究竟什么是位图
引言
为什么要写这篇博文呢,是因为之前面试的时候遇到这样一个问题:
有一款数十亿级别的用户产品,如何统计一周内连续活跃的用户数?
这个问题的特征其实很明显:数据量大,需要交并操作,而且还有一定的性能要求。当时想到了 BitMap 、布隆过滤器这些方法,但是由于理解的不够深入答案自然就漏洞百出。
在实际工作中发现,这类的问题的确是业务中需要解决的问题,并不是面试官为了刁难候选人奇思妙想出来的。
所以经过系统的学习后在此记录一番。
基础知识
在计算机系统中数据储存单位的转换关系是非常基础的内容,譬如:
另外在一些主流的编程语言中,int 类型的数据占用的存储空间通常和操作系统的位数相关:
- 在 32 位的操作系统中,int 类型的数据占 32 bit,可以表示
 个数字,约43亿个。
个数字,约43亿个。 - 在 64 位的操作系统中,int 类型的数据占 64 bit,可以表示
 个数字。
个数字。
![]()
什么是位图
在维基百科上位图的解释是一种使用像素数组来表示的图像。
不过这篇博文记录的不是图像,而是一种数据结构,可以简单理解为位数组。位就是计算机中存储的二进制数据位——比特 (bit),位数组是由多个bit组成的数据结构。
至于为什么叫 BitMap 而不是 BitArray,我理解这是和它的使用方式有关系的。
位图的优势
减少内存占用
回到面试官的问题中,假设我们有两个方案来记录用户是否活跃:
- 传统的 map 结构,map-key 使用 int32 类型记录用户的唯一标识,map-value 使用 bool 类型记录用户的活跃状态。
- 位图,使用位图的槽位表示用户的唯一标识,使用槽位对应的二进制 0/1 表示用户的活跃状态。
接下来我们比较这2个方案的内存消耗:(为了方便计算我们假定有10亿个用户)
- 在方案1中,需要 10亿个 int32 类型的数字记录用户的唯一标识,也就是
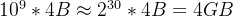 的存储空间,这么大的数据肯定是无法在内存中计算的。
的存储空间,这么大的数据肯定是无法在内存中计算的。 - 而在方案2中,只需要长度为10亿的 bit 数组,约占用
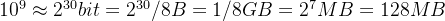 的存储空间。
的存储空间。
通过比较位图可以极大的降低数据占用的存储空间,使得相关的运算在内存中就可以进行。
排序和去重
再回到面试官的问题中,假定用户的唯一标识越小表示用户注册的时间越早,现在需要按照注册时间给活跃用户进行排序然后输出去重的结果。
为了方便讨论问题我们假设只需要给唯一标识分别为 28、17、9、28、100 的这组数据进行去重和排序。
- 首先我们初始化一个长度为101的位图,并且设置每一位的值为 0。
- 遍历数据,标记唯一标识对应槽位的值为 1。
- 从槽位 0 开始遍历位图,输出值为 1 所在的槽位序列,该序列就是经过去重和排序后的活跃用户的列表。

集合运算
再假定产品中有两个功能分别为 P1 和 P2,现在需要计算这两个功能都喜欢的用户有多少。
同样为了方便讨论问题我们假定喜欢功能 P1 的用户为 1、2、9、10、30;喜欢功能 P2 的用户为 0、2、10、29、100。
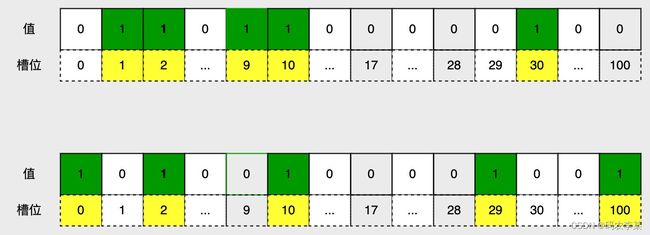
从图中我们很明显可以看出来同时喜欢两个功能的用户是 2、10,但是我们通过什么手段可以快速计算得到结果呢?
不难发现两个位图对应的二进制值分别是
- 0110 1100 0001 00
- 1010 0100 0010 01
对它们进行 & 操作后可得到二进制值 0010 0100 0000 00,其结果中值为 1 的槽位就是2和10,也就是我们需要的结果。
Golang实现
在 Golang 中 uint32 类型占用4字节,也就是32个bit,我们使用 uint32 类型的切片存储数据。在 Value[0] 中表示 0 ~31;Value[1] 中表示 32 ~ 63......
