型被要求翻译一个比训练集中任何一个句子都长的句子。
在其他NLP论文中,position embedding,通常是一个训练的向量,但是position embedding只是extra features,有该信息会更好,但是没有性能也不会产生极大下降,因为RNN、CNN本身就能够捕捉到位置信息,但是在Transformer模型中,Position Embedding是位置信息的唯一来源,因此是该模型的核心成分,并非是辅助性质的特征。
4 why self-attention
- the total computational complexity per layer.(每层的总计算复杂度)
- the amoount of computation tha can be parallelized.
- the path length between long-range dependencies in the network.
5 Training
5.1 training data and batching
sentence pairs, Sentences were encoded using byte-pair encoding. which has a shared source-target vocabulary of about 37000 tokens.
Sentence pairs were batched together by approximate sequence length.
5.2 Hardware and Schedule
8 NVIDIA P100 GPUs,
base models : 训练 100,000 steps or 12 hours.
big models :训练300,000 steps (3.5 days).
5.3 Optimizer
Adam optimizer, β1 = 0:9, β2 = 0:98 and θ = 10−9.
根据以下公式在训练过程中改变学习率:

5.4 regularization
Residual Dropout : apply dropout to the output of each sub-layer, to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks. Pdrop = 0.1在这篇论文里。
(每个子层的output、embeddings的和、encoder和decoder stacks的positional encodings三个地方用了residual dropout.)
label smoothing
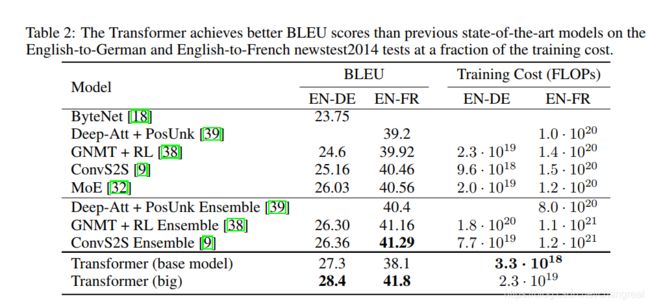
6 results
6.1 机器翻译
机器翻译多种模型参数:
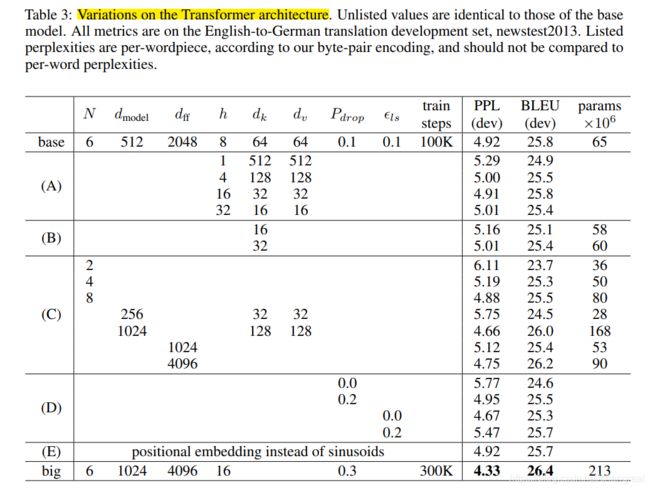
we vary the number of attention heads and the attention key and value dimensions.发现如下:
- reducing the attention key size dk hurts model quality
- a more sophisticated compatibility function than dot product may be beneficial
- bigger models are better
- dropout is very helpful in avoiding over-fitting
- replace our sinusoidal positional encoding with learned positional embeddings.