Elasticsearch相关 ES
Elastic 详尽文档:https://elasticstack.blog.csdn.net/article/details/102728604
文章目录
- 倒排索引
- 分词
-
- 内置的分词器
- IK分词器
-
- ik分词器下载地址:
- Ik有两种颗粒度的拆分
- IK 扩展和停用词典
- 远程扩展IK字典
-
- 1. 在Nginx中配置
- 2.连接mysql
- 3. 接口扩展
- 拼音分词器
-
- 自动补全suggest
- 同位词
- 集群
-
- 路由计算
- 保存数据
- 读数据
- ES 脑裂
- 分片规划
- ES与DB的关系
- 查询相关
-
- 分布式计分
-
-
- TF-IDF
- BM25
-
- 打分示例
-
-
- Boost得分:
- TF得分:
- IDF得分:
-
- BM25参数调节
- Mapping相关
-
- term查询,match查询,match_phrase查询
-
- term查询
- match查询:
- match_phrase短语查询,
- fuzzy模糊查询
- 多字段查询multi_match
-
- 1.best_fields
- 2.most_fields
- 2.cross_fields
- 所有字段分词查询(query_string)
- 高亮查询
- filter查询
- ES并发
倒排索引
| id | Title | Price | Description |
|---|---|---|---|
| 1 | 蓝月亮洗衣液 | 19.9 | 洗衣液很高效哟 |
| 2 | iPhone13 | 19.9 | 很不错的手机 |
| 3 | 小浣熊干脆面 | 2.5 | 很好吃 |
title:keyword类型,不分词
Price:double类型 不分词
Description:text 类型 分词
按照默认的分词器,索引情况如下

通常仅知道关键词在哪些文章中出现还不够,我们还需要知道关键词在文章中出现次数和出现的位置,通常有两种位置:
a.字符位置,即记录该词是文章中第几个字符(优点是关键词亮显时定位快);
b.关键词位置,即记录该词是文章中第几个关键词(优点是节约索引空间、词组(phase)查询快),lucene中记录的就是这种位置。
关键字每个文档中,出现频率相同的情况下,字数最少,得分越高,如果频率越高,得分越高
如果查询“很”,排名为3->2->1
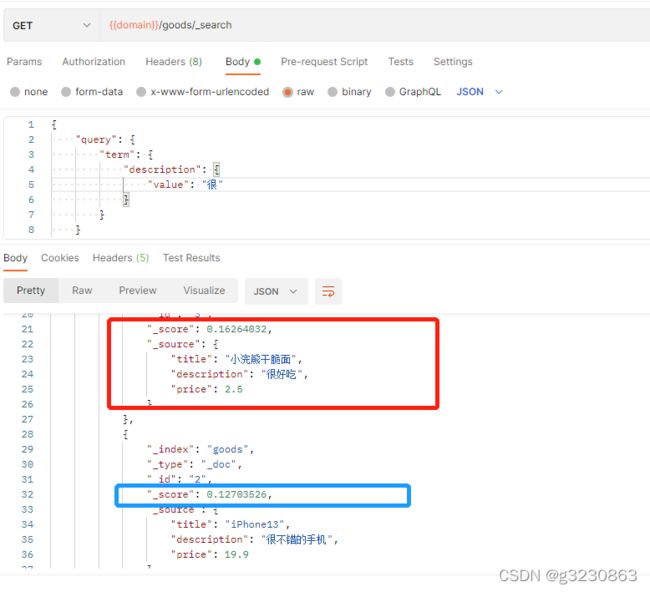
如果频率一样,给3号文档添加几个字,那么排名就变化了,2->1->3
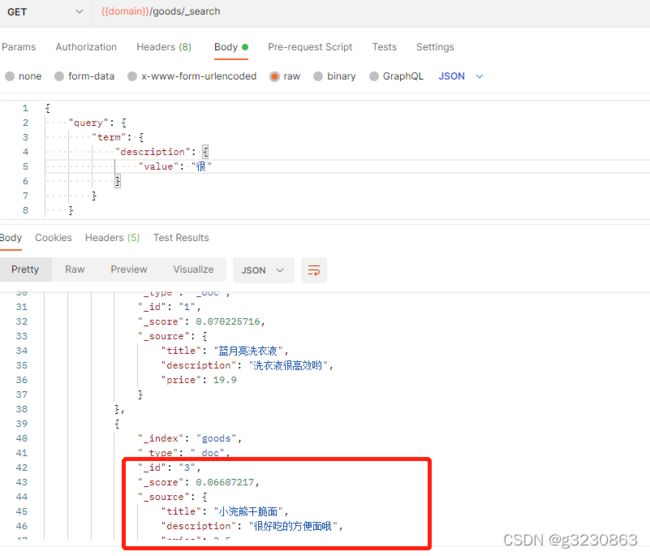
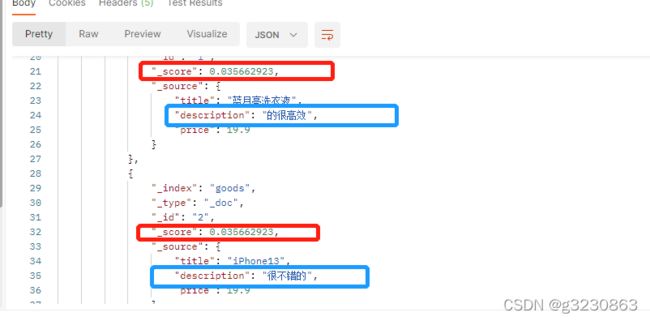
如果1,2,3文档的字数一样,频率一样,得分是一样的,1->2->3,跟“很”出现在什么位置无关
分词

character filter 和Token filter (0或者多个)
keyword类型,integer类型,double类型,data类型 不分词
text类型分词,聚合、排序操作没有意义的
内置的分词器

IK分词器
ik分词器下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.14.0
一定要与es的大小版本对应,不然会有问题
把下载后的文件解压放到es 的plugins文件夹中,重新启动es。
Ik有两种颗粒度的拆分
ik_smart:会做最粗粒度的拆分 ik_max_word:会将文本做最细粒度的拆分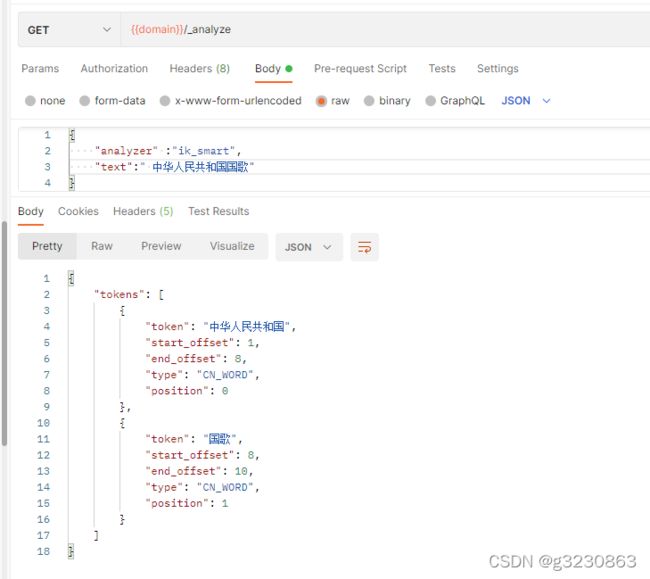
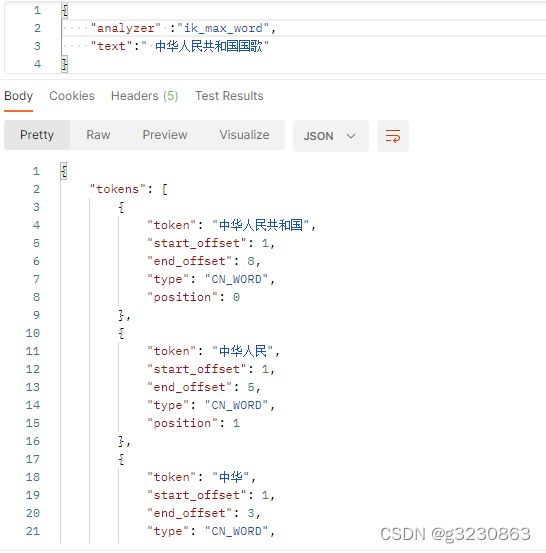
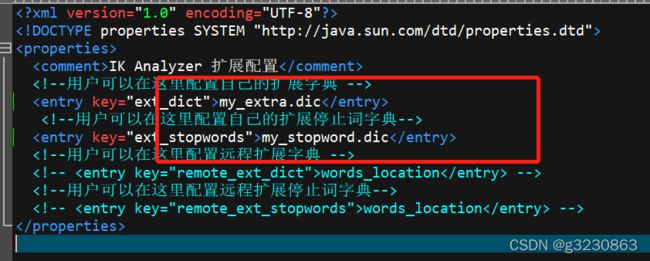
IK 扩展和停用词典

