用户新增预测(Datawhale机器学习AI夏令营第三期)
文章目录
- 简介
- 任务1:跑通Baseline
-
- 实操并回答下面问题:
-
- 如果将submit.csv提交到讯飞比赛页面,会有多少的分数?
- 代码中如何对udmp进行了人工的onehot?
- 任务2.1:数据分析与可视化
-
- 编写代码回答下面的问题:
-
- **问题一:字段x1至x8为用户相关的属性,为匿名处理字段。添加代码对这些数据字段的取值分析,那些字段为数值类型?那些字段为类别类型?**
- **问题二:对于数值类型的字段,考虑绘制在标签分组下的箱线图。**
- **问题三:从common_ts中提取小时,绘制每小时下标签分布的变化。**
- **问题四:对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。**
- 任务2.2:模型交叉验证
-
- 编写代码回答下面的问题:
-
- **问题一:在上面模型中哪一个模型的macro F1效果最好,为什么这个模型效果最好?**
- **问题二:使用树模型训练,然后对特征重要性进行可视化;**
- **问题三:再加入3个模型训练,对比模型精度;**
- 任务2.3:特征工程
简介
内容为AI夏令营第三期 - 用户新增预测挑战赛教程的笔记,比赛链接为用户新增预测挑战赛,感觉教程比较适合新入门的小白,对新手很友好。这是我第一次参加机器学习相关的竞赛,记录小白升级打怪过程!
第一次修改时间:2023年8月18日,初步提交内容,完成教程了教程中所有的练习题。
任务1:跑通Baseline
# 1. 导入需要用到的相关库
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于科学计算和多维数组操作
import numpy as np
# 从 sklearn.tree 模块中导入 DecisionTreeClassifier 类
# DecisionTreeClassifier 用于构建决策树分类模型
from sklearn.tree import DecisionTreeClassifier
# 2. 读取训练集和测试集
# 使用 read_csv() 函数从文件中读取训练集数据,文件名为 'train.csv'
train_data = pd.read_csv('train.csv')
# 使用 read_csv() 函数从文件中读取测试集数据,文件名为 'test.csv'
test_data = pd.read_csv('test.csv')
train_data.head()
| uuid | eid | udmap | common_ts | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 26 | {"key3":"67804","key2":"650"} | 1689673468244 | 4 | 0 | 41 | 107 | 206 | 1 | 0 | 1 | 0 |
| 1 | 1 | 26 | {"key3":"67804","key2":"484"} | 1689082941469 | 4 | 0 | 41 | 24 | 283 | 4 | 8 | 1 | 0 |
| 2 | 2 | 8 | unknown | 1689407393040 | 4 | 0 | 41 | 71 | 288 | 4 | 7 | 1 | 0 |
| 3 | 3 | 11 | unknown | 1689467815688 | 1 | 3 | 41 | 17 | 366 | 1 | 6 | 1 | 0 |
| 4 | 4 | 26 | {"key3":"67804","key2":"650"} | 1689491751442 | 0 | 3 | 41 | 92 | 383 | 4 | 8 | 1 | 0 |
# 3. 将 'udmap' 列进行 One-Hot 编码
# 数据样例:
# udmap key1 key2 key3 key4 key5 key6 key7 key8 key9
# 0 {'key1': 2} 2 0 0 0 0 0 0 0 0
# 1 {'key2': 1} 0 1 0 0 0 0 0 0 0
# 2 {'key1': 3, 'key2': 2} 3 2 0 0 0 0 0 0 0
# 在 python 中, 形如 {'key1': 3, 'key2': 2} 格式的为字典类型对象, 通过key-value键值对的方式存储
# 而在本数据集中, udmap实际是以字符的形式存储, 所以处理时需要先用eval 函数将'udmap' 解析为字典
# 具体实现代码:
# 定义函数 udmap_onethot,用于将 'udmap' 列进行 One-Hot 编码
def udmap_onethot(d):
v = np.zeros(9) # 创建一个长度为 9 的零数组
if d == 'unknown': # 如果 'udmap' 的值是 'unknown'
return v # 返回零数组
d = eval(d) # 将 'udmap' 的值解析为一个字典
for i in range(1, 10): # 遍历 'key1' 到 'key9', 注意, 这里不包括10本身
if 'key' + str(i) in d: # 如果当前键存在于字典中
v[i-1] = d['key' + str(i)] # 将字典中的值存储在对应的索引位置上
return v # 返回 One-Hot 编码后的数组
# 注: 对于不理解的步骤, 可以逐行 print 内容查看
# 使用 apply() 方法将 udmap_onethot 函数应用于每个样本的 'udmap' 列
# np.vstack() 用于将结果堆叠成一个数组
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
