【论文笔记】GRAPH ATTENTION NETWORKS
本文提出了一种新的在图结构网络中的神经网络结构GATs,利用掩蔽的自我注意层来解决先前基于图卷积或其近似的方法的缺点。通过堆叠层数来使节点可以从其邻居节点聚合特征,一大特点是GATs可以为不同的邻居节点分配不同权重,并且GATs不需要复杂的矩阵运算、不需要事先知道图结构(求拉普拉斯矩阵)
1、简介
CNNs已经成功应用在很多具有网格结构的数据的问题中,但是有很多任务的数据不能表示成网格结构,例如人际关系、电子商务等。现在已经有很多调查试图把神经网络应用在任意结构的图中,如何将RNNs应用于图结构,还有改进的将GRU应用于图结构。
与此同时,将卷积应用到图结构越来越热门。主要分为两种,一种频域方法,一种非频域方法。
attention机制已经在很多序列数据上变成了事实上的标准,它的一个好出是它可以应对不同大小的输入,同时关注最相关的部分以做出选择。
此文章介绍一个基于attention机制的图分类任务。基本想法是计算每个节点的隐藏表示。注意力架构有几个有趣的特性:
- 计算高效,因为可以在节点间平行化
- 它可以应用有不同度节点的图
- 这个模型可以直接应用在归纳学习(inductive learning)问题,即使问题包含模型没有见过的图
验证方法:使用了四个基准 Cora,Citeseer,Pubmed citation networks,protein-protein interaction datase
2、模型结构
2.1Graph Attention层
N为节点个数
F为每个节点的特征数量
输入:
![]()
使用矩阵变换得到
![]()
使用LeakyReLU做为激活函数
使用SoftMax计算最后的概率
最后得到两节点之间的相关性:

计算过程:
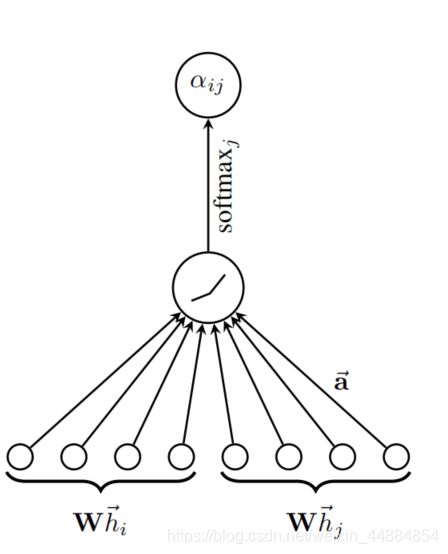
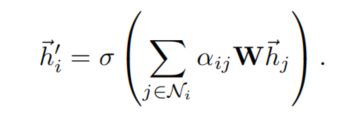
k代表多个注意力机制同时作用,此处为把多个concate在一起
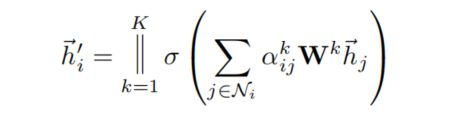
若注意力层为最后一层,就改成了平均:

总的来说就是:

2.2与相关工作的对比
解决了之前的一些问题:
1.计算高效
self-attentional layer可以在所有边上并行计算,输出特征的计算可以跨所有节点并行化。没有使用特征分解和矩阵操作。一个单独的GAT头计算F‘个特征可以写成![]()
的计算复杂度,F是输入特征,V和E分别是节点和边的数量。
2.与GCNs相比,此模型对节点的同一邻居节点分配不同的注意力。
3.attention机制对图中所有的边有相同的方法,它不依赖于对全局图结构或其所有节点的预先访问
4.此模型不会受到模型节点顺序的影响
5.GAT可以重新定义成MoNet的一个特定实例。但是我们的模型是使用节点特征进行相似计算,而不是使用节点的结构特性。
3评价
此部分对模型性能进行了分析。
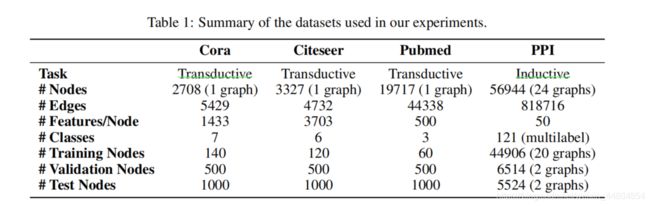
3.1数据集
直推式学习
三个数据集:Cora,Citeseer and Pubmed
在三个数据集中,节点对应文档而边对应引用,节点特征为文档中单词包的使用。每个节点一个类别。只使用一个类中的二十个节点训练,然而,该训练算法遵循传导机制,可以访问所有节点的特征向量。在1000个测试节点上对训练模型的预测能力进行了评估,使用500个额外的节点进行验证。
The Cora dataset contains 2708 nodes, 5429 edges, 7 classes and 1433 features per node. The Citesee dataset contains 3327 nodes, 4732 edges, 6 classes and 3703 features per node. The Pubmed datase contains 19717 nodes, 44338 edges, 3 classes and 500 features per node.
归纳式学习
使用 a protein-protein interaction (PPI)数据集。20个图用于训练,2个验证,2个测试,在训练过程中测试图没有被看到。为了构建图,使用了预训练数据。平均每个图2372个节点,每个节点50个特征,每个节点有121个label对应,节点可以同时拥有多个label。
3.2最先进的方法STATE-OF-THE-ART METHODS
直推式学习
对比了之前的一些直推式学习方法的模型结构
归纳式学习
对比了之前的一些归纳式学习方法的模型结构
3.3实验建立
直推式学习
模型使用了两层GAT层,结构超参数在Cora数据集中训练并在Citeseer数据集中重用了。第一层使用了8个注意力头对每个节点的8个特征使用,随后有ELU进行非线性变换。第二层用作分类,一个注意力头计算C个特征(C是分类的个数),最后有Softmax函数。在训练时,使用了L2 regularization(λ = 0.0005),dropout(p = 0.6 )应用在每层的输入。
对Pubmed训练需要对模型进行一点修改,第二层用8个注意力头并且,L2 regularization(λ = 0.001)
归纳式学习
使用三层GAT层,前两层都使用了4个注意力头计算256个特征(总共1024个特征),随后用ELU进行非线性变换,最后一层使用分类,6个注意力头计算121个特征,随后使用sigmoid激活函数。训练集足够大不需要使用L2 regularizaion或者dropout。然而我们成功把skip connection应用在了中间注意力层中。
两种模型都使用了Glorot初始化,使用Adam SGD优化器,lr=0.01在Pubmed中,lr=0.005在其他数据集。都是用了early stoppong在cross-entropy loss中,并且用acc和micro-F1进行标称,训练了100epochs。
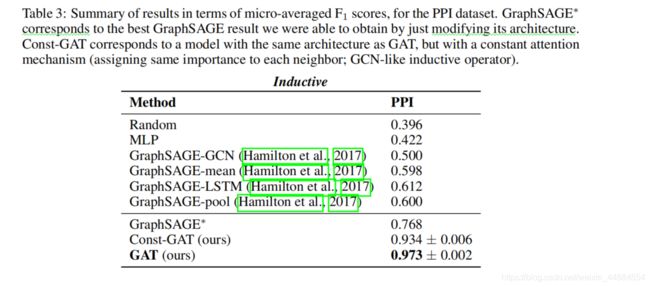
3.4结果
此处见图,取得了当时最好的效果

结论
优点:1.此模型计算高效(不需要复杂的矩阵运算,并且可以在全部节点并行化)
2.可以应对有不同数量邻居的问题,并且对同一节点在不同时候有不同的重要性分配
3.不需要事先知道整个的图结构。模型在四个模型的都取得了最先进的性能。
待解决的问题:
1.解决让batch size更大的问题
2.研究其可解释性
3.让它应用在图预测上而不是应用在节点预测上
4.将模型扩展到应用边缘特征(应为此模型并没有用到边的特征)来解决更多的问题