我正在参与掘金创作者训练营第4期,点击了解活动详情,一起学习吧!
咱们接着上一部分来进行分享,我们可以在如下地址下载 redis 的源码:

此处我下载的是 redis-6.2.5 版本的,xdm 可以直接下载上图中的 redis-6.2.6 版本,
redis 中 hash 表的数据结构
redis hash 表的数据结构定义在:
redis-6.2.5\src\dict.h
哈希表的结构,每一个字典都有两个实现从旧表到新表的增量重哈希
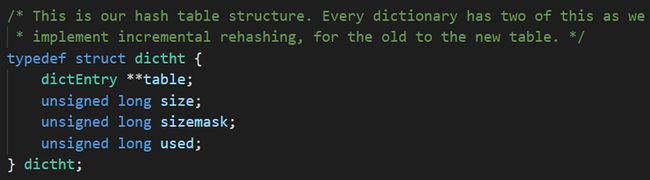
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;table:
table 是一个二级指针,对应这一个数组,数组中的每个元素都是指向了一个 dictEntry 结构体指针的,dictEntry 具体的数据结构是保存一个键值对
具体的 dictEntry 数据结构是这样的:
size:
size 属性是记录了整个 hash 表的大小,也可以理解为上述 table 数组的大小
sizemask:
sizemask 属性,和具体的 hash 值来一起决定键要放在 table 数组的哪个位置
sizemask 的值,总是会比 size 小 1 ,我们可以来演示一下
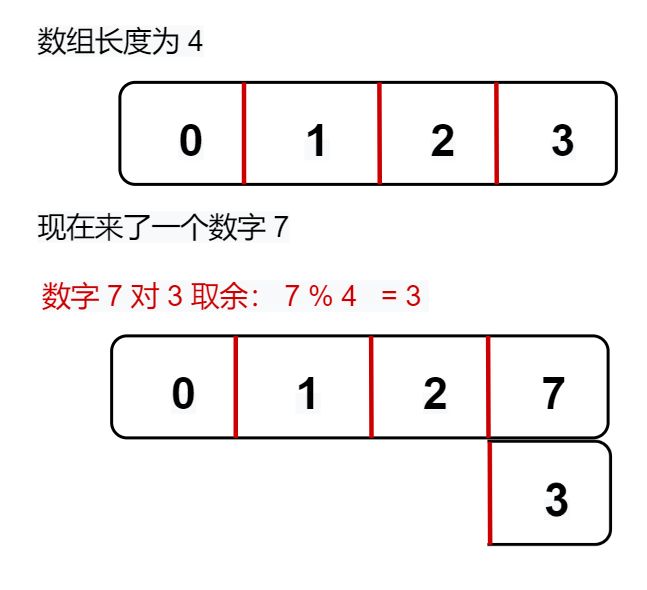
使用取余的方式,实际上是很低效的,咱们的计算机是不会做乘除法的,同样都是用加减法来进行处理的,为了高效处理,我们可以使用二进制的方式
使用二进制的方式,就会用到该字段 sizemask ,主要是用来 和 具体的 hash 值做按位与操作

如图就很明确了, size = 4,sizemask = 3,hash 值为 7, 最后 hash 值 & sizemask = 0011, 也就是 3,因此就会插入到上图的具体位置
used:
used 属性表示 hash 表里面已经有键值对的数量
对于上述的案例,可以用一个简图来表示一下 hash 表结构 dictht

dictEntry 结构每个属性的含义
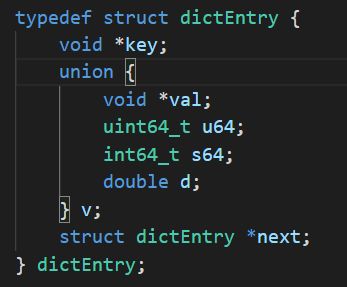
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;上面我们看到数组中的节点信息,是 dictEntry 结构,属性分别是这些意思:
key
具体的 redis 键
union v
val
指向不同类型的数据,此处是 void * ,使用该类型,是为了节省内存
u64
用于 redis 集群中的哨兵模式和选举模式
s64
记录过期时间的
next
指向下一个节点的指针
dict 结构
在 src\dict.h 文件中,咱们接着往下看,能够看到一个非常关键的结构,就是 dict ,redis 中都是使用这个结构来进行组织的

typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
} dict;- type
字段对应的操作函数,具体有哪些操作函数,我们可以看到typedef struct dictType 给出的信息
- privdata
字典依赖的数据,例如 redis 具体的操作等等
- ht[2]
hash 表的键值对,放在此处,一个旧的,一个新的
ht[0] :是扩容前的数组
ht[1]:是扩容后的数组
这个是当数据量大的时候,用于渐进式 rehash 的
- rehashidx
来指定具体 rehash 的位置,对应到 ht[0] 的索引上,rehashidx == -1 ,就是没有进行再 hash , rehashidx != -1 时,说明正在进行再 hash
还记得我们之前说到 redis 有 16 个 db 吗?
我们在 redis 源码中 src\server.h 也能够看到 redisdb 的数据结构