# 为新的特征 DataFrame 命名列名
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 将编码后的 udmap 特征与原始数据进行拼接,沿着列方向拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
# 4. 编码 udmap 是否为空
# 使用比较运算符将每个样本的 'udmap' 列与字符串 'unknown' 进行比较,返回一个布尔值的 Series
# 使用 astype(int) 将布尔值转换为整数(0 或 1),以便进行后续的数值计算和分析
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)
# 5. 提取 eid 的频次特征
# 使用 map() 方法将每个样本的 eid 映射到训练数据中 eid 的频次计数
# train_data['eid'].value_counts() 返回每个 eid 出现的频次计数
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())
# 6. 提取 eid 的标签特征(不同访问行为的人有不同的target标签)
# 使用 groupby() 方法按照 eid 进行分组,然后计算每个 eid 分组的目标值均值
# train_data.groupby('eid')['target'].mean() 返回每个 eid 分组的目标值均值
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())
# 7. 提取时间戳
# 使用 pd.to_datetime() 函数将时间戳列转换为 datetime 类型
# 样例:1678932546000->2023-03-15 15:14:16
# 注: 需要注意时间戳的长度, 如果是13位则unit 为 毫秒, 如果是10位则为 秒, 这是转时间戳时容易踩的坑
# 具体实现代码:
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
# 使用 dt.hour 属性从 datetime 列中提取小时信息,并将提取的小时信息存储在新的列 'common_ts_hour'
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour
# 8. 加载决策树模型进行训练(直接使用sklearn中导入的包进行模型建立)
clf = DecisionTreeClassifier()
# 使用 fit 方法训练模型
# train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1) 从训练数据集中移除列 'udmap', 'common_ts', 'uuid', 'target'
# 这些列可能是特征或标签,取决于数据集的设置
# train_data['target'] 是训练数据集中的标签列,它包含了每个样本的目标值
clf.fit(
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1), # 特征数据:移除指定的列作为特征
train_data['target'] # 目标数据:将 'target' 列作为模型的目标进行训练
)
# 9. 对测试集进行预测,并保存结果到result_df中
# 创建一个DataFrame来存储预测结果,其中包括两列:'uuid' 和 'target'
# 'uuid' 列来自测试数据集中的 'uuid' 列,'target' 列将用来存储模型的预测结果
result_df = pd.DataFrame({
'uuid': test_data['uuid'], # 使用测试数据集中的 'uuid' 列作为 'uuid' 列的值
'target': clf.predict(test_data.drop(['udmap', 'common_ts', 'uuid'], axis=1)) # 使用模型 clf 对测试数据集进行预测,并将预测结果存储在 'target' 列中
})
# 10. 保存结果文件到本地
# 将结果DataFrame保存为一个CSV文件,文件名为 'submit.csv'
# 参数 index=None 表示不将DataFrame的索引写入文件中
result_df.to_csv('submit.csv', index=None)
实操并回答下面问题:
如果将submit.csv提交到讯飞比赛页面,会有多少的分数?
代码中如何对udmp进行了人工的onehot?
1:0.62734
2:对umap列中的字典元素按键取值,初始为一个九维的向量,将字典中键对应的值覆盖到向量中的对应位置。
任务2.1:数据分析与可视化
# 导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 读取训练集和测试集文件
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
# 相关性热力图
sns.heatmap(train_data.corr().abs(), cmap='YlOrRd')

# x7分组下标签均值
sns.barplot(x='x7', y='target', data=train_data)

编写代码回答下面的问题:
- 字段x1至x8为用户相关的属性,为匿名处理字段。添加代码对这些数据字段的取值分析,那些字段为数值类型?那些字段为类别类型?