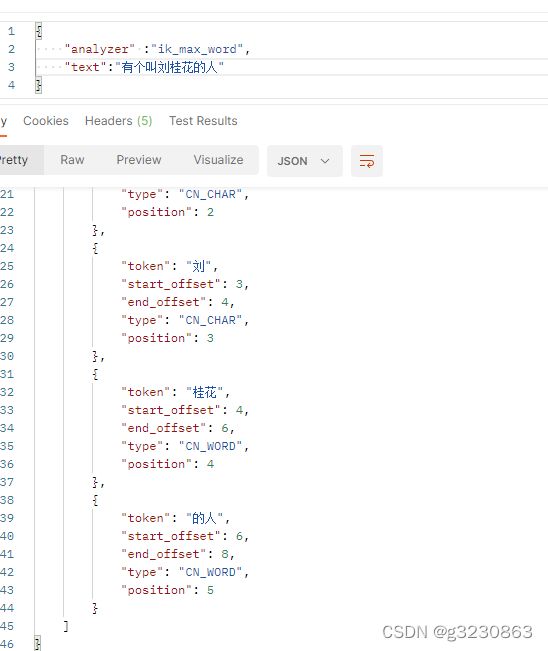
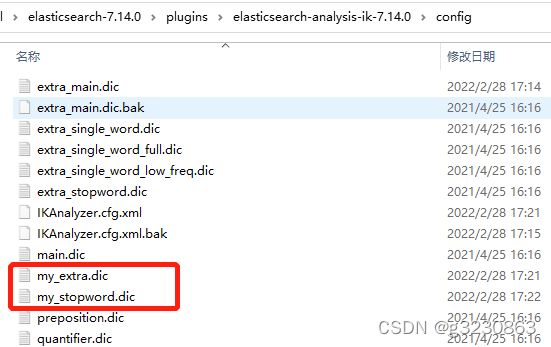
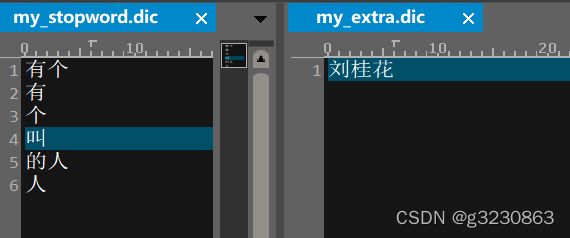
配置自己的扩展和停用词典
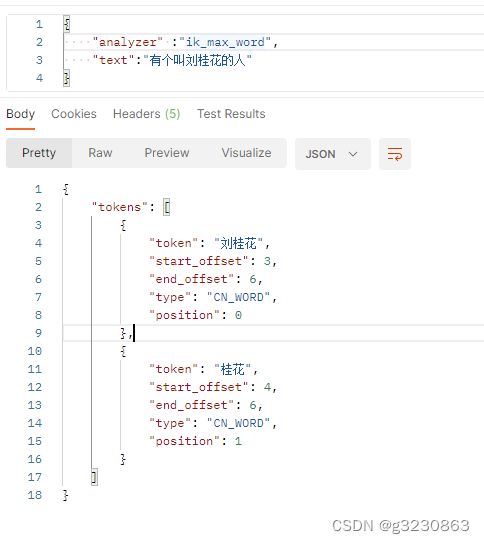
去除了一些无效的关键词,新增了一个关键词
远程扩展IK字典
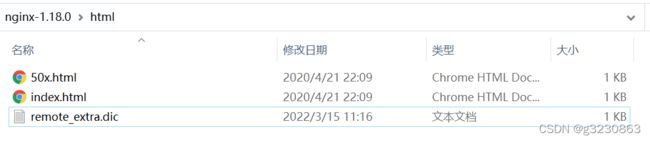
1. 在Nginx中配置
在html中配置一个utf-8文件,写后预计1分钟后生效
切记不支持HTTPS、切记不支持HTTPS、切记不支持HTTPS,配置是http实际域名解析是https也不可以


