【小工具】对比DB库中所有表字段的差异,导出csv文件
对比DB库中所有表差异,导出csv文件
-
-
- 最终成品如下
-
- 废话不多说,直接上代码
平时工作中会要求对比不同环境下的DB库中所有表的差异,包含字段差异、字段类型、字段注释、字段默认值等,网上查了很多资料发现并不能很好的满足我的要求,最终搞了一下把这些差异生成CSV文件
最终成品如下
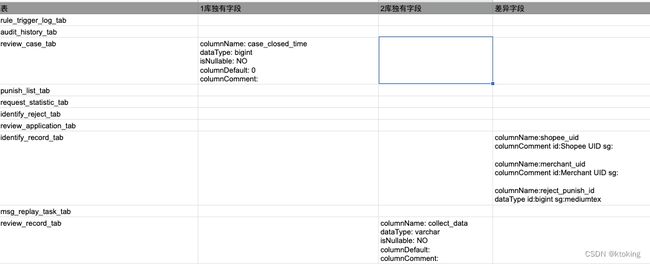
废话不多说,直接上代码
package com.xx.xx.xx.utility;
import cn.hutool.core.collection.CollUtil;
import cn.hutool.poi.excel.ExcelUtil;
import cn.hutool.poi.excel.ExcelWriter;
import cn.hutool.poi.excel.StyleSet;
import com.alibaba.druid.pool.DruidDataSource;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.collections4.CollectionUtils;
import org.apache.commons.collections4.MapUtils;
import org.apache.commons.io.FileUtils;
import org.apache.poi.ss.usermodel.CellStyle;
import org.apache.poi.ss.usermodel.HorizontalAlignment;
import org.springframework.jdbc.core.JdbcTemplate;
import java.io.File;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.*;
import java.util.stream.Collectors;
public class DBDiffUtil {
static final String Å="xxx";
static final String SGDBName="xxxx";
static final String SIT1 = "jdbc:mysql://xxxx:xx/"+IDDBName+"?useSSL=false";
static final String SIT3 = "jdbc:mysql://xxx:xx/"+SGDBName+"?useSSL=false";
static final String tableSql =
"SELECT TABLE_SCHEMA,TABLE_NAME, " +
" TABLE_COMMENT FROM " +
" information_schema.`TABLES` " +
"WHERE " +
" TABLE_SCHEMA = '%s'";
static final String schemaSQL = "SELECT " +
"COLUMN_NAME,DATA_TYPE,IS_NULLABLE,COLUMN_DEFAULT ,COLUMN_COMMENT " +
"FROM INFORMATION_SCHEMA.COLUMNS " +
"where table_schema = '%s' AND table_name = '%s'";
private static JdbcTemplate db1;
private static JdbcTemplate db2;
static {
db1 = new JdbcTemplate();
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(SIT1);
dataSource.setUsername("xxx");
dataSource.setPassword("xxx");
db1.setDataSource(dataSource);
db2 = new JdbcTemplate();
DruidDataSource dataSource2 = new DruidDataSource();
dataSource2.setUrl(SIT3);
dataSource2.setUsername("xxx");
dataSource2.setPassword("xxx");
db2.setDataSource(dataSource2);
}
public static void main(String[] args) throws IOException {
Set<String> idTables = db1.queryForList(String.format(tableSql, IDDBName)).stream().map(e -> e.get("TABLE_NAME").toString()).collect(Collectors.toSet());
Set<String> sgTables = db2.queryForList(String.format(tableSql, SGDBName)).stream().map(e -> e.get("TABLE_NAME").toString()).collect(Collectors.toSet());
Collection<String> intersection = CollectionUtils.intersection(idTables, sgTables);
Collection<String> idUniques = CollectionUtils.subtract(idTables, sgTables);
Collection<String> sgUniques = CollectionUtils.subtract(sgTables, idTables);
Map<String, Map<String, TableSchema>> idTableObjs = getForList(intersection, IDDBName,db1);
Map<String, Map<String, TableSchema>> sgTableObjs = getForList(intersection, SGDBName,db2);
// key 表名 value 对比字段
List<List<String>> res = compareTables(idTableObjs, sgTableObjs);
String[] headers = {"表","1库独有字段", "2库独有字段", "差异字段"};
List<String> row = CollUtil.newArrayList(headers);
ExcelWriter writer = ExcelUtil.getWriter("/Users/xxx/Desktop/dbDiff.csv");
StyleSet style = writer.getStyleSet();
CellStyle cellStyle = style.getHeadCellStyle();
cellStyle.setAlignment(HorizontalAlignment.LEFT);
Map<String, Map<String, TableSchema>> idUniqueTables = getForList(idUniques, IDDBName, db1);
Map<String, Map<String, TableSchema>> sgUniqueTables = getForList(sgUniques, SGDBName, db2);
List<List<String>> b1 = getBlankTableInfo(idUniqueTables, Boolean.TRUE);
List<List<String>> b2 = getBlankTableInfo(sgUniqueTables, Boolean.FALSE);
Collection<List<String>> coll = new ArrayList();
coll.add(row);
coll.addAll(res);
coll.addAll(b1);
coll.addAll(b2);
writer.write(coll);
writer.flush();
System.out.println(1);
}
public static List<List<String>>compareTables(Map<String, Map<String, TableSchema>> source,Map<String, Map<String, TableSchema>> target){
List<List<String>> res=new ArrayList<>();
// 遍历所有表对比
for (Map.Entry<String, Map<String, TableSchema>> entry : source.entrySet()) {
Map<String, TableSchema> sourceTable = entry.getValue();
Map<String, TableSchema> targetTable = target.get(entry.getKey());
// 对于每张表对比
Collection<String> sameFields= CollectionUtils.intersection(Optional.of(sourceTable.keySet()).orElse(new HashSet<>()), Optional.of(targetTable.keySet()).orElse(new HashSet<>()));
Collection<String> sourceUniqueFields = CollectionUtils.subtract(Optional.of(sourceTable.keySet()).orElse(new HashSet<>()), Optional.of(targetTable.keySet()).orElse(new HashSet<>()));