- 对于数值类型的字段,考虑绘制在标签分组下的箱线图。
- 从common_ts中提取小时,绘制每小时下标签分布的变化。
- 对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。
问题一:字段x1至x8为用户相关的属性,为匿名处理字段。添加代码对这些数据字段的取值分析,那些字段为数值类型?那些字段为类别类型?
x1, x2, x3, x4, x5, x6, x7, x8为类别类型,x3,x4,x5为数值类型。
#1:
import pandas as pd
# 假设您的数据已经加载到名为 'data' 的 DataFrame 中
train_data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8']].head(5)
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 0 | 41 | 107 | 206 | 1 | 0 | 1 |
| 1 | 4 | 0 | 41 | 24 | 283 | 4 | 8 | 1 |
| 2 | 4 | 0 | 41 | 71 | 288 | 4 | 7 | 1 |
| 3 | 1 | 3 | 41 | 17 | 366 | 1 | 6 | 1 |
| 4 | 0 | 3 | 41 | 92 | 383 | 4 | 8 | 1 |
问题二:对于数值类型的字段,考虑绘制在标签分组下的箱线图。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(10, 6))
for i,y in enumerate(['x3', 'x4', 'x5']):
sns.boxplot(x="target", y=y, data=train_data, width=0.5, showfliers=False,ax=axes[i])
ax.set_xlabel('Label')
ax.set_ylabel(f'Feature {col}')
ax.set_title(f'Box Plot of Feature {col}')
ax.yaxis.grid(True)

问题三:从common_ts中提取小时,绘制每小时下标签分布的变化。
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 6),dpi=80)
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
# 使用 dt.hour 属性从 datetime 列中提取小时信息,并将提取的小时信息存储在新的列 'common_ts_hour'
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
sns.countplot(x="common_ts_hour",hue='target', data=train_data,ax = axes[0])
new_df = (train_data.groupby('common_ts_hour')['target']
.value_counts(normalize=True)
.sort_index()
.unstack()
)
new_df.plot.bar(stacked=True,ax = axes[1])
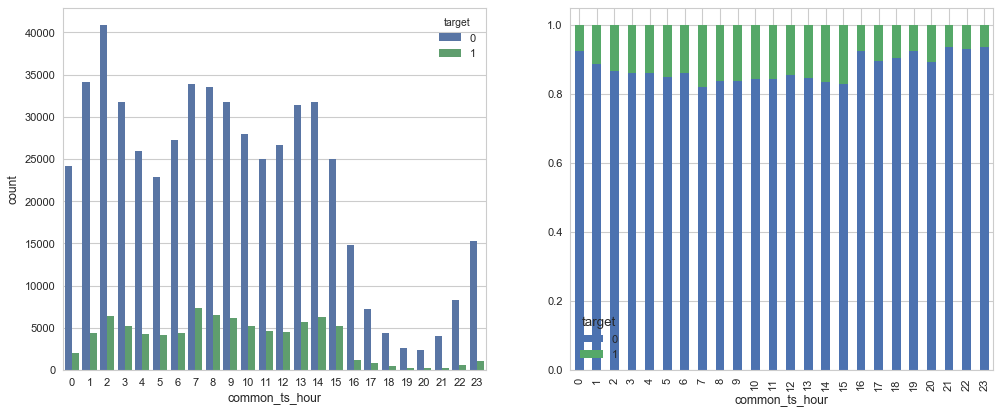
问题四:对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。
train_data = pd.read_csv('train.csv')
def udmap_onethot(d):
v = np.zeros(9) # 创建一个长度为 9 的零数组
if d == 'unknown': # 如果 'udmap' 的值是 'unknown'
return v # 返回零数组
d = eval(d) # 将 'udmap' 的值解析为一个字典
for i in range(1, 10): # 遍历 'key1' 到 'key9', 注意, 这里不包括10本身
if 'key' + str(i) in d: # 如果当前键存在于字典中
v[i-1] = d['key' + str(i)] # 将字典中的值存储在对应的索引位置上
return v # 返回 One-Hot 编码后的数组
# 注: 对于不理解的步骤, 可以逐行 print 内容查看
# 使用 apply() 方法将 udmap_onethot 函数应用于每个样本的 'udmap' 列
# np.vstack() 用于将结果堆叠成一个数组
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
# 为新的特征 DataFrame 命名列名
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 将编码后的 udmap 特征与原始数据进行拼接,沿着列方向拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
key_means = {}
for key in ["key"+str(i) for i in range(1,10)]:
key_mean = train_data[train_data[key]!=0]["target"].mean()
key_means[key] = key_mean
key_means
{'key1': 0.20862740446395034,
'key2': 0.11199392180793882,
'key3': 0.10190294045637927,
'key4': 0.12993673492307117,
'key5': 0.13023321337551066,
'key6': 0.08351648351648351,
'key7': 0.363013698630137,
'key8': 0.49056603773584906,
'key9': 0.4857142857142857}
key_means_df = pd.DataFrame(key_means, index = [0])
plt.figure(figsize=(12, 6))
sns.barplot(data=key_means_df, palette="Set3")
plt.xlabel('Keys')
plt.ylabel('Mean Target')
plt.title('Stacked Bar Plot of Mean Target by Keys')
plt.legend(title='Keys', loc='upper right')
plt.show()

任务2.2:模型交叉验证