2.连接mysql
https://blog.csdn.net/qq_39140300/article/details/110382612?ops_request_misc=&request_id=&biz_id=102&utm_term=elasticsearch%20%20%E8%BF%9C%E7%A8%8B%E6%89%A9%E5%B1%95%E5%AD%97%E5%85%B8&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1-110382612.142v2pc_search_result_control_group,143v4register&spm=1018.2226.3001.4187
3. 接口扩展
还是在IKAnalyzer.cfg.xml中间中配置远程扩展地址。
原理:IK分词器会启动一个线程,每一分钟进行扫描一次变化,保存上一次的Last-Modified 根据响应的上次修改时间与保存的上次修改时间判断远程文件是否变化,变化的话重新加载远程文件
代码如下
https://gitee.com/xutuos/codes/qrdoevf6ukw49pyt7zjca35
拼音分词器
https://github.com/medcl/elasticsearch-analysis-pinyin
创建一个索引
分词器由三部分组成,char_filter和filter可以有可无,
下面定义了一个过滤html标签的char_filter.自定义了一个tokenizer。
定义了自由一个字段name,按照拼音进行分词,但是查询的时候用keyword,不能切分词查询。
同理可以按照ik_max_word进行分词,按照ik_smart来进行查询
{
"settings": {
"analysis": {
"analyzer": {
"pinyin_analyzer": {
"char_filter":["html_strip"],
"tokenizer": "my_pinyin"
}
},
"tokenizer": {
"my_pinyin": {
"type": "pinyin",
"keep_separate_first_letter": false,
"keep_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"lowercase": true,
"remove_duplicated_term": true
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "completion",
"analyzer": "pinyin_analyzer",
"search_analyzer": "keyword"
}
}
}
}
插入数据
{"index":{"_id":1}}
{"name":"刘德华"}
{"index":{"_id":2}}
{"name":"郭富城"}
{"index":{"_id":3}}
{"name":"张学友"}
{"index":{"_id":4}}
{"name":"黎明"}
自动补全suggest
通过前缀prefix查询实现自动补全的功能
{
"_source":false,
"suggest":{
"star_name_suggest":{
"prefix":"liu",
"completion":{
"field":"name",
"size":10,
"skip_duplicates":true
}
}
}
}
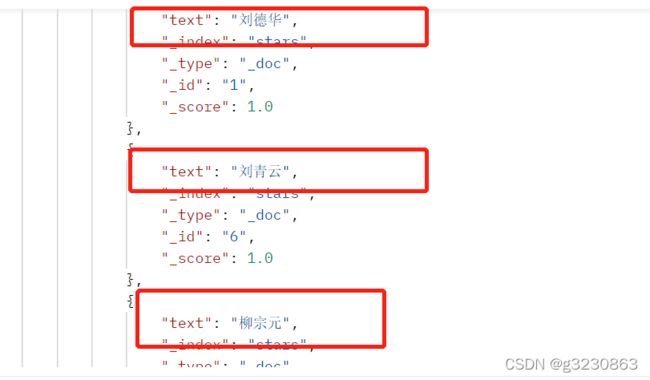
能把刘和柳等开头的数据都查出来
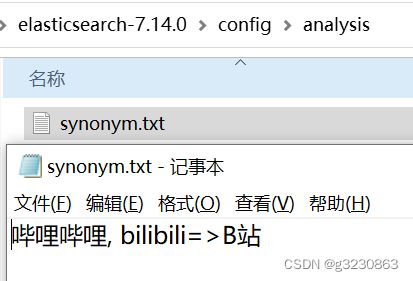
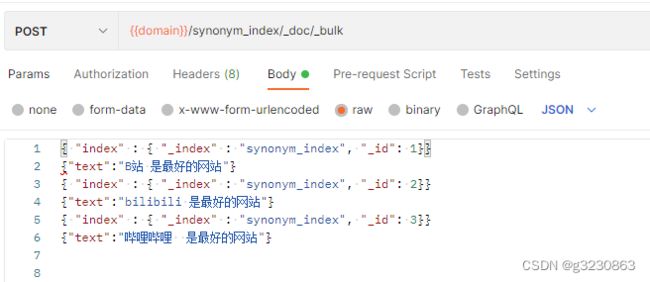
同位词
会找出等价的词语
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_smart",
"filter": [
"lowercase",
"my_synonym"
]
}
},
"filter": {
"my_synonym": {
"type": "synonym",
"synonyms_path": "analysis/synonym.txt"
}
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
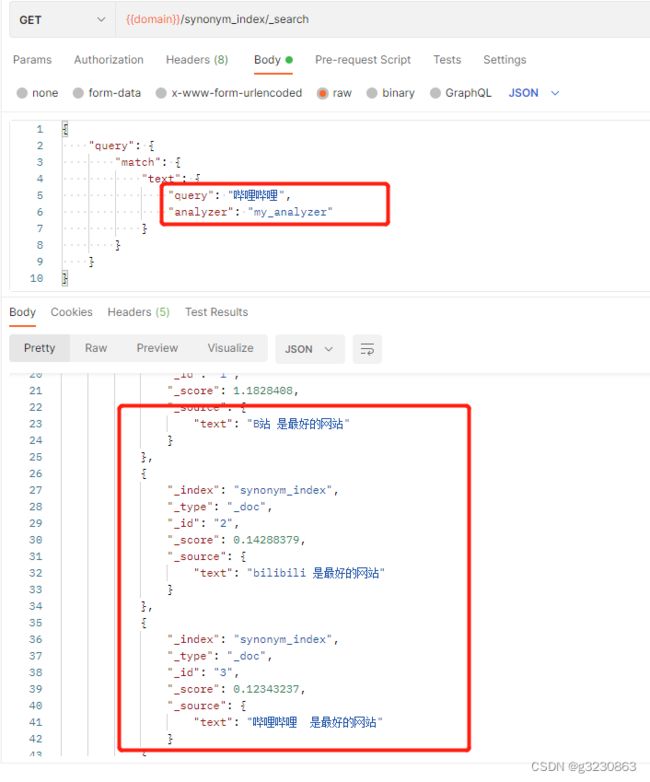
集群
一个索引3片,一个备份
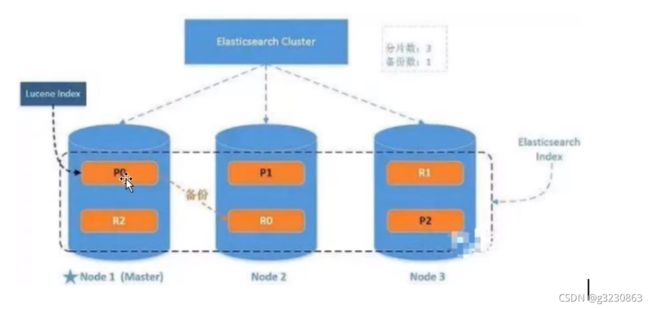
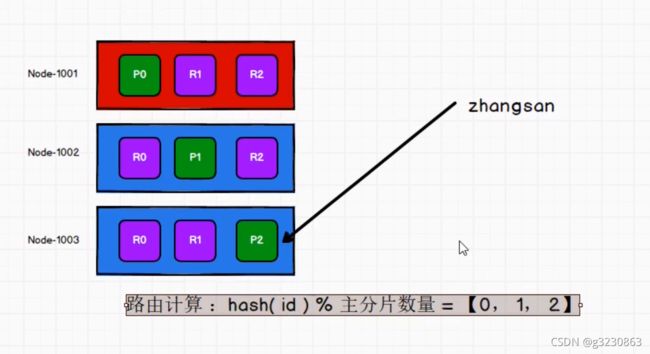
路由计算
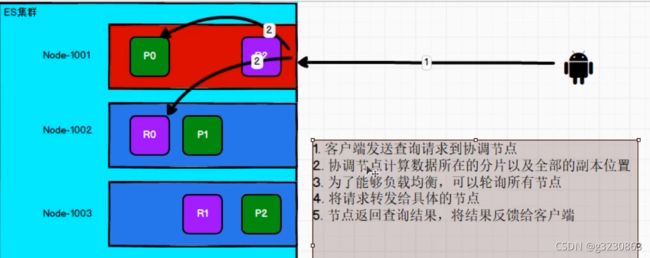
下图绿色为主分片节点,紫色为备份分片节点
在插入数据的时候,路由到哪个集群的算法:hash(id)%主分片数量
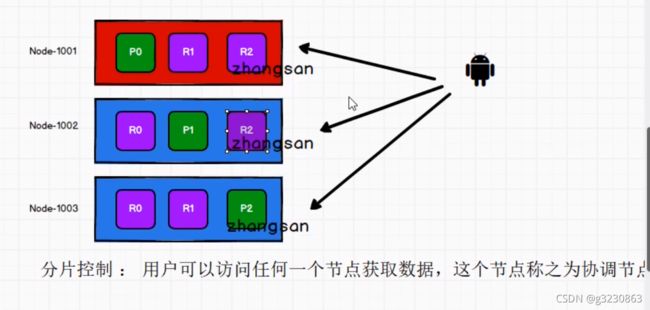
在取数据的时候,用户可以访问任何集群结点,这个节点是协调节点,可以通过策略来找到返回数据的结点
保存数据
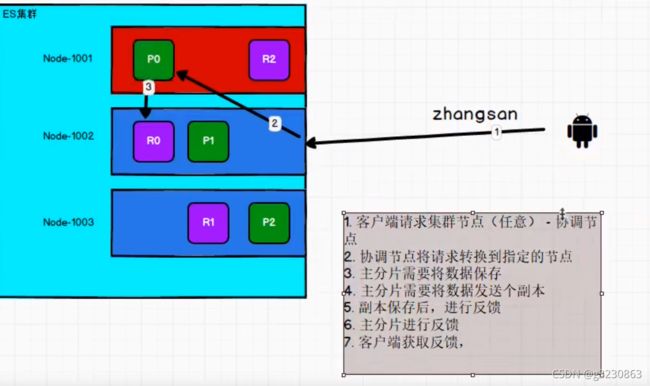
为了提高性能,可以调整2个参数,但有数据不一致的风险

consistency:一致性参数
- quorum,默认值(主分片和大多数副本分片没问题了)
- one:主分片ok了,就能写入
- all:主分片+副本分片的状态都ok了,才能写入
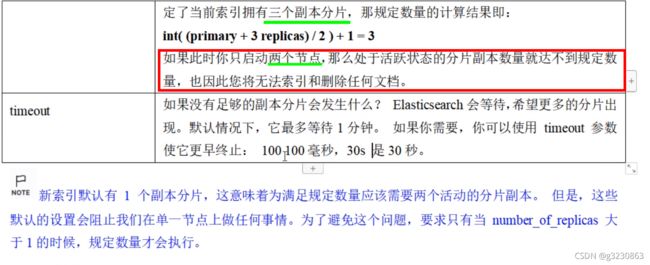
读数据
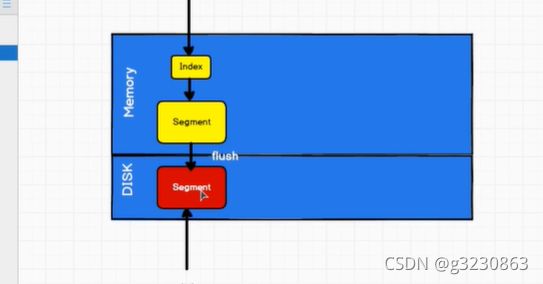
(1)创建好的索引,以断的形式存在内存,然后在flush到硬盘,然后才能读取索引信息
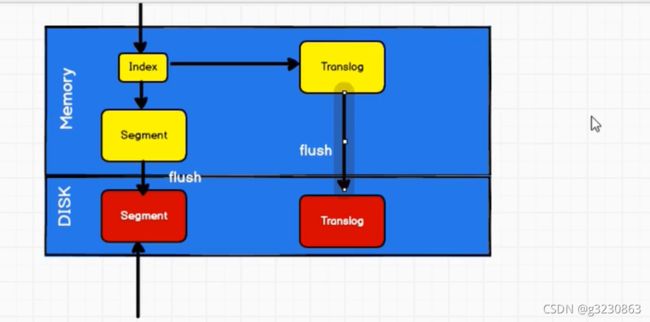
(2)有可能在从内存写入硬盘的时候断电了,数据会丢失,这个时候须有有一个类似mysql的日志文件translog。
先写内存,然后在写translog.是因为内存写入有复杂逻辑,容易失败,避免translog中有很多无效数据,减少恢复的复杂度
(3)只有数据落入硬盘才能读取,为了提高读取的性能,增加了缓冲区OS Cache,内存中的数据每秒refresh到OS中,OS每半个小时flush到硬盘中。或者当translog中的数据达到一定量后或者5秒后,flush到硬盘中
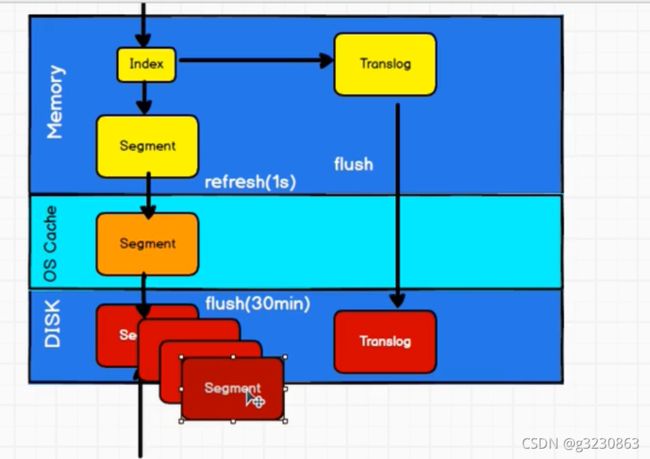
不断地写入硬盘segment后,为了减少文件的数量,会进行合并,进行逻辑的删除,提高访问的效率,倒排索引不可变,删除和更新操作会体现到新的segment中,会增加del文件,合并的时候才会真正的把文件给删除
ES 脑裂
- 主节点:创建索引,删除索引,分配分区,追踪集群中节点状态的工作,工作量相对叫轻,是由候选主节点选举出来的
- 候选主节点:node.master:true,在集群初始化或者主节点宕机时,候选主节点根据规则选主节点
- 数据节点:负责数据的存储,搜索等工作
正常情况下,当主节点无法工作时,会从备选主节点中选举一个出来变成新主节点,原主节点回归后变成备选主节点。但有时因为网络抖动等原因,主节点没能及时响应,集群误以为主节点挂了,选举了一个新主节点,此时一个es集群中有了两个主节点,其他节点不知道该听谁的调度,结果将是灾难性的!这种类似一个人得了精神分裂症,就被称之为“脑裂”现象。
造成es“脑裂”的因素有以下几个:
1、网络抖动
内网一般不会出现es集群的脑裂问题,可以监控内网流量状态。外网的网络出现问题的可能性大些。
2、节点负载
如果主节点同时承担数据节点的工作,可能会因为工作负载大而导致对应的 ES 实例停止响。
3、内存回收
由于数据节点上es进程占用的内存较大,较大规模的内存回收操作也能造成es进程失去响应。
避免es“脑裂”的措施主要有以下三个:
1、不要把主节点同时设为数据节点(node.master和node.data不要同时设为true)
2、将节点响应超时(discovery.zen.ping_timeout)稍稍设置长一些(默认是3秒),避免误判。
3、设置需要超过半数的备选节点同意,才能发生主节点重选,类似需要参议院半数以上通过,才能弹劾现任总统。(discovery.zen.minimum_master_nodes = 半数以上备选主节点数)