Collection<String> targetUniqueFields = CollectionUtils.subtract(Optional.of(targetTable.keySet()).orElse(new HashSet<>()), Optional.of(sourceTable.keySet()).orElse(new HashSet<>()));
StringBuilder diffSchemas=new StringBuilder();
for (String sameKey : sameFields) {
TableSchema schema1 = sourceTable.get(sameKey);
TableSchema schema2 = targetTable.get(sameKey);
String compare = schema1.compare(schema2);
diffSchemas.append(compare);
}
StringBuilder sourceSchemas=new StringBuilder();
for (String sourceUniqueField : sourceUniqueFields) {
sourceSchemas.append(sourceTable.get(sourceUniqueField).getWithInfo());
}
StringBuilder targetSchemas=new StringBuilder();
for (String targetUniqueField: targetUniqueFields) {
targetSchemas.append(targetTable.get(targetUniqueField).getWithInfo());
}
List<String> row=new ArrayList<>();
row.add(entry.getKey());
row.add(sourceSchemas.toString());
row.add(targetSchemas.toString());
row.add(diffSchemas.toString());
res.add(row);
}
return res;
}
public static List<List<String>> getBlankTableInfo(Map<String, Map<String, TableSchema>> source,Boolean isSource){
List<List<String>> res=new ArrayList<>();
for (Map.Entry<String, Map<String, TableSchema>> entry : source.entrySet()) {
// 拿到一张表的所有字段
Map<String, TableSchema> value = entry.getValue();
// 遍历字段拼接
List<String> row=new ArrayList<>();
StringBuilder schemas=new StringBuilder();
for (Map.Entry<String, TableSchema> field : value.entrySet()) {
schemas.append(field.getValue().getWithInfo());
}
row.add(entry.getKey());
if(isSource){
row.add(schemas.toString());
row.add("无");
}else{
row.add("无");
row.add(schemas.toString());
}
row.add("");
res.add(row);
}
return res;
}
public static Map<String,Map<String,TableSchema>> getForList(Collection<String> collection,String dBName,JdbcTemplate db){
if(CollectionUtils.isEmpty(collection)) return new HashMap<>();
Map<String,Map<String,TableSchema>> tables=new HashMap<>();
for (String table : collection) {
Map<String, TableSchema> tableMap = db.queryForList(String.format(schemaSQL, dBName, table)).stream().map(e -> {
try {
return TableSchema.builder()
.columnName(Optional.ofNullable(e.get("COLUMN_NAME")).orElse("").toString().trim())
.dataType(Optional.ofNullable(new String((byte[])e.get("DATA_TYPE"),"UTF-8")).orElse("").trim())
.isNullable(Optional.ofNullable(e.get("IS_NULLABLE")).orElse("").toString().trim())
.columnDefault(Optional.ofNullable(e.get("COLUMN_DEFAULT")).orElse("").toString().trim())
.columnComment(Optional.ofNullable(e.get("COLUMN_COMMENT")).orElse("").toString().trim()).build();
} catch (UnsupportedEncodingException ex) {
throw new RuntimeException(ex);
}
}).collect(Collectors.toMap(TableSchema::getColumnName, o -> o));
tables.put(table,tableMap);
}
return tables;
}
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
static class TableSchema {
String columnName;
String dataType;
String isNullable;
String columnDefault;
String columnComment;
public String compare(TableSchema compare) {
StringBuilder sb=new StringBuilder("columnName:").append(compare.columnName).append("\n");
Boolean flag=false;
if(!this.dataType.equals(compare.getDataType())){
sb.append("dataType ").append("id:").append(this.dataType).append(" ").append("sg:").append(compare.dataType).append("\n");
flag=true;
}
if(!this.isNullable.equals(compare.getIsNullable())){
sb.append("isNullable ").append("id:").append(this.isNullable).append(" ").append("sg:").append(compare.isNullable).append("\n");
flag=true;
}
if(!this.columnDefault.equals(compare.getColumnDefault())){
sb.append("columnDefault ").append("id:").append(this.columnDefault).append(" ").append("sg:").append(compare.columnDefault).append("\n");
flag=true;
}
if(!this.columnComment.equals(compare.getColumnComment())){
sb.append("columnComment ").append("id:").append(this.columnComment).append(" ").append("sg:").append(compare.columnComment).append("\n");
flag=true;
}
if(flag){
return sb.append("\n").toString();
}
return "";
}
public String getWithInfo() {
StringBuilder sb=new StringBuilder();
sb.append("columnName: ").append(this.columnName).append("\n");
sb.append("dataType: ").append(this.dataType).append("\n");
sb.append("isNullable: ").append(this.isNullable).append("\n");
sb.append("columnDefault: ").append(this.columnDefault).append("\n");
sb.append("columnComment: ").append(this.columnComment).append("\n");
return sb.append("\n").toString();
}
}
}
db差异文件会将相同的字段对比差异 然后罗列出来 比对dataType、isNullable、columnDefault、columnComment 然后利用hutool 工具类导出CSV文件即可,代码会将给定库内所有表进行比较,代码有点啰嗦请大佬们轻喷~