PySpark 之 flatMap
1. pyspark 版本
2.3.0版本
2. 官网
flatMap(f, preservesPartitioning=False)[source]
Return a new RDD by first applying a function to all elements of this RDD, and then flattening the results.
中文翻译: 首先向该RDD的所有元素应用函数,然后将结果展平,以返回新的RDD。
>>> rdd = sc.parallelize([2, 3, 4])
>>> sorted(rdd.flatMap(lambda x: range(1, x)).collect())
[1, 1, 1, 2, 2, 3]
>>> sorted(rdd.flatMap(lambda x: [(x, x), (x, x)]).collect())
[(2, 2), (2, 2), (3, 3), (3, 3), (4, 4), (4, 4)]3. 我的代码
案列1
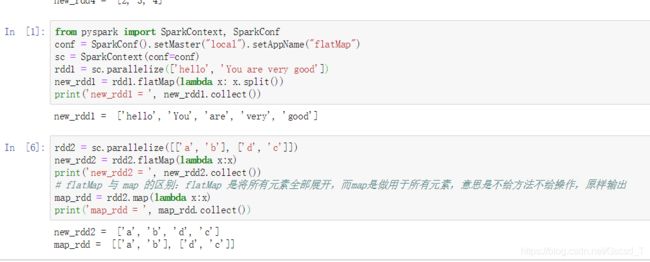
from pyspark import SparkContext, SparkConf
conf = SparkConf().setMaster("local").setAppName("flatMap")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize(['hello', 'You are very good'])
new_rdd1 = rdd1.flatMap(lambda x: x.split())
print('new_rdd1 = ', new_rdd1.collect())
>>> new_rdd1 = ['hello', 'You', 'are', 'very', 'good']案列2
rdd2 = sc.parallelize([['a', 'b'], ['d', 'c']])
new_rdd2 = rdd2.flatMap(lambda x:x)
print('new_rdd2 = ', new_rdd2.collect())
# flatMap 与 map 的区别:flatMap 是将所有元素全部展开,而map是做用于所有元素,意思是不给方法不给操作,原样输出
map_rdd = rdd2.map(lambda x:x)
print('map_rdd = ', map_rdd.collect())
>>> new_rdd2 = ['a', 'b', 'd', 'c']
>>> map_rdd = [['a', 'b'], ['d', 'c']]4. flatMap 和 map 的区别
map:对集合中每个元素进行操作。
flatMap:对集合中每个元素进行操作然后再扁平化。
详细的解释: https://blog.csdn.net/WYpersist/article/details/80220211
5. notebook