分片规划
分片数量有很多因素:使用的硬件、文档的大小和复杂度、文档的索引分析方式、运行的查询类型、执行的聚合以及你的数据模型。
当只有一个节点的时候,可以选择2个分片,便于以后扩容方便,ES自动的扩容。
分片容量计算
跟生产一样的硬件,一个主分片无副本,根据所需要的响应时间,如果50ms。来确定单个分片的容量。
分片数=(预估数据+预估增值)/单个分片容量
增加副本数量可以提高读的性能
ES与DB的关系
ES在保存商品的时候,只保存关键的字段供页面来展示,把常见的搜索关键字放到ES中
DB:商品的详细信息还是放到数据库中,商品的属性很多,很多属性根本不会进行搜索
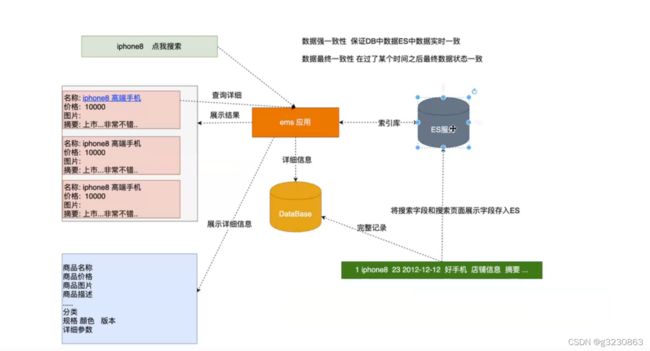
ES与DB的数据同步
强一致性同步:通过API直接调用,或者MQ进行处理
最终一致性:通过定时任务来处理
查询相关
分布式计分

TF-IDF
1.Term Frequency (TF):搜索词在某个文档中的使用频率。在一个字段中该术语出现的越多,这个术语越重要
2.Inverse Document Frequency (IDF):搜索词在所有文档中的唯一性。一个字段在越多的文档中出现,那么这个术语就越不重要,比如 “the”,“to” 等这些词经常出现在一些文档,那么这些词的重要性就不强。
3.Field length:较短的字段比较长的字段更相关

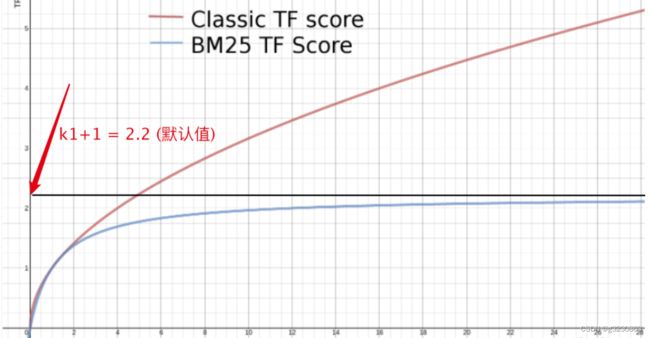
BM25
当文档频率不断增大,TF 得分最大值也就是 k 1 + 1 ,不会像TF那样无限增大。

打分示例
比如下面3个文档
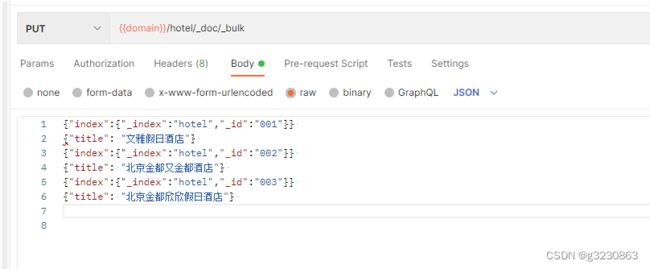
搜索“金都酒店”
{
"explain": true,
"query": { //使用match搜索文档
"match": {
"title": "金都酒店"
}
}
}
根据搜索结果,最高分为 0.7797864, 因为“金都酒店”被分词器分成2个词,所以得分由 总得分=金都得分(0.646255)+酒店得分(0.13353139)构成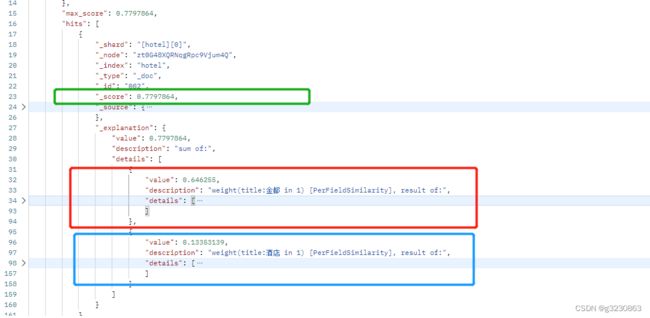
{
"value":0.646255,
"description":"weight(title:金都 in 1) [PerFieldSimilarity], result of:",
"details":[
{
"value":0.646255,
"description":"score(freq=2.0), computed as boost * idf * tf from:",
"details":[
{
"value":2.2,
"description":"boost",
"details":[
]
},
{
"value":0.47000363,
"description":"idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details":[
{
"value":2,
"description":"n, number of documents containing term",
"details":[
]
},
{
"value":3,
"description":"N, total number of documents with field",
"details":[
]
}
]
},
{
"value":0.625,
"description":"tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details":[
{
"value":2,
"description":"freq, occurrences of term within document",
"details":[
]
},
{
"value":1.2,
"description":"k1, term saturation parameter",
"details":[
]
},
{
"value":0.75,
"description":"b, length normalization parameter",
"details":[
]
},
{
"value":5,
"description":"dl, length of field",
"details":[
]
},
{
"value":5,
"description":"avgdl, average length of field",
"details":[
]
}
]
}
]
}
]
}
BM25得分有三分部分构成:boost 得分,IDF 得分, TF得分构成