# 导入库
import pandas as pd
import numpy as np
# 读取训练集和测试集文件
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
# 提取udmap特征,人工进行onehot
def udmap_onethot(d):
v = np.zeros(9)
if d == 'unknown':
return v
d = eval(d)
for i in range(1, 10):
if 'key' + str(i) in d:
v[i-1] = d['key' + str(i)]
return v
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 编码udmap是否为空
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)
# udmap特征和原始数据拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
# 提取eid的频次特征
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())
# 提取eid的标签特征
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())
# 提取时间戳
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour
# 导入模型
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
# 导入交叉验证和评价指标
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_report
# 训练并验证SGDClassifier
pred = cross_val_predict(
SGDClassifier(max_iter=20),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target'],
)
print(classification_report(train_data['target'], pred, digits=3))
D:\Anaconda\lib\site-packages\sklearn\linear_model\_stochastic_gradient.py:577: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.
ConvergenceWarning)
D:\Anaconda\lib\site-packages\sklearn\linear_model\_stochastic_gradient.py:577: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.
ConvergenceWarning)
D:\Anaconda\lib\site-packages\sklearn\linear_model\_stochastic_gradient.py:577: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.
ConvergenceWarning)
D:\Anaconda\lib\site-packages\sklearn\linear_model\_stochastic_gradient.py:577: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.
ConvergenceWarning)
D:\Anaconda\lib\site-packages\sklearn\linear_model\_stochastic_gradient.py:577: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.
ConvergenceWarning)
precision recall f1-score support
0 0.865 0.767 0.813 533155
1 0.159 0.269 0.200 87201
accuracy 0.697 620356
macro avg 0.512 0.518 0.507 620356
weighted avg 0.766 0.697 0.727 620356
# 训练并验证DecisionTreeClassifier
pred = cross_val_predict(
DecisionTreeClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target'],
cv=5
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support
0 0.955 0.951 0.953 533155
1 0.708 0.725 0.716 87201
accuracy 0.919 620356
macro avg 0.831 0.838 0.835 620356
weighted avg 0.920 0.919 0.920 620356
# 训练并验证MultinomialNB
pred = cross_val_predict(
MultinomialNB(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support
0 0.891 0.738 0.808 533155
1 0.220 0.450 0.295 87201
avg / total 0.797 0.698 0.736 620356
# 训练并验证RandomForestClassifier
pred = cross_val_predict(
RandomForestClassifier(n_estimators=5),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support
0 0.936 0.964 0.950 533155
1 0.732 0.595 0.656 87201
accuracy 0.912 620356
macro avg 0.834 0.780 0.803 620356
weighted avg 0.907 0.912 0.909 620356
编写代码回答下面的问题:
- 在上面模型中哪一个模型的macro F1效果最好,为什么这个模型效果最好?
- 使用树模型训练,然后对特征重要性进行可视化;
- 再加入3个模型训练,对比模型精度;
问题一:在上面模型中哪一个模型的macro F1效果最好,为什么这个模型效果最好?