我们可以看到 dict 这个字典,是 redis 中使用是相当频繁和关键的
上面有说到 ht[2] 会用在渐进式 rehash 上,那么为什么要用渐进式 rehash 以及他是如何做的?
扩容的时候,会触发 rehash
当数据量很大的时候,会涉及到扩容,若一次性从 ht[0] 拷贝到 ht[1] 是比较慢的,会阻塞其他操作,那么就没有办法处理其他请求了,因为 redis 是单线程处理任务的
ht[0] 数据拷贝到 ht[1] 的方式一
是这样进行 rehash 的 :
扩容的时候,rehash 是这样做的:
- 先会对上述说到的 ht[1] 开辟内存空间,会将 ht[0].size * 2 给到 ht[1]
- 然后再将 ht[0] 的数据,从
ht[0][0] ... ht[0][size-1]将数据拷贝到 ht[1] 里面
如何做到渐进式呢?
使用分而治之的思想,无论 redis 目前是否在做持久化的时候,当我们每次操作 redis 增删改查,就会进行边枚举边筛查的方式,逐步的将 ht[0][0] ... ht[0][size-1] rehash 到 ht[1] 中
可以追一下代码流程 , 我们从 src\server.c 注册 setCommand 命令开始追起,代码设计关键流程如下
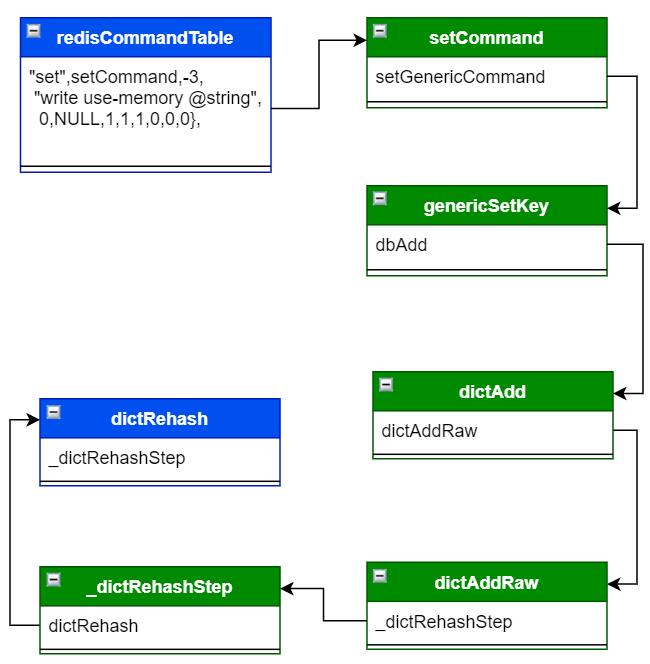


当追到 dictAddRaw 函数的时候,我们可以清晰的看出来,当 redis 加入数据的时候,使用的是头插法
- 先对新的节点开辟相应的内存
- 将新建节点的 next 对象指向链表的头
- 然后将链表的头指向新建的节点地址,即完成了一次 头插

此处我们可以看到,实际上是做了一次 rehash

追到 dictRehash 函数的时候,可以看到此处的再 hash 函数 dictRehash,我们可以看到 rehash 的做法是:
- 在 ht[0] 数组中,取得 rehashidx 对应的桶,或者脚数组对应的索引位置
- 通过上述找到的索引位置,取 ht[0].table[d->rehashidx] 对应的链表
- 然后将链表中的数据依次进行 rehash
此处 dictRehash 的 n 的参数,表示再 hash 的次数,再 hash 1 次,表示对于数组的这个桶对应的链表上的所有数据,进行一轮 hash
可以看到代码中
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;此处正是 dictHashKey 计算出一个整数,然后和我们 dictht 中的 sizemask 进行一次按位与操作 , 旨在得到一个新的 hash 表索引位置
redis 调用 _dictRehashStep 的位置
通过查看代码中调用 _dictRehashStep 函数的位置并不多,我们一次查看调用关系,我们会知道确实是当我们每次操作 redis 增删改查的时候,会发生渐进式的 rehash , 这些是在我们进行扩容之后,如何将 ht[0] 的数据拷贝到 ht[1] 的实现方式
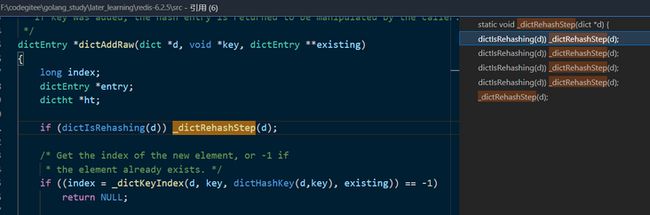


实际 redis 中涉及到如上几个函数 都会调用 _dictRehashStep:
- dictAddRaw
- dictGenericDelete
- dictFind
- dictGetRandomKey
- dictGetSomeKeys
ht[0] 数据拷贝到 ht[1] 的方式二
定时器调用 dictRehash的逻辑
当 redis 中没有持久化操作的时候,redis 中的定时操作就会就会走定时的逻辑,逻辑是这样的
我们可以在 redis 源码中搜索使用 dictRehash 函数的位置
使用的位置也并不多,我们很容易就能找到按照毫秒级别来定时操作的位置
dictRehashMilliseconds

此处的逻辑是,while 循环是以 100 次 rehash 为一轮,时间限制是 1ms,只要时间不超过 1ms,能做的 rehash 次数至少是 100 次(每一轮 100 次),若超过 1 ms,则会立刻结束本次定时操作
此处我们可以看到,dictRehash(d,100) 传递的参数是 100,表示 rehash 100 次,还记得之前的渐进式 rehash 是 传入的 1 次 吗,可以往上看看文章内容
今天就到这里,学习所得,若有偏差,还请斧正
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力

好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~