Zookeeper单机集群部署
目录
一、伪集群搭建
1、搭建准备
2、开始搭建
3、集群启动
二、Zookeeper分布式存储
1、Zookeeper存储模型
2、zkCli客户端指令清单
3、zk客户端
1.zk官方java客户端api
2.第三方的java客户端api
3、Curator客户端
一、伪集群搭建
1、搭建准备
1、zk下载地址:https://archive.apache.org/dist/zookeeper/
2、集群节点数必须是基数,通过选举确定主节点,选举规则:可用节点数>总节点数/2(防止脑裂(分裂成多个集群)、zk/es)
3、zk集群至少有3个节点
2、开始搭建
- 创建数据目录和日志目录:(/data/zoo-1、/data/zoo-2、/data/zoo-3 | /log/zoo-1、/log/zoo-2、/log/zoo-3)
- 每个节点数据目录(/data/zoo-*/)下创建myid文本文件
- myid文本文件的唯一作用是存放集群编号
- myid文件是一个文本文件,名称为myid
- myid文件内容为一个数字,表示节点编号
- myid文件中只能有一个数字,不能有其它内容
- myid文件默认存放在data目录下
- id的范围是1~255,表示集群最多有255个节点
- 创建和修改配置文件
- 将/conf目录中配置文件的样例zoo_sample.cfg文件复制三份,为每一个节点复制一份
cp zoo_sample.cfg zoo-1.cfg
cp zoo_sample.cfg zoo-2.cfg
cp zoo_sample.cfg zoo-3.cfg
- 修改每个节点的zoo-*.cfg文件
- dataDir:数据目录选项,配置为前面准备的数据目录。非常关键的myid文件处于此目录下
- dataLogDir:日志目录选项,配置为前面准备的日志目录。如果没有设置该参数,默认将使用和dataDir相同的设置
- 配置集群中的端口信息、节点信息、时间选项等
- clientPort=2181/2182/2183 选项clientPort表示客户端程序连接ZooKeeper集群中节点的端口号,不同节点端口不能冲突
- 集群节点信息配置,在ZooKeeper集群中,每个节点都需要感知到整个集群是由哪些节点组成的,所以每个配置文件都需要配置全部节点
- server.1=172.0.0.1:2181:2291
- server.2=172.0.0.1:2182:2292
- server.3=172.0.0.1:2183:2293
server.id:host:port:port
id值需要与所对应节点的数据目录下的myid中的id值保持一致
前一个端口(如示例中的2888)用于节点之间的通信,为通信端口;后一个端口(如示例中的3888)用于选举Leader主节点,为选主端口
- 时间相关配置
tickTime=4000
initLimit=10
syncLimit=5
tickTime:配置单元时间。单元时间是ZooKeeper的时间计算单元,其他的时间间隔都是使用tickTime的倍数来表示的。如果不进行配置,则单元时间默认值为3000,单位是毫秒(ms)
initLimit:节点的初始化时间。该参数用于Follower(从节点)启动,并完成从Leader(主节点)同步数据的时间。Follower节点在启动过程中会与Leader建立连接并完成对数据的同步,从而确定自己的起始状态。Leader节点允许Follower在initLimit时间内完成这个工作。该参数的默认值为10,表示是参数tickTime值的10倍。此参数必须配置,且为正整数
syncLimit:心跳最大延迟周期。该参数用于配置Leader服务器和Follower之间进行心跳检测的最大延时时间。在ZooKeeper集群运行的过程中,Leader服务器会通过心跳检测来确定Follower服务器是否存活。如果Leader服务器在syncLimit时间内无法获取到Follower的心跳检测响应,那么Leader就会认为该Follower已经脱离了与自己的同步。该参数默认值为5,表示是参数tickTime值的5倍。此参数必须配置,且为正整数
- 将/conf目录中配置文件的样例zoo_sample.cfg文件复制三份,为每一个节点复制一份
- .cfg文件配置示例
tickTime=4000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-3.4.14/data/zoo-1
dataLogDir=/usr/local/zookeeper-3.4.14/log/zoo-1