在实现过程中需要解决的核心问题就是如何找到数组在位图中的具体槽位.
- 首先数字整除32,得到的结果就是 Value 的下标,即数字所处在 Value 切片的某段中。
- 然后数字取模32,得到的结果就是 某一段中具体的位置。
譬如对于数字 36 整除 32 后得到 1,即数字 10 在 Value 切片的第 1 段 32~63 中;然后再取模 32 得到 4,即数字 36 对应的槽位是 Value[1] 中的第 5 个位置。注意下标是从0开始的。
具体实现如下:
package bitmap
// 定义数据结构
type BitMap struct {
Value []uint32
length int
}
// Add: 添加一个数字, 如果待添加数字已存在则返回fasle,否则返回true
func (bitmap *BitMap) Add(num uint32) bool {
if bitmap.IsExist(num) {
return false
}
// 计算数字所在的槽位地址
var bucketIndex = num / 32
var bitIndex = num % 32
if int(bucketIndex) >= len(bitmap.Value) {
bitmap.Value = append(bitmap.Value, 0)
}
// 设置 bitIndex 槽位的值为1
remainder := 1 << bitIndex
bitmap.Value[bucketIndex] |= uint32(remainder)
bitmap.length++
return true
}
// Remove: 删除一个数字,如果待删除的数字不存在则返回false,否则返回true
func (bitmap *BitMap) Remove(num uint32) bool {
if !bitmap.IsExist(num) {
return false
}
var bucketIndex = num / 32
var bitIndex = num % 32
// 这里使用 -= 运算也可以
bitmap.Value[bucketIndex] ^= 1 << bitIndex
bitmap.length--
return true
}
// Values: 获取添加过的数字,从小到大排列
func (bitmap *BitMap) Values() []uint32 {
arr := make([]uint32, 0, bitmap.length)
for index, val := range bitmap.Value {
if val == 0 {
continue
}
for j := uint(0); j < 32; j++ {
if val&(1<位图的缺点
由于位图是用槽位来表示具体的元素值,那天然的在表示稀疏数据的时候是不占优势的,因为位图中会有极大部分的空间是被浪费的。
目前使用压缩手段来解决空间浪费的问题。
RLE 编码 —— Run-Length Encoding
这是一种编码压缩的思想,其核心观点是把连续重复出现的值使用 值+出现次数 的方式表示,从而达到数据压缩的目的。譬如 101 0*20 11 表示该序列的值为 二进制串 101 和 11 中间有20个0,这里只是举个例子说明下这种思想。具体的实现该思想的算法在网上有很多资料可以作为扩展阅读,此处不做深入记录。
这种编码方式局限性比较明显,比如每次读写数据的时候都需要先对数据进行解压才能操作;另外不能进行位运算。
Roaring BitMap
这是一种高效的压缩算法,基本上很好的解决了 RLE 编码中存在的问题,目前使用也十分的广泛。
其核心的思想是把 32位数据分成  个桶,使用数据的高16位作为桶的编号,每个桶存放一个 Container 存放数据的低16位数据。
个桶,使用数据的高16位作为桶的编号,每个桶存放一个 Container 存放数据的低16位数据。
一共有3种Containter,分别为 Array Container、BitMap Container、Run Container,其中 Run 指 RLE。其中 Array Container 用来存放稀疏数据,BitMap Container 用来存储稠密数据,Run Container 使用场景比较少。
具体得,当一个 Container 中的元素小于 4096 时使用 Array Container 存储,否则会使用 BitMap Container 存储。
读写性能方面:
- BitMap Container 由于只涉及到位运算且可以根据下标直接寻址,所以时间复杂度为 O(1)。
- Array Container 都需要通过二分查找才能确定元素的位置,所以时间复杂度为 O(logN)。
在空间占用上,BitMap Container 只占用 8KB,而 Array Container 和基数有关。
基础组件应用
-
Redis 中提供了 SETBIT、GETBIT、BITCOUNT、BITTOP 四个常用命令来处理二进制位数组。
-
ES 中优化 Filter 查询,由于 Filter 查询不涉及评分操作,只处理文档是否匹配查询条件,所以查询可以被缓存。Lucene 采用的就是 Roaring BitMap。
-
ClickHouse 中有 bloom_filter 类型的 skipping indexs 用来过滤数据。
扩展阅读
从ClickHouse到ByteHouse:广告业务中的人群预估实践-火山引擎
广告案例|10亿数据、查询<10s,论基于OLAP搭建广告系统的正确姿势 - 掘金