Boost得分:
因为在默认情况下k1=1.2,所以boost=k1+1=1+1.2=2.2
TF得分:
freq / (freq + k1 * (1 - b + b * dl / avgdl))
根据下面的公式,默认情况下b的值为0.75.
f(qi,D) 为"金都"在文档中的出现频率 =2
fieldLen: 文档被分词以后词语的个数,“北京金都又金都酒店” 用ik_max_word 分词器,能分5个词,所以fieldLen=5
avgdl: 平均字段长度,所有字段长度/文档数量。 第一个文档分词数量4,第二个文档分词数量5,第三个分词数量6,
所以avgdl=(4=5+6)/3=5
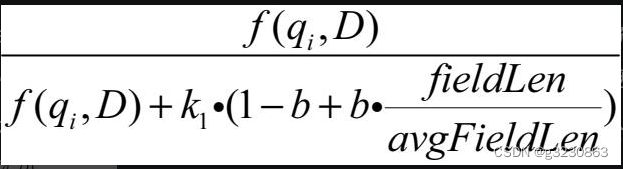
所以TF(金都)=0.625

IDF得分:

idf的计算为 log(1 + (N - n + 0.5) / (n + 0.5))
其中N为文档中带有title字段的数量(文档中可以不带title),所有文档数量N=3;
n为带有当前查询关键字的文档数量,只有2个文档带有“金都”,所以n=2;
idf = log(1+(3-2+0.5)/(2+0.5))=0.47000362925(注意这里的log对数计算未指定底数,其实用的就是e,在计算器上为In)
所以“金都”在文档2“北京金都又金都酒店”的得分为
boost * IDF * TF =2.20.6250.47000362925=0.64625499022
BM25参数调节
参考:https://jiuaidu.com/jianzhan/933652/
默认情况下 k=1.2 ,b=0.75,使用默认值就有不错的搜索效果,同时也可以通过下面参数进行调解
k1 :词语在文档中出现的次数对于得分的重要性,因为当词频足够大时,TF 得分最大值也就是 k 1 + 1 。b:如果b较大,则文档长度相对于平均长度的影响更大。 可以想象如果将b设置为0,那么长度比率的影响将完全无效,文档的长度将与分数无关
参数k1的值一般介于1.2~2.0,参数b的值一般为0.3~0.9
{
"settings": {
"similarity":{
"mybm25":{ //自定义相似度算法
"type":"BM25",
"b":0.7, //设置b参数的值
"k1":2 //设置k1参数的值
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"similarity": "mybm25" //设置title字段匹配打分时使用自定义的相似度算法
}
}
}
}
可以看到boost 和TF都有变化
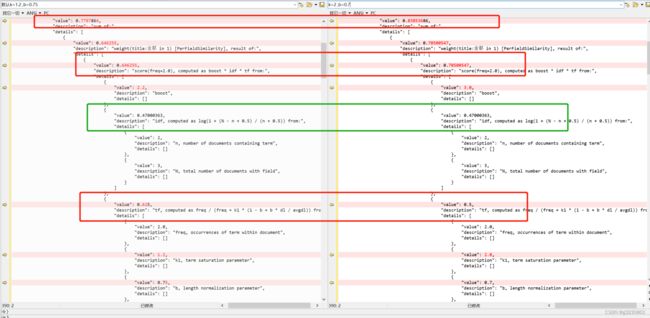
在不同的场景中,b和k1的取值是不同的,没有放之四海而皆准的方案,需要不断地调试并观察它们对于总体排序的影响,这样才能获得符合当前场景预期的排序结果的最佳方案。
https://weread.qq.com/web/reader/710325a07279806471049d0k9b832a602829b86192511b5
参考:https://elasticstack.blog.csdn.net/article/details/104132454
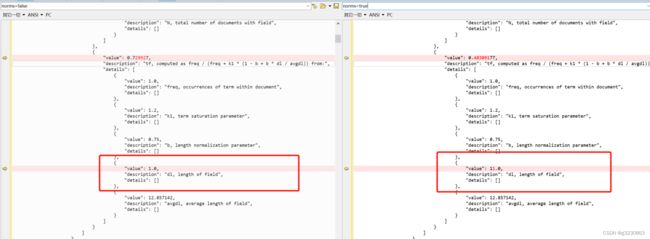
当计算得分的时候,是否需要把字段长度用作参数计算
如果字段设置norms:false,也会影响TF的得分