clientPort=2181
server.1=172.0.0.1:2181:2281
server.2=172.0.0.1:2182:2282
server.3=172.0.0.1:2183:2283
3、集群启动
1.启动集群
/usr/local/zookeeper-3.4.14/bin/zkServer.sh start zoo-1.cfg
/usr/local/zookeeper-3.4.14/bin/zkServer.sh start zoo-2.cfg
/usr/local/zookeeper-3.4.14/bin/zkServer.sh start zoo-3.cfg
2.连接zk客户端
./zkCli.sh -timeout 0 -r -server ip:port
-timeout:当前会话的超时时间,zookeper依靠与客户端的心跳来判断会话是否有效,单位是毫秒
-r: 只读模式,zookeeper的只读模式指一个服务器与集群中过半机器失去连接以后,这个服务器就不在不处理客户端的请求,但我们仍然希望该服务器可以提供读服务。
-server: zookeeper服务器ip地址和端口号/usr/local/zookeeper-3.4.14/bin/zkCli.sh -server 172.0.0.1:2181
二、Zookeeper分布式存储
1、Zookeeper存储模型
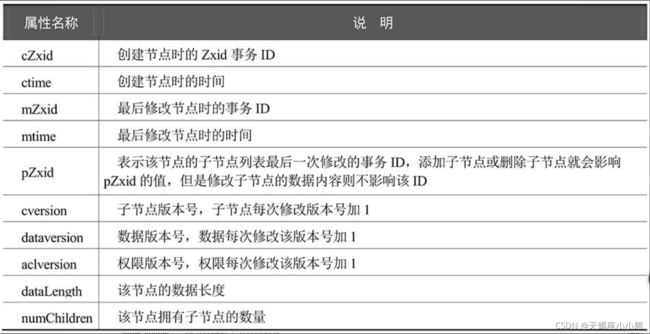
ZooKeeper的存储模型是一棵以"/"为根节点的树,存储模型中的每一个节点叫作ZNode(ZooKeeperNode)节点。所有的ZNode节点通过树的目录结构按照层次关系组织在一起,构成一棵ZNode树
通过ZNode树,ZooKeeper提供一个多层级的树状命名空间。该树状命名空间与文件目录系统中的目录树有所不同,这些ZNode节点可以保存二进制负载数据(Payload)。文件系统目录树中的目录只能存放路径信息,而不能存放负载数据
ZooKeeper为了保证高吞吐和低延迟,整个树状的目录结构全部都放在内存中。ZooKeeper官方的要求是,每个节点存放的Payload负载数据的上限仅仅为1MB
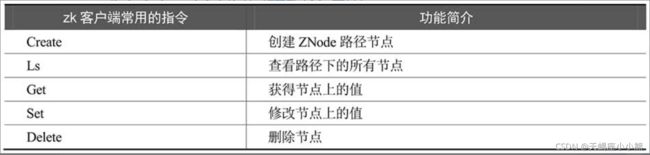
2、zkCli客户端指令清单
连接客户端,使用help查看所有指令
ZNode节点信息主要信息
3、zk客户端
1.zk官方java客户端api
ZooKeeper官方的客户端API提供了基本的操作,比如创建会话、创建节点、读取节点、更新数据、删除节点和检查节点是否存在等
(1)ZooKeeper的Watcher监测是一次性的,每次触发之后都需要重新进行注册。
(2)Session超时之后没有实现重连机制。
(3)异常处理烦琐,ZooKeeper提供了很多异常,对于开发人员来说可能根本不知道该如何处理这些异常信息。
(4)只提供了简单的byte[]数组类型的接口,没有提供JavaPOJO级别的序列化数据处理接口。(5)创建节点时如果节点存在抛出异常,就需要自行检查节点是否存在。(6)无法实现级联删除。
2.第三方的java客户端api
1.zkClient客户端
ZkClient是一个开源客户端,在ZooKeeper原生API接口的基础上进行了包装,更便于开发人员使用
(1)ZkClient社区不活跃,文档不够完善,几乎没有参考文档。
(2)异常处理简化(抛出RuntimeException)。
(3)重试机制比较难用。
(4)没有提供各种使用场景的参考实现
2.Curator客户端
Curator是Netflix公司开源的一套ZooKeeper客户端框架。和ZkClient一样,Curator提供了非常底层的细节开发工作,包括Session会话超时重连、掉线重连、反复注册Watcher和NodeExistsException异常等
(1)具有更加完善的文档,另外还提供了一套易用性和可读性更强的Fluent风格的客户端API框架
(2)Curator还提供了ZooKeeper一些比较普遍的分布式开发的开箱即用的解决方案,比如Recipes、共享锁服务、Master选举机制和分布式计算器等
(3)Curator提供了一套非常优雅的链式调用API
3、Curator客户端
(1)curator-framework:对ZooKeeper底层API的一些封装。
(2)curator-client:提供一些客户端的操作,例如重试策略等。
(3)curator-recipes:封装了一些高级特性,如Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等。