决策树的F1分数最好,是因为它的建模能力和解释性使其适用于许多问题。
问题二:使用树模型训练,然后对特征重要性进行可视化;
train_data.columns.drop(['udmap', 'common_ts', 'uuid', 'target'])
Index(['eid', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8',
'udmap_isunknown', 'key1', 'key2', 'key3', 'key4', 'key5', 'key6',
'key7', 'key8', 'key9', 'eid_freq', 'eid_mean', 'common_ts_hour'],
dtype='object')
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.tree import export_graphviz
import graphviz
%matplotlib inline
X = train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
y = train_data['target']
# 训练模型
dt_model = DecisionTreeClassifier()
dt_model.fit(X[0], y)
DecisionTreeClassifier()
tmp_dot_file = 'decision_tree_tmp.dot'
export_graphviz(dt_model, out_file=tmp_dot_file, feature_names=X[0].columns, class_names="target",filled=True, impurity=False)
with open(tmp_dot_file) as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
plt.figure(figsize=(18,12))
# 绘制图像
_ = plot_tree(dt_model,filled = True,feature_names=X[0].columns) # 由于返回值不重要,因此直接用下划线接收
plt.show()
问题三:再加入3个模型训练,对比模型精度;
这里分别采用默认参数的岭回归分类器、极度随机树和梯度提升树进行训练得到结果
from sklearn.linear_model import RidgeClassifier
from sklearn.tree import ExtraTreeClassifier
from sklearn.ensemble import GradientBoostingClassifier
pred = cross_val_predict(
RidgeClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support
0 0.866 0.996 0.926 533155
1 0.703 0.057 0.105 87201
accuracy 0.864 620356
macro avg 0.784 0.526 0.516 620356
weighted avg 0.843 0.864 0.811 620356
pred = cross_val_predict(
ExtraTreeClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support
0 0.936 0.935 0.935 533155
1 0.604 0.609 0.607 87201
accuracy 0.889 620356
macro avg 0.770 0.772 0.771 620356
weighted avg 0.889 0.889 0.889 620356
pred = cross_val_predict(
BaggingClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support
0 0.949 0.978 0.963 533155
1 0.834 0.677 0.747 87201
accuracy 0.936 620356
macro avg 0.891 0.828 0.855 620356
weighted avg 0.933 0.936 0.933 620356
任务2.3:特征工程
train_data['common_ts_day'] = train_data['common_ts'].dt.day
test_data['common_ts_day'] = test_data['common_ts'].dt.day
train_data['x1_freq'] = train_data['x1'].map(train_data['x1'].value_counts())
test_data['x1_freq'] = test_data['x1'].map(train_data['x1'].value_counts())
train_data['x1_mean'] = train_data['x1'].map(train_data.groupby('x1')['target'].mean())
test_data['x1_mean'] = test_data['x1'].map(train_data.groupby('x1')['target'].mean())
train_data['x2_freq'] = train_data['x2'].map(train_data['x2'].value_counts())
test_data['x2_freq'] = test_data['x2'].map(train_data['x2'].value_counts())
train_data['x2_mean'] = train_data['x2'].map(train_data.groupby('x2')['target'].mean())
test_data['x2_mean'] = test_data['x2'].map(train_data.groupby('x2')['target'].mean())
##x3_freq和x4_freq存在为nan的值
#train_data['x3_freq'] = train_data['x3'].map(train_data['x3'].value_counts())
#test_data['x3_freq'] = test_data['x3'].map(train_data['x3'].value_counts())
#train_data['x4_freq'] = train_data['x4'].map(train_data['x4'].value_counts())
#test_data['x4_freq'] = test_data['x4'].map(train_data['x4'].value_counts())
train_data['x6_freq'] = train_data['x6'].map(train_data['x6'].value_counts())