如果设成false,则BM25算法中dl=1. (dl为查询词分词的数量) tf的分数会变大
Mapping相关
text类型是要分词的,分词的做聚合和排序没有太多意义,如果以后要用到聚合和排序,需要开启fieldata,使用字段.keyword来处理
mapping相关参考:https://blog.csdn.net/ZYC88888/article/details/83059040
term查询,match查询,match_phrase查询
https://blog.csdn.net/tclzsn7456/article/details/79956625
如果想使用精确查询,而且想要匹配的更多,可以使用match_phase
description使用ik_max_word来分词。
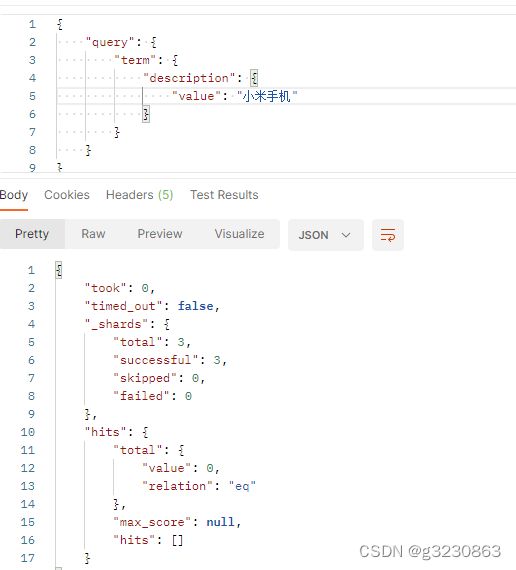
term查询
term是关键词匹配,用整体去匹配字段中的分词,description分词后没有“小米手机”这个词,所以没有查到
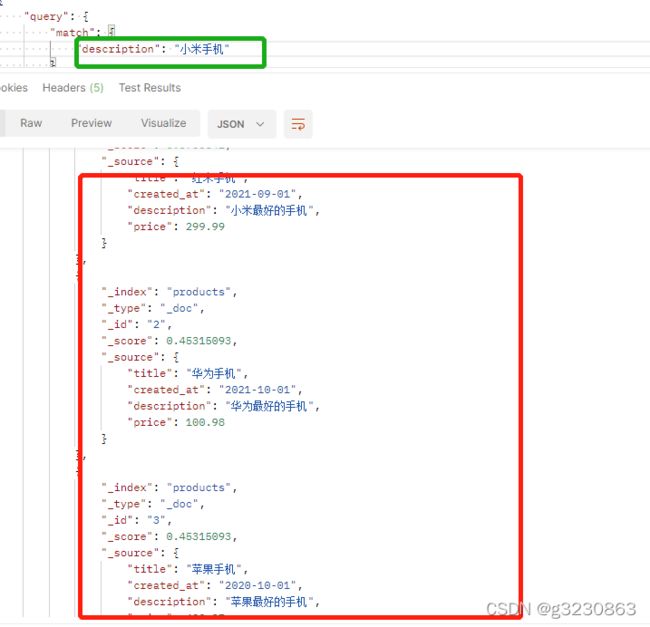
match查询:
会把小米手机进行分词后在查询,所以把所有小米和手机相关的都查到了
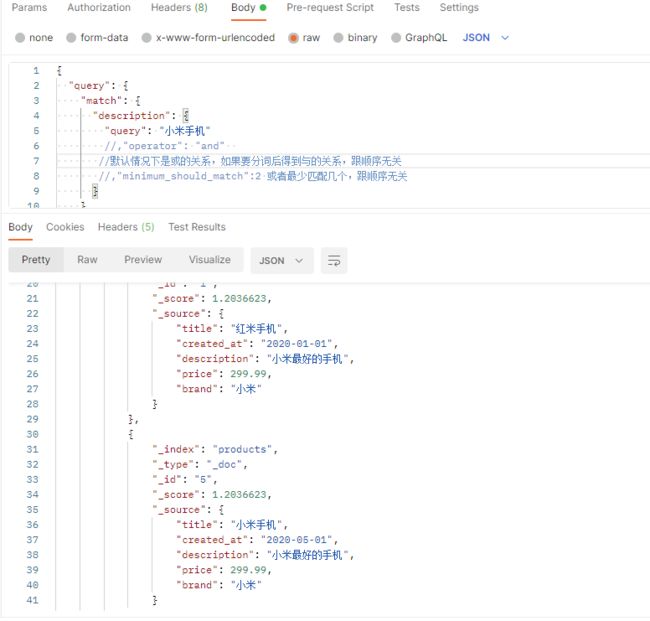
match 默认是或的关系,分词后包含一个词就可以,如果要得到“与”的关系,增加条件:operator为and
或者可以采用minimum_should_match来表明至少有2个是匹配的才可以
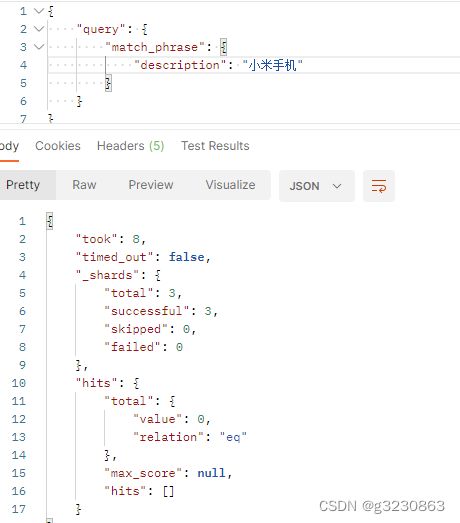
match_phrase短语查询,
会对输入做分词,但是需要原子句中包含搜索词所有的分词term。以"小米手机"为例,要求子句中必须包含小米和手机两个词,而且还要求他们是连着的,顺序也是固定的。
所以下面没有查到
经过对子句进行分词,小米在pos[0],手机在pos[2],他们之间还差一个位置。
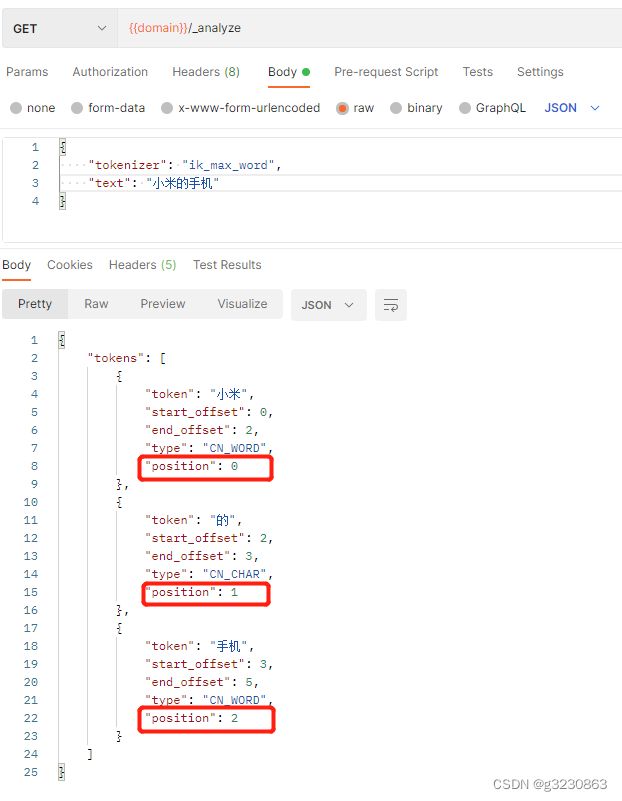
但如果加上slop参数:要经过几次移动才能让“小米”与“手机”连在一起。
小米与手机之前间隔了1个词,所以当slop>=1就能查到
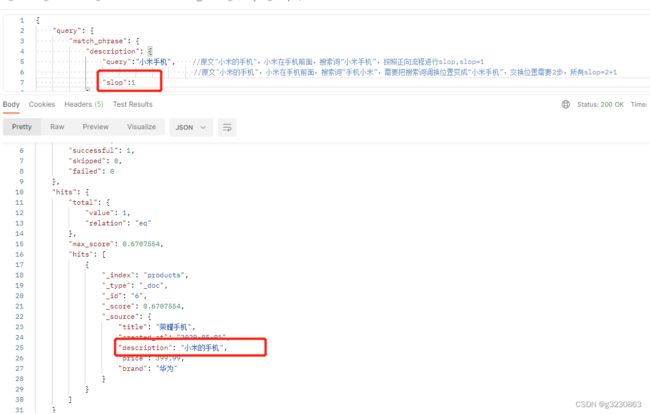
如果搜索“手机小米”,就查不到了,首先,手机和小米这两个词都在原句中,但他们的位置不满足,原句中“小米的手机”分词后,“小米”在“手机”的前面,如果要进行slop匹配,ES需要对“手机小米”交换位置。
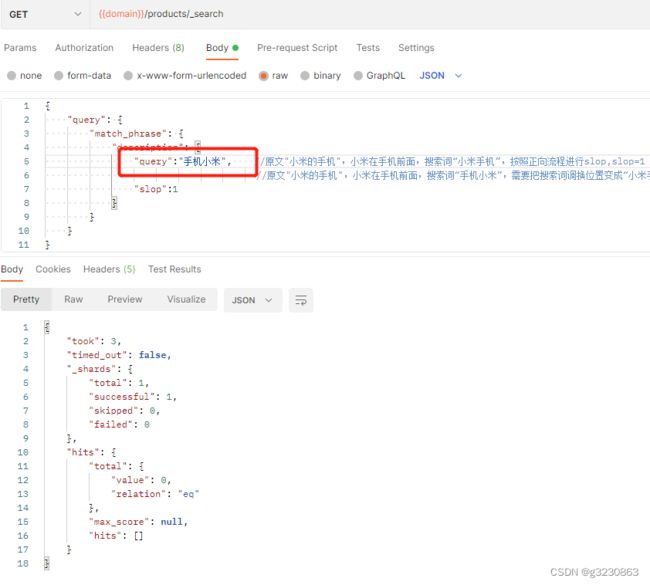
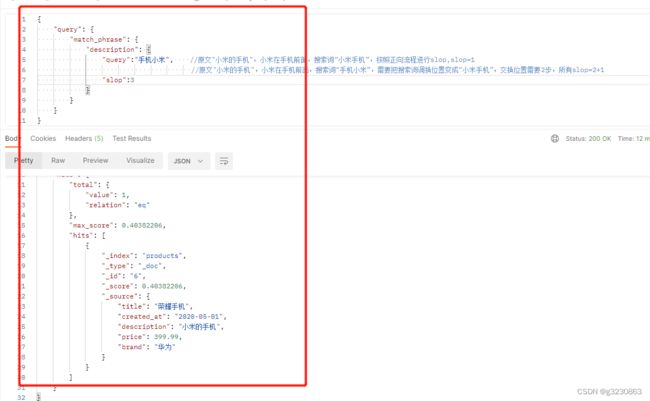
ES需要对“手机小米”交换位置。需要进行2歩
交换后,搜索词进变成了"小米手机",在按照正向流程进行比较。slop=2(交换的歩数)+1(正向移动步数)
fuzzy模糊查询
fuzzy 模糊查询,最大模糊错误,必须现在0-2之间
1.搜索关键词长度为2,不允许存在模糊
2.搜索关键词长度为3-5,允许一次模糊
3.搜索关键词长度大于5,允许最大2次模糊
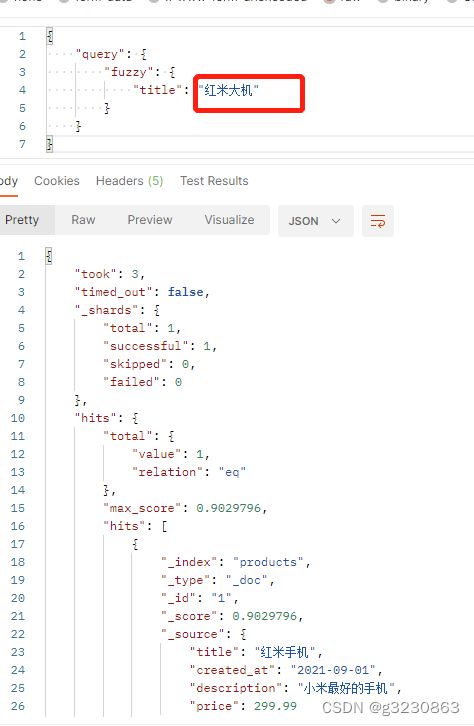
在默认的分词下,以中文为例,tile为红米手机,长度为4,所以只允许一次模糊

