【python知识点】锦集
【版权声明】未经博主同意,谢绝转载!(请尊重原创,博主保留追究权)
https://blog.csdn.net/m0_69908381/article/details/132368704
出自【进步*于辰的博客】
如果大家想要了解python使用细节和经验,请查阅博文【python细节、经验】锦集。
注:本文可能不适合 0 python基础的博友,因为对于各类知识点,我阐述的宗旨是“阐明使用细节”,而不是基础知识。
文章目录
- 1、特殊指令符
-
- 1.1 `del xx`
- 2、特殊方法
- 3、关于列表(`list`)
-
- 3.1 切片示例
- 3.2 方法
- 4、关于元组(`tuple`)
- 5、关于字典(`map`)
-
- 5.1 概述
- 5.2 方法
- 6、关于集合(`set`)
-
- 6.1 概述
- 6.2 方法
- 7、关于变量
-
- 7.1 分类
- 7.2 可变参数
-
- 7.2.1 `*args`格式
- 7.2.2 `**args`格式
- 7.2.3 特殊用法
- 最后
1、特殊指令符
1.1 del xx
1、del list[索引] # 删除列表元素
2、del tuple # 删除整个元组
3、del map[key] # 删除字典映射
2、特殊方法
| 摘要 | 参数说明 | 返回值类型/返回值 | 说明 |
|---|---|---|---|
list(tuple t) |
列表 | 将元组转换成列表。注:不修改原元组 | |
range(int max) |
序列最大值 | 序列 | 此方法作用很多,此处的作用是指定一个最大值,返回0 ~ max - 1的序列,常用宇遍历 |
3、关于列表(list)
参考笔记二,P25.3~5。
3.1 切片示例
- 例:
list = [1, 2, 3, 4],则list[-3:] = [2, 3, 4]、list[:3] = [1, 2, 3],故:list[-3: 3] = [2, 3]。由于[2, 3] = [2, 3, 4] 并 [1, 2, 3],因此,list[-3: 3] = list[-3:] 并 list[:3]; - 例;
list[a: b: x],其中,a 是起始索引,b 是终止索引,x 是步长。若x > 0,则从左往右切片;否则,从右往左切片。
注:实际切片内容并不一定是按照[a, b)(即 a → b)或(b, a](即 b → a)规则进行切片。由于a/b/x三者都有“正负”2种情形,因此实际的切片情况很多,我暂且没有找到规律,因此只能按照示例1的“拆分”方法进行分析。
具体方法:
1、将 [a: b: x] 拆分d成 [a: : x] 和 [: b: x];
2、计算[a: : x]:a 为起始索引,若x > 0,则向右取所有;否则,向左取所有。得到:[list[a], ...];
3、计算[: b: x]:b 为终止索引,同理,得到:[..., list[b]];
4、结果:取两者交集.
3.2 方法
| 摘要 | 参数说明 | 返回值类型/返回值 | 说明 |
|---|---|---|---|
append(Object o) |
追加一个元素 | ||
extend(List it) |
追加列表 | ||
insert(int i, Object o) |
插入元素 | ||
pop(int i) |
返回被删除元素 | 删除元素。若不指定,则删除最后一个元素 | |
remove(Object o) |
移除匹配的第一个元素 | ||
index(Object o) |
索引 | 查找匹配的第一个元素。若找不到,则报错 | |
reverse() |
反转列表。相当于list[::-1] |
||
count(Object o) |
int | 计数 | |
sort() |
排序,默认升序。注:列表所有元素类型必须一致 |
注:
- 列表元素类型可混搭;
- 切片时,若索引超出范围,不报错。
4、关于元组(tuple)
参考笔记二,P33.1。
概述:
- 元组自创建后无法修改;
- 若元组只有一个元素,则末尾必须添加一个"
,",否则其类型就不是元组,而是此元素类型; - 元组无法修改,但基本支持列表拥有的查询系列方法,如:
count()、index(),故元组的查询效率高于列表(元组的作用之一)。
示例:
t = (2023)
print(type(t))
t = (2023,)
print(type(t))
print(t.count(2023))
print(t.index(2023))
打印结果:
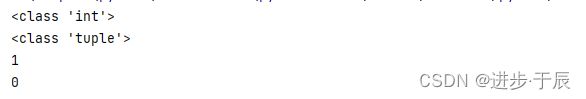
5、关于字典(map)
参考笔记二,P33.2。
5.1 概述
- 添加映射时,若 key 已存在,则覆盖 value;
- 用“
{}”表示空字典; - 访问不存在的 key 时,报错;
- 当为不存在的 key 赋值时,添加此映射;
示例:
m = {}
print(type(m)) # 打印:5.2 方法
1、clear():清空字典,无返回值。
2、copy():复制字典,属“浅复制”。
3、fromkeys(a, b):创建字典。
注:a 是序列,b 是默认值(可不指定)。
示例:
m = {} # 空字典
l = [2, 0, 2, 3]
m = m.fromkeys(l) # 使用列表构建字典
print(m)
m = m.fromkeys(l, 0) # 指定所有映射的 value 为 0,即默认值
print(m)
t = (2023,)
m = m.fromkeys(t) # 使用元组构建字典
print(m)
s = set([2, 0, 2, 3])
m = m.fromkeys(s) # 使用集合构建字典
print(m)
打印结果:
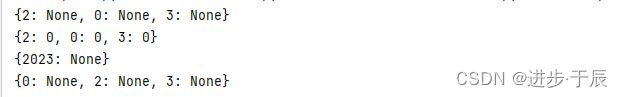
4、get(a, b):获取 value。
注:a 是 key,b 是默认值(当 key 不存在时作为返回值,可不指定)。若 key 不存在,则返回None。
5:keys():返回包含字典所有 key 的“列表”。
注:表面上看是列表,实则不是,用type()即可验证,在某些情况下类似列表。此方法常用于判断字典是否包含某个 key。
6:values():返回包含字典所有 value 的“列表”。
7、items():类似java中的map.entrySet(),常用宇遍历字典。
6、关于集合(set)
参考笔记二,P33.3。
6.1 概述
- 无重复值;
- 定义集合必须使用
set()方法; - 构造有元素集合时,可以使用任意序列;
- 集合不能使用“
*”或“连接”; - 集合常用宇数字意义上的集合操作,如:交集
&、并集|、对称差集^,列表则不行。
示例:
s = set()
print(s)
print(type(s))
s1 = set((2, 0, 2, 3))
print(s1)
s2 = set(['c', 's', 'd', 'n'])
print(s2)
s3 = s1 & s2 # 返回两集合相同元素的集合
print(s3)
s3 = s1 | s2 # 返回两集合所有元素合集(若有相同元素,仅保留一个)
print(s3)
s3 = s1 - s2 # 等同于 s1 - (s1 & s2),即:返回s1去除s1与s2相同元素后的集合
print(s3)
s3 = s1 ^ s2 # 等同于 (s1 - s2) | (s2 - s1)
print(s3)
打印结果:

6.2 方法
| 摘要 | 参数说明 | 返回值类型/返回值 | 说明 |
|---|---|---|---|
add(Object o) |
追加元素 | ||
remove(Object o) |
移除元素。若元素不存在,报错 |
7、关于变量
参考笔记二,P34.8。
7.1 分类
- 必须参数:指方法调用时必须指定的参数;(其实就如 java 中的实参,要求个数、类型对应)
- 关键字参数:指方法调用时通过
形参名=值的方式指定实参,故可忽略实参顺序; - 默认参数:指方法定义时已指定默认值的参数,且必须定义在最后;(调用时可不指定)
- 可变参数:指不能在定义方法时确认参数的个数和内容(类型)所使用的参数;
- 组合参数。
7.2 可变参数
7.2.1 *args格式
接收“序列”,相当于 java 中的可变参数,args的类型是“元组”。
示例:
def show(*args):
for e in args:
print(e)
# 如 java 中的”xx...“,会将一组数自动封装成数组,在此处是序列
show(2023, 'csdn')
# java 中的可变参数也可这样定义实参,不过不允许直接这样初始化(也有点多此一举)
# 而在此处,尽管 [2023, 'csdn'] 是一个序列,但 args 仅将其视为一个元素,因此无法遍历(直接打印出“[2023, 'csdn']”)
show([2023, 'csdn'])
# (2023, ), ('csdn',)是两个元组,最后,args 会封装成 ((2023, ), ('csdn',))
show((2023, ), ('csdn',))
打印结果:

改进:(为调用show([2023, 'csdn'])时,能遍历其内元素)
def show(*args):
for e in args:
if isinstance(e, list):
for i in e:
print(i)
else:
print(e)
打印结果:

7.2.2 **args格式
表示“字典”(固定),实参必须是关键字参数(也可是字典,但需要使用**标识,往下看)。
示例:
def show(**args):
# 因为 args 固定为字典,因此可调用成员方法 items()
for k,v in args.items():
print(k, v)
show(year=2023, flag='csdn')
打印结果:

7.2.3 特殊用法
(我暂且不知如何描述,看示例)
1、上述*args的示例也可这样改:
l = [2023, 'csdn']
show(*l)
即指明其是一个列表,这样*args就不会将其视为一个元素。
2、**args的实参可使用字典,上述**args的示例可这样改:
m = {
'year': 2023,
'flag': "csdn"
}
show(**m)
即指明其是一个字典。
最后
本文中的举例是为了方便大家理解、以及阐述相关知识点而简单举出的,不一定有实用性,也不一定有针对性,比如:集合运算&,目的是获取两集合相同元素,而第6.1项的示例中我没有刻意去定义s1、s2包含了相同元素。我之所以如此:
- 这些细节很简单,大家在其他编程语言或课程、书本上肯定或多或少接触过或完全知道,因此没必要特意举例;
- 本文阐述的宗旨是“阐明使用细节”,而对于其他附属知识并不一定会细致说明。
因此,一些细节需要大家自行测试或查找资料。
本文持续更新中。。。