test_data['x6_freq'] = test_data['x6'].map(train_data['x6'].value_counts())
train_data['x6_mean'] = train_data['x6'].map(train_data.groupby('x6')['target'].mean())
test_data['x6_mean'] = test_data['x6'].map(train_data.groupby('x6')['target'].mean())
train_data['x7_freq'] = train_data['x7'].map(train_data['x7'].value_counts())
test_data['x7_freq'] = test_data['x7'].map(train_data['x7'].value_counts())
train_data['x7_mean'] = train_data['x7'].map(train_data.groupby('x7')['target'].mean())
test_data['x7_mean'] = test_data['x7'].map(train_data.groupby('x7')['target'].mean())
train_data['x8_freq'] = train_data['x8'].map(train_data['x8'].value_counts())
test_data['x8_freq'] = test_data['x8'].map(train_data['x8'].value_counts())
train_data['x8_mean'] = train_data['x8'].map(train_data.groupby('x8')['target'].mean())
test_data['x8_mean'] = test_data['x8'].map(train_data.groupby('x8')['target'].mean())
train_data.head()
| uuid | eid | udmap | common_ts | x1 | x2 | x3 | x4 | x5 | x6 | ... | x1_freq | x1_mean | x2_freq | x2_mean | x6_freq | x6_mean | x7_freq | x7_mean | x8_freq | x8_mean | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 26 | {"key3":"67804","key2":"650"} | 2023-07-18 09:44:28.244 | 4 | 0 | 41 | 107 | 206 | 1 | ... | 381218 | 0.139332 | 272402 | 0.126622 | 226935 | 0.153811 | 39042 | 0.358153 | 530689 | 0.12232 |
| 1 | 1 | 26 | {"key3":"67804","key2":"484"} | 2023-07-11 13:42:21.469 | 4 | 0 | 41 | 24 | 283 | 4 | ... | 381218 | 0.139332 | 272402 | 0.126622 | 392989 | 0.133067 | 77262 | 0.114649 | 530689 | 0.12232 |
| 2 | 2 | 8 | unknown | 2023-07-15 07:49:53.040 | 4 | 0 | 41 | 71 | 288 | 4 | ... | 381218 | 0.139332 | 272402 | 0.126622 | 392989 | 0.133067 | 185272 | 0.107151 | 530689 | 0.12232 |
| 3 | 3 | 11 | unknown | 2023-07-16 00:36:55.688 | 1 | 3 | 41 | 17 | 366 | 1 | ... | 95663 | 0.130155 | 125743 | 0.130671 | 226935 | 0.153811 | 130071 | 0.091688 | 530689 | 0.12232 |
| 4 | 4 | 26 | {"key3":"67804","key2":"650"} | 2023-07-16 07:15:51.442 | 0 | 3 | 41 | 92 | 383 | 4 | ... | 124004 | 0.136342 | 125743 | 0.130671 | 392989 | 0.133067 | 77262 | 0.114649 | 530689 | 0.12232 |
5 rows × 37 columns
# 训练并验证DecisionTreeClassifier
pred = cross_val_predict(
DecisionTreeClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support
0 0.955 0.950 0.952 533155
1 0.704 0.724 0.714 87201
accuracy 0.918 620356
macro avg 0.829 0.837 0.833 620356
weighted avg 0.919 0.918 0.919 620356
# 8. 加载决策树模型进行训练(直接使用sklearn中导入的包进行模型建立)
clf = DecisionTreeClassifier()
# 使用 fit 方法训练模型
# train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1) 从训练数据集中移除列 'udmap', 'common_ts', 'uuid', 'target'
# 这些列可能是特征或标签,取决于数据集的设置
# train_data['target'] 是训练数据集中的标签列,它包含了每个样本的目标值
clf.fit(
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1), # 特征数据:移除指定的列作为特征
train_data['target'] # 目标数据:将 'target' 列作为模型的目标进行训练
)
# 9. 对测试集进行预测,并保存结果到result_df中
# 创建一个DataFrame来存储预测结果,其中包括两列:'uuid' 和 'target'
# 'uuid' 列来自测试数据集中的 'uuid' 列,'target' 列将用来存储模型的预测结果
result_df = pd.DataFrame({
'uuid': test_data['uuid'], # 使用测试数据集中的 'uuid' 列作为 'uuid' 列的值
'target': clf.predict(test_data.drop(['udmap', 'common_ts', 'uuid'], axis=1)) # 使用模型 clf 对测试数据集进行预测,并将预测结果存储在 'target' 列中
})
#由于这里进行特征工程后存在为0的值表示为nan,我们将nan值填充为0