只有中间的“大”一个字不同,所以能查出来
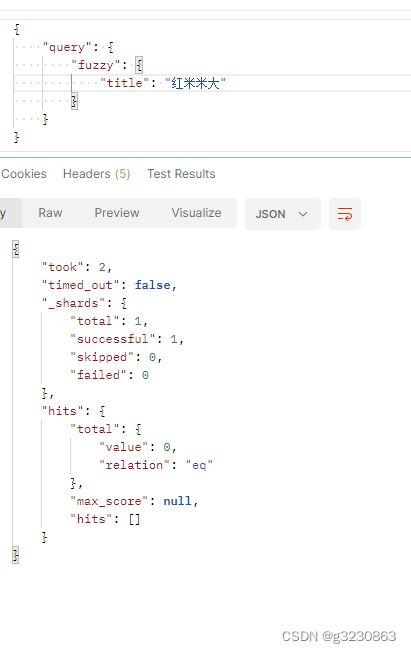
如果有2个字不同就搜索不出来了
多字段查询multi_match

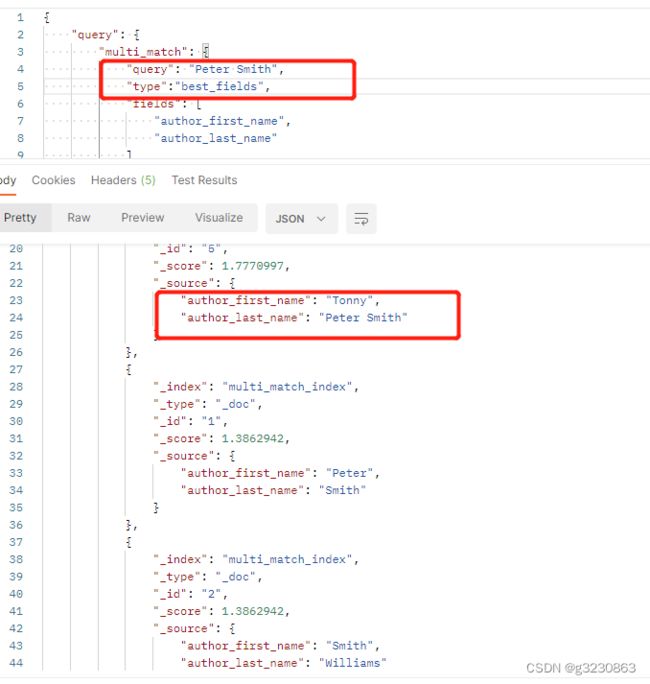
1.best_fields
默认情况下type=best_fields,计算分数:取最大子句的分数为最终得分。
sum(last_name)>sum(first_name)。最终就是sum(last_name)
2.most_fields
当type=most_fields,计算分数:取每个子句的分数总和为最终得分。
最终就是sum(last_name)+sum(first_name)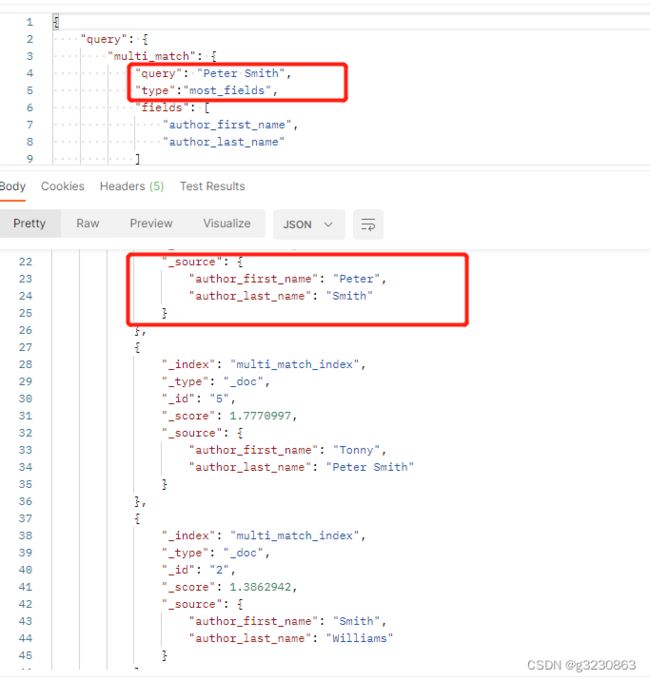
2.cross_fields
为了更精确的搜索,让每个字句都包含peter smith。 best_fields 和most_fields都会加上operator and minimum_should_match。
但理想情况下,搜索名字的时候,是一个对应字段包括peter,另一个字段包括Smith。两个字段组成姓名。
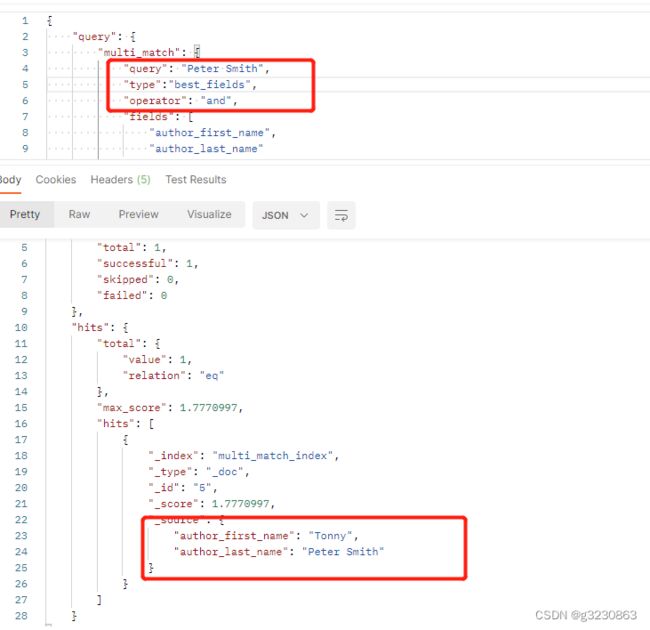
使用cross_fields后,就能达到这个效果
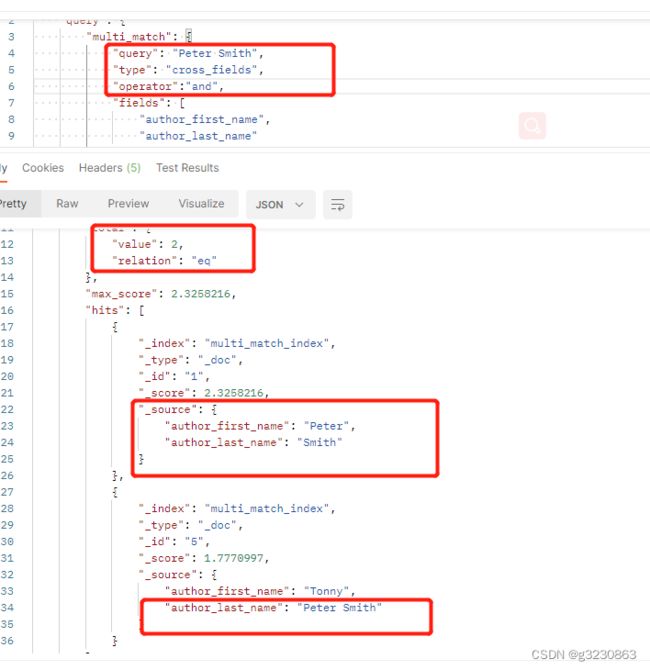
第二个问题:
例如,假设我们有两个人:“Peter Smith”和“Smith Jones”。“史密斯”作为姓氏是很常见的(因此重要性很低),但“史密斯”作为名字却很少见(因此非常重要)。
如果我们搜索“Peter Smith”,“Smith Jones”文档可能会出现在更匹配的“Peter Smith”上面,因为first_name: Smith的得分超过了first_name: Peter 加last_name: Smith的得分之和
所有字段分词查询(query_string)
在所有的字段中按照分词规则来查询。可以指定在哪个字段查询default_field等
https://www.cnblogs.com/ddcoder/articles/7457082.html
下图是按照默认分词器,中文一个个汉字分词
插入3条数据
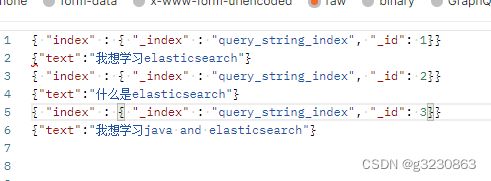
默认default_operator 为or,要text里边包含 我, 想 , 学习, elasticseach , 其中一个就会查询出来;会把3条数据全查出来,
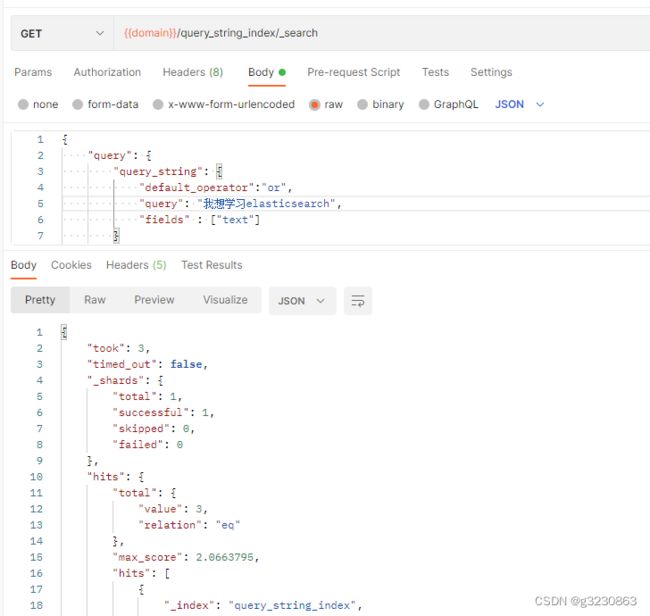
同理当 default_operator值为 and 时,里边必须同时包含 我, 想 , 学习, elasticseach , 才会查询出来

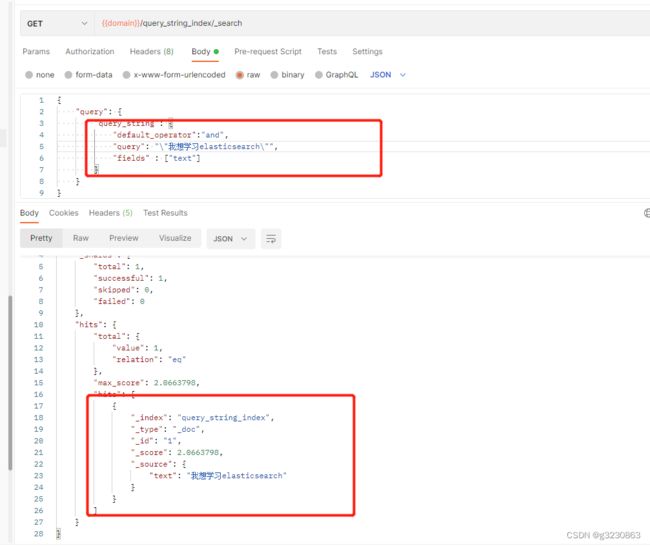
我想学习elasticsearch 生成的短语为 我想学习elasticsearch;
加双引号或者auto_generate_phrase_queries=true
里边必须按顺序包含 我, 想 , 学习, elasticseach 才会查询出来 即ID 为 1 ;
https://segmentfault.com/a/1190000023245098?sort=votes
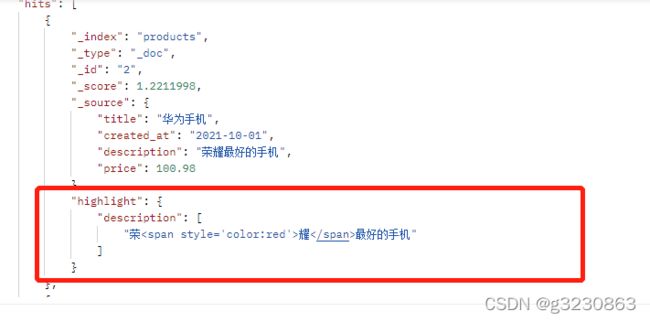
高亮查询
fields:* 代表所有能分词字段高亮
pre_tags:给高亮的词加上想要的css样式
require_field_match:false ,让满足的全部字段高亮
{
"query": {
"query_string": {
"query":"红耀米",
"default_field": "description"
}
},
"highlight": {
"pre_tags":[""],
"post_tags":[""],
"require_field_match":"false",
"fields": {
"*": {}
}
}
}
filter查询
在执行filter和query时,先执行filter在执行query
filter:能快速的查询复合条件的,不进行得分和排序
query:会进行得分和排序

filter 必须与bool一起使用, 常用的有term,terms,range,exists,ids等filter
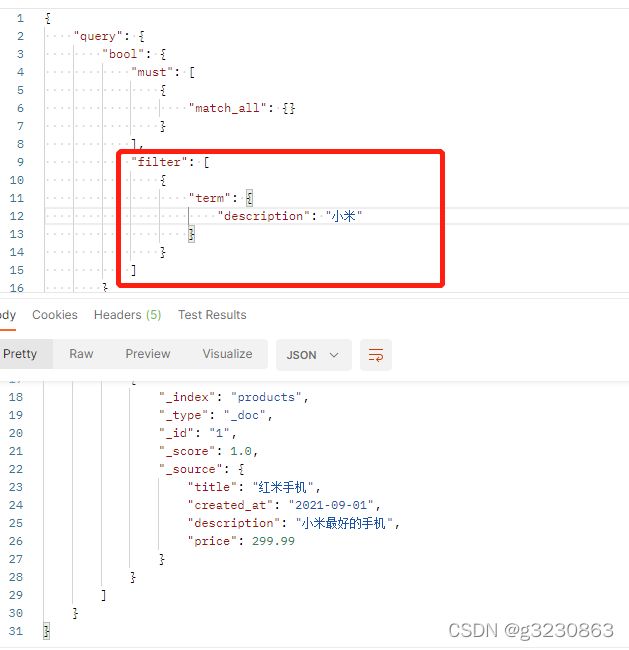
ES并发
加上 “version”: true 查询能获取数据的版本。
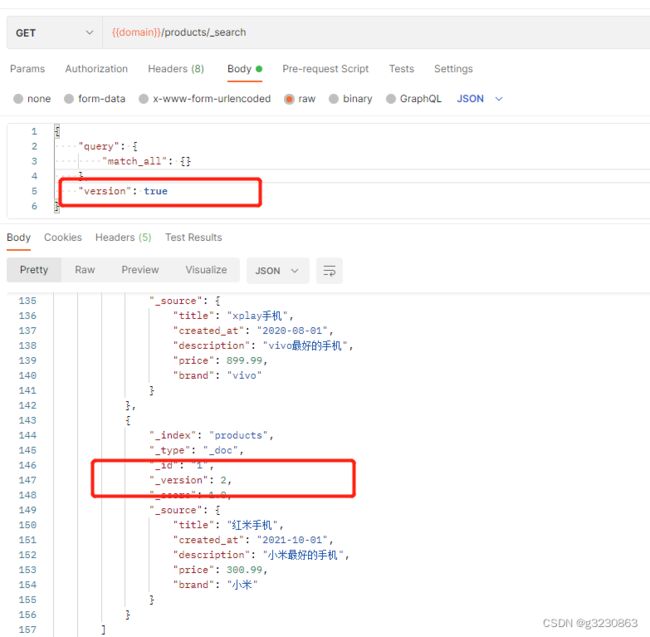
更新数据的时候,_version和_seq_no会更新
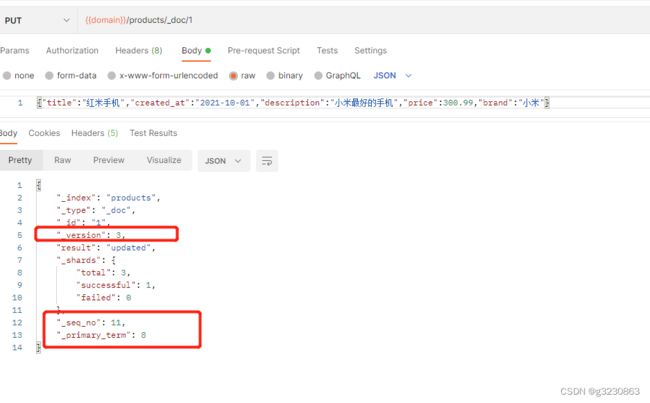
_seq_no:文档版本号,作用同_version。
_primary_term:文档所在位置。
实现数据版本有两种方式,第一种是使用版本号,第二种是使用时间戳。
结合业务,我使用了时间戳这种方式;
增加timestamp
{
"properties": {
"timestamp": {
"type": "long"
}
}
}
使用MaxWell来监听表的变化,通过Kafka把表变化发送出来,消费者监听,使用binlog变更的时间做时间戳timestamp。在删除和更新的时候,把时间戳带入,我下面的为了防止先删除然后插入的并发。(监听插入逻辑先执行完,然后删除逻辑把刚插入的新数据删除了)
RangeQueryBuilder range = QueryBuilders.rangeQuery("timestamp");
range.lte(timestamp);
boolQueryBuilder.filter(range);
其他的相关参考:
https://blog.csdn.net/weixin_41860630/article/